FedAuxHMTL: Federated Auxiliary Hard-Parameter Sharing Multi-Task Learning for Network Edge Traffic Classification
2404.08028
0
0
Abstract
Federated Learning (FL) has garnered significant interest recently due to its potential as an effective solution for tackling many challenges in diverse application scenarios, for example, data privacy in network edge traffic classification. Despite its recognized advantages, FL encounters obstacles linked to statistical data heterogeneity and labeled data scarcity during the training of single-task models for machine learning-based traffic classification, leading to hindered learning performance. In response to these challenges, adopting a hard-parameter sharing multi-task learning model with auxiliary tasks proves to be a suitable approach. Such a model has the capability to reduce communication and computation costs, navigate statistical complexities inherent in FL contexts, and overcome labeled data scarcity by leveraging knowledge derived from interconnected auxiliary tasks. This paper introduces a new framework for federated auxiliary hard-parameter sharing multi-task learning, namely, FedAuxHMTL. The introduced framework incorporates model parameter exchanges between edge server and base stations, enabling base stations from distributed areas to participate in the FedAuxHMTL process and enhance the learning performance of the main task-network edge traffic classification. Empirical experiments are conducted to validate and demonstrate the FedAuxHMTL's effectiveness in terms of accuracy, total global loss, communication costs, computing time, and energy consumption compared to its counterparts.
Create account to get full access
Overview
- Explores a federated multi-task learning approach for network edge traffic classification
- Proposes a novel "FedAuxHMTL" method that leverages auxiliary hard-parameter sharing
- Aims to improve edge computing performance and energy efficiency
Plain English Explanation
The paper investigates a technique called "federated multi-task learning" to improve the classification of network traffic at the edge of computing systems. This is an important problem because accurately identifying different types of network traffic can help optimize the performance and energy use of edge devices like routers and sensors.
The researchers developed a new method called "FedAuxHMTL" that builds on the idea of "federated learning" - where a shared machine learning model is trained across multiple devices without sharing their raw data. FedAuxHMTL adds an "auxiliary" component that helps the model learn common features across related tasks, like distinguishing between different types of web traffic and video streams. This "hard-parameter sharing" approach allows the model to be more efficient and effective compared to training separate models for each task.
By using this federated multi-task learning technique, the goal is to create a system that can accurately classify network traffic on edge devices, while consuming less computational power and energy than previous approaches. This could lead to better performance and battery life for Internet of Things (IoT) devices and other edge computing systems.
Technical Explanation
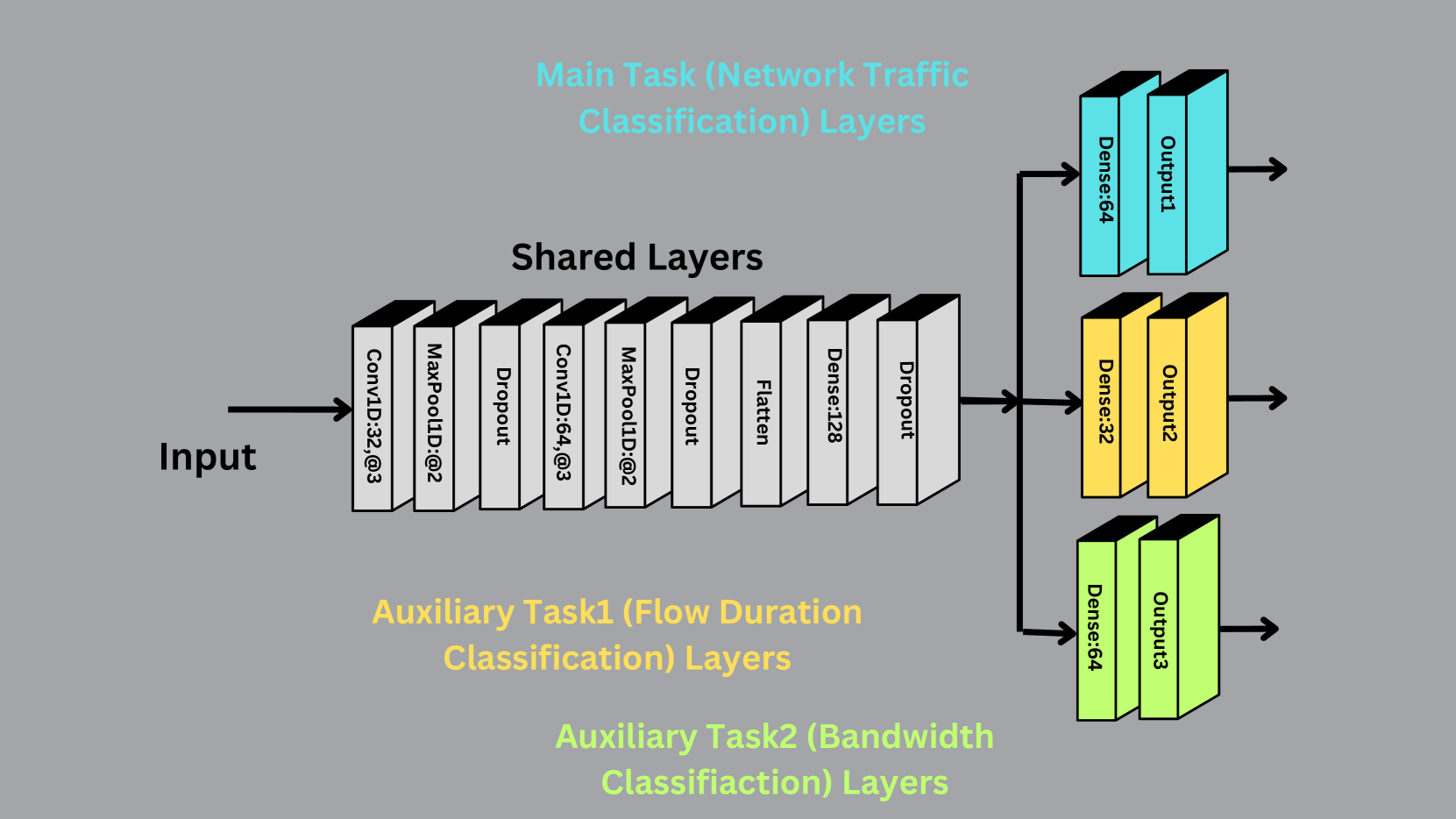
The paper presents a novel federated multi-task learning approach called "FedAuxHMTL" for network edge traffic classification. Federated learning (Conquering Communication Constraints to Enable Large-Scale Edge ML) allows a shared model to be trained across multiple edge devices without sharing their raw data, which is important for privacy and scalability.
FedAuxHMTL builds on this by incorporating an "auxiliary" hard-parameter sharing component (Enhancing Efficiency of Multi-Device Federated Learning through Data Adaptive Client Selection). This means the model learns a set of shared "backbone" features that are useful across multiple traffic classification tasks, such as differentiating web traffic, video streams, and other network flows. The auxiliary component helps the model discover these common patterns more efficiently compared to training separate models for each task.
The researchers evaluate FedAuxHMTL on a real-world network traffic dataset, comparing its performance to federated single-task learning and other baselines. Their results show FedAuxHMTL can achieve higher accuracy, while also reducing the computational and energy requirements on edge devices (Adaptive Federated Learning via a New Entropy Approach). This makes it a promising technique for improving the efficiency of edge computing systems that need to classify network traffic in real-time.
Critical Analysis
The paper provides a well-designed evaluation of the FedAuxHMTL approach, including comparisons to relevant baselines and analysis of the method's tradeoffs. However, the authors acknowledge several limitations that could be addressed in future work.
One key limitation is that the experiments were conducted on a single dataset, so further testing is needed to validate the generalizability of the findings (FEDAC: Adaptive Clustered Federated Learning Framework for Heterogeneous Edge Devices). Additionally, the paper does not explore the impact of client heterogeneity or non-IID data distributions, which are known challenges in federated learning (AdaptiveFL: Adaptive Heterogeneous Federated Learning for Resource-Constrained Edge Devices).
Further research could also investigate the scalability of FedAuxHMTL to larger numbers of edge devices and tasks, as well as its resilience to communication failures or device dropouts during training. Exploring techniques to further reduce the computational and energy footprint on edge devices would also be valuable.
Overall, the FedAuxHMTL method represents an interesting advance in federated multi-task learning for edge computing applications. With further validation and refinement, it could become a useful tool for optimizing the performance and efficiency of network traffic classification at the edge.
Conclusion
This paper presents a novel federated multi-task learning approach called FedAuxHMTL, which leverages auxiliary hard-parameter sharing to improve the performance and efficiency of network edge traffic classification. By learning shared features across related tasks, the method can achieve higher accuracy while reducing the computational and energy requirements on edge devices.
The results demonstrate the potential of federated multi-task learning techniques to enhance edge computing applications. Further research is needed to explore the generalizability, scalability, and robustness of FedAuxHMTL, as well as opportunities to further optimize its resource footprint. Overall, this work represents an important step towards more efficient and effective edge-based traffic classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Non-Federated Multi-Task Split Learning for Heterogeneous Sources
Yilin Zheng, Atilla Eryilmaz
0
0
With the development of edge networks and mobile computing, the need to serve heterogeneous data sources at the network edge requires the design of new distributed machine learning mechanisms. As a prevalent approach, Federated Learning (FL) employs parameter-sharing and gradient-averaging between clients and a server. Despite its many favorable qualities, such as convergence and data-privacy guarantees, it is well-known that classic FL fails to address the challenge of data heterogeneity and computation heterogeneity across clients. Most existing works that aim to accommodate such sources of heterogeneity stay within the FL operation paradigm, with modifications to overcome the negative effect of heterogeneous data. In this work, as an alternative paradigm, we propose a Multi-Task Split Learning (MTSL) framework, which combines the advantages of Split Learning (SL) with the flexibility of distributed network architectures. In contrast to the FL counterpart, in this paradigm, heterogeneity is not an obstacle to overcome, but a useful property to take advantage of. As such, this work aims to introduce a new architecture and methodology to perform multi-task learning for heterogeneous data sources efficiently, with the hope of encouraging the community to further explore the potential advantages we reveal. To support this promise, we first show through theoretical analysis that MTSL can achieve fast convergence by tuning the learning rate of the server and clients. Then, we compare the performance of MTSL with existing multi-task FL methods numerically on several image classification datasets to show that MTSL has advantages over FL in training speed, communication cost, and robustness to heterogeneous data.
6/4/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024

Federated Model Heterogeneous Matryoshka Representation Learning
Liping Yi, Han Yu, Chao Ren, Gang Wang, Xiaoguang Liu, Xiaoxiao Li
0
0
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion. However, existing MHeteroFL methods rely on training loss to transfer knowledge between the client model and the server model, resulting in limited knowledge exchange. To address this limitation, we propose the Federated model heterogeneous Matryoshka Representation Learning (FedMRL) approach for supervised learning tasks. It adds an auxiliary small homogeneous model shared by clients with heterogeneous local models. (1) The generalized and personalized representations extracted by the two models' feature extractors are fused by a personalized lightweight representation projector. This step enables representation fusion to adapt to local data distribution. (2) The fused representation is then used to construct Matryoshka representations with multi-dimensional and multi-granular embedded representations learned by the global homogeneous model header and the local heterogeneous model header. This step facilitates multi-perspective representation learning and improves model learning capability. Theoretical analysis shows that FedMRL achieves a $O(1/T)$ non-convex convergence rate. Extensive experiments on benchmark datasets demonstrate its superior model accuracy with low communication and computational costs compared to seven state-of-the-art baselines. It achieves up to 8.48% and 24.94% accuracy improvement compared with the state-of-the-art and the best same-category baseline, respectively.
6/4/2024
FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity
Zhaobin Sun (School of Electronic Information and Communications, Huazhong University of Science and Technology), Nannan Wu (School of Electronic Information and Communications, Huazhong University of Science and Technology), Junjie Shi (School of Electronic Information and Communications, Huazhong University of Science and Technology), Li Yu (School of Electronic Information and Communications, Huazhong University of Science and Technology), Xin Yang (School of Electronic Information and Communications, Huazhong University of Science and Technology), Kwang-Ting Cheng (School of Engineering, Hong Kong University of Science and Technology), Zengqiang Yan (School of Electronic Information and Communications, Huazhong University of Science and Technology)
0
0
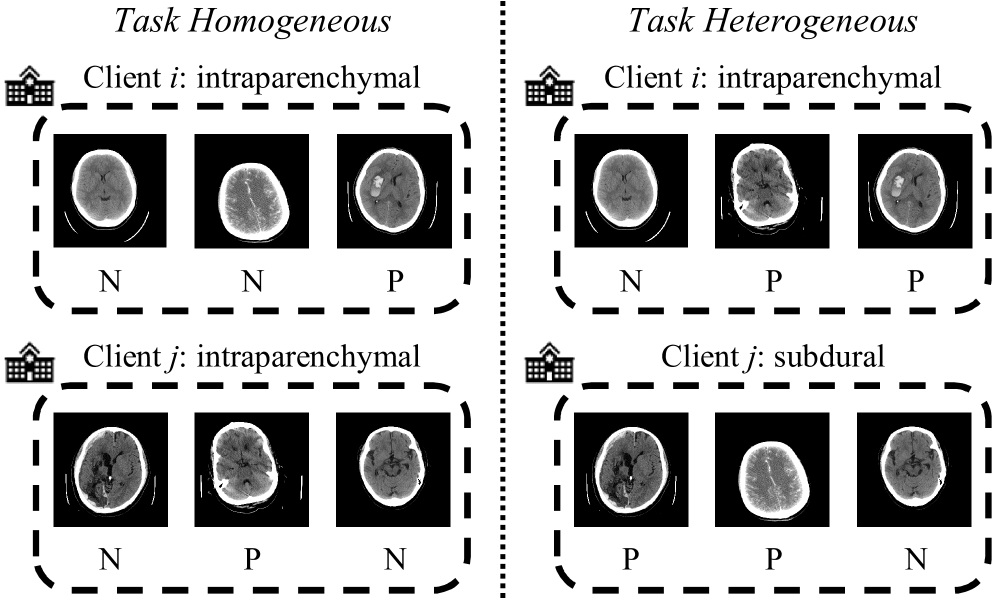
Cross-silo federated learning (FL) enables decentralized organizations to collaboratively train models while preserving data privacy and has made significant progress in medical image classification. One common assumption is task homogeneity where each client has access to all classes during training. However, in clinical practice, given a multi-label classification task, constrained by the level of medical knowledge and the prevalence of diseases, each institution may diagnose only partial categories, resulting in task heterogeneity. How to pursue effective multi-label medical image classification under task heterogeneity is under-explored. In this paper, we first formulate such a realistic label missing setting in the multi-label FL domain and propose a two-stage method FedMLP to combat class missing from two aspects: pseudo label tagging and global knowledge learning. The former utilizes a warmed-up model to generate class prototypes and select samples with high confidence to supplement missing labels, while the latter uses a global model as a teacher for consistency regularization to prevent forgetting missing class knowledge. Experiments on two publicly-available medical datasets validate the superiority of FedMLP against the state-of-the-art both federated semi-supervised and noisy label learning approaches under task heterogeneity. Code is available at https://github.com/szbonaldo/FedMLP.
6/28/2024