FeatureEnVi: Visual Analytics for Feature Engineering Using Stepwise Selection and Semi-Automatic Extraction Approaches
2103.14539
0
0
✨
Abstract
The machine learning (ML) life cycle involves a series of iterative steps, from the effective gathering and preparation of the data, including complex feature engineering processes, to the presentation and improvement of results, with various algorithms to choose from in every step. Feature engineering in particular can be very beneficial for ML, leading to numerous improvements such as boosting the predictive results, decreasing computational times, reducing excessive noise, and increasing the transparency behind the decisions taken during the training. Despite that, while several visual analytics tools exist to monitor and control the different stages of the ML life cycle (especially those related to data and algorithms), feature engineering support remains inadequate. In this paper, we present FeatureEnVi, a visual analytics system specifically designed to assist with the feature engineering process. Our proposed system helps users to choose the most important feature, to transform the original features into powerful alternatives, and to experiment with different feature generation combinations. Additionally, data space slicing allows users to explore the impact of features on both local and global scales. FeatureEnVi utilizes multiple automatic feature selection techniques; furthermore, it visually guides users with statistical evidence about the influence of each feature (or subsets of features). The final outcome is the extraction of heavily engineered features, evaluated by multiple validation metrics. The usefulness and applicability of FeatureEnVi are demonstrated with two use cases and a case study. We also report feedback from interviews with two ML experts and a visualization researcher who assessed the effectiveness of our system.
Create account to get full access
Overview
- The paper discusses a visual analytics system called FeatureEnVi that helps with the feature engineering process in machine learning (ML) life cycle.
- Feature engineering can significantly improve the performance of ML models, but existing tools for this task are inadequate.
- FeatureEnVi allows users to choose important features, transform them, and experiment with different feature generation combinations.
- The system utilizes automatic feature selection techniques and provides visual guidance on the influence of each feature or feature subset.
- The effectiveness of FeatureEnVi is demonstrated through two use cases and a case study, as well as feedback from ML experts and a visualization researcher.
Plain English Explanation
Machine learning (ML) is a powerful tool that can be used to make predictions and decisions based on data. However, the process of getting an ML model to work well can be quite complex, involving a series of steps.
One important step in this process is feature engineering. This is the process of taking the raw data and transforming it into a form that is more useful for the ML model. For example, if the data includes information about a person's age, you might want to create additional features like "is the person a child, adult, or senior?" or "how many years until the person reaches retirement age?" These kinds of transformations can significantly improve the performance of the ML model.
Despite the importance of feature engineering, the tools available to support this task have been lacking. That's where FeatureEnVi comes in. FeatureEnVi is a visual analytics system that is specifically designed to help with feature engineering. It allows users to explore the impact of different features on the performance of the ML model, both on a local and global scale. The system also provides guidance on which features are the most important and suggests ways to transform the features to make them more useful.
By using FeatureEnVi, ML practitioners can more easily identify and create the best set of features for their particular problem, leading to more accurate and reliable ML models. This can have a big impact in real-world applications like wildfire prediction.
Technical Explanation
The paper presents FeatureEnVi, a visual analytics system designed to assist with the feature engineering process in the machine learning (ML) life cycle. Feature engineering is a crucial step that can significantly improve the performance of ML models, but existing tools for this task are often inadequate.
FeatureEnVi provides several key capabilities to support feature engineering:
- Feature Selection: The system utilizes multiple automatic feature selection techniques to help users identify the most important features for their ML task.
- Feature Transformation: FeatureEnVi allows users to transform original features into new, more powerful alternatives through various data manipulation techniques.
- Feature Experimentation: Users can experiment with different combinations of feature generation to find the optimal set for their problem.
- Data Space Exploration: The system enables users to explore the impact of features on both local and global scales, providing visual guidance on the influence of each feature or subset of features.
The effectiveness of FeatureEnVi is demonstrated through two use cases and a case study, as well as feedback from interviews with two ML experts and a visualization researcher. The experts highlighted the usefulness of the system's visual analytics capabilities in supporting hyperparameter search and extracting meaningful decision rules from the feature engineering process.
Critical Analysis
The paper provides a comprehensive overview of FeatureEnVi and its capabilities in supporting the feature engineering process for machine learning. However, the authors do acknowledge some limitations of the system:
- The current implementation of FeatureEnVi is primarily focused on tabular data, and it may not be as effective for other data types, such as images or text.
- The system relies on a limited set of automatic feature selection techniques, and users may want to incorporate additional methods or custom algorithms to suit their specific needs.
- The evaluation of FeatureEnVi was conducted with a relatively small number of participants, and a larger-scale user study could provide more insights into the system's usability and effectiveness in real-world settings.
Additionally, the paper does not address potential issues related to the interpretability and explainability of the features generated by FeatureEnVi. As machine learning models become more complex, it is increasingly important to understand the reasoning behind the decisions they make, and feature engineering can play a crucial role in this regard.
Conclusion
The FeatureEnVi visual analytics system presents a promising approach to addressing the challenge of feature engineering in the machine learning life cycle. By providing a set of tools for feature selection, transformation, and experimentation, the system can help ML practitioners more easily identify and create the most effective features for their specific problems.
The successful demonstrations and positive feedback from expert users suggest that FeatureEnVi can have a significant impact on improving the performance and reliability of machine learning models, especially in domains where feature engineering is crucial, such as wildfire prediction. As the field of machine learning continues to evolve, tools like FeatureEnVi will become increasingly important in helping researchers and practitioners navigate the complexities of the ML life cycle and unlock the full potential of this powerful technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Towards Feature Engineering with Human and AI's Knowledge: Understanding Data Science Practitioners' Perceptions in Human&AI-Assisted Feature Engineering Design
Qian Zhu, Dakuo Wang, Shuai Ma, April Yi Wang, Zixin Chen, Udayan Khurana, Xiaojuan Ma
0
0
As AI technology continues to advance, the importance of human-AI collaboration becomes increasingly evident, with numerous studies exploring its potential in various fields. One vital field is data science, including feature engineering (FE), where both human ingenuity and AI capabilities play pivotal roles. Despite the existence of AI-generated recommendations for FE, there remains a limited understanding of how to effectively integrate and utilize humans' and AI's knowledge. To address this gap, we design a readily-usable prototype, human&AI-assisted FE in Jupyter notebooks. It harnesses the strengths of humans and AI to provide feature suggestions to users, seamlessly integrating these recommendations into practical workflows. Using the prototype as a research probe, we conducted an exploratory study to gain valuable insights into data science practitioners' perceptions, usage patterns, and their potential needs when presented with feature suggestions from both humans and AI. Through qualitative analysis, we discovered that the Creator of the feature (i.e., AI or human) significantly influences users' feature selection, and the semantic clarity of the suggested feature greatly impacts its adoption rate. Furthermore, our findings indicate that users perceive both differences and complementarity between features generated by humans and those generated by AI. Lastly, based on our study results, we derived a set of design recommendations for future human&AI FE design. Our findings show the collaborative potential between humans and AI in the field of FE.
5/24/2024

Leveraging Knowlegde Graphs for Interpretable Feature Generation
Mohamed Bouadi, Arta Alavi, Salima Benbernou, Mourad Ouziri
0
0
The quality of Machine Learning (ML) models strongly depends on the input data, as such Feature Engineering (FE) is often required in ML. In addition, with the proliferation of ML-powered systems, especially in critical contexts, the need for interpretability and explainability becomes increasingly important. Since manual FE is time-consuming and requires case specific knowledge, we propose KRAFT, an AutoFE framework that leverages a knowledge graph to guide the generation of interpretable features. Our hybrid AI approach combines a neural generator to transform raw features through a series of transformations and a knowledge-based reasoner to evaluate features interpretability using Description Logics (DL). The generator is trained through Deep Reinforcement Learning (DRL) to maximize the prediction accuracy and the interpretability of the generated features. Extensive experiments on real datasets demonstrate that KRAFT significantly improves accuracy while ensuring a high level of interpretability.
6/4/2024
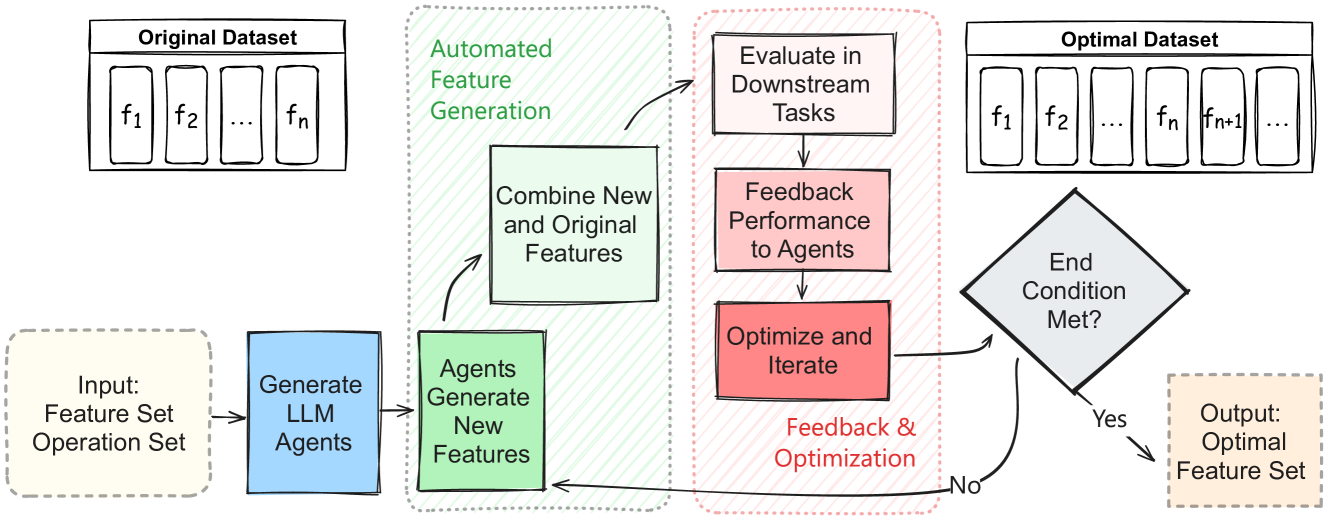
Dynamic and Adaptive Feature Generation with LLM
Xinhao Zhang, Jinghan Zhang, Banafsheh Rekabdar, Yuanchun Zhou, Pengfei Wang, Kunpeng Liu
0
0
The representation of feature space is a crucial environment where data points get vectorized and embedded for upcoming modeling. Thus the efficacy of machine learning (ML) algorithms is closely related to the quality of feature engineering. As one of the most important techniques, feature generation transforms raw data into an optimized feature space conducive to model training and further refines the space. Despite the advancements in automated feature engineering and feature generation, current methodologies often suffer from three fundamental issues: lack of explainability, limited applicability, and inflexible strategy. These shortcomings frequently hinder and limit the deployment of ML models across varied scenarios. Our research introduces a novel approach adopting large language models (LLMs) and feature-generating prompts to address these challenges. We propose a dynamic and adaptive feature generation method that enhances the interpretability of the feature generation process. Our approach broadens the applicability across various data types and tasks and draws advantages over strategic flexibility. A broad range of experiments showcases that our approach is significantly superior to existing methods.
6/7/2024

Fiper: a Visual-based Explanation Combining Rules and Feature Importance
Eleonora Cappuccio, Daniele Fadda, Rosa Lanzilotti, Salvatore Rinzivillo
0
0
Artificial Intelligence algorithms have now become pervasive in multiple high-stakes domains. However, their internal logic can be obscure to humans. Explainable Artificial Intelligence aims to design tools and techniques to illustrate the predictions of the so-called black-box algorithms. The Human-Computer Interaction community has long stressed the need for a more user-centered approach to Explainable AI. This approach can benefit from research in user interface, user experience, and visual analytics. This paper proposes a visual-based method to illustrate rules paired with feature importance. A user study with 15 participants was conducted comparing our visual method with the original output of the algorithm and textual representation to test its effectiveness with users.
4/29/2024