FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning

0
Sign in to get full access
Overview
- Introduces a new approach called FedSSA (Federated Semantic Similarity-based Aggregation) for personalized federated learning in model-heterogeneous settings
- Focuses on improving the efficiency and performance of federated learning when clients have diverse and heterogeneous model architectures
- Leverages semantic similarity between model parameters to enable effective aggregation across heterogeneous models
Plain English Explanation
Federated learning is a way for multiple devices or clients to collaboratively train a machine learning model without sharing their raw data. This is useful when data is distributed across many locations and can't be easily combined. However, federated learning can be challenging when the devices have very different machine learning models.
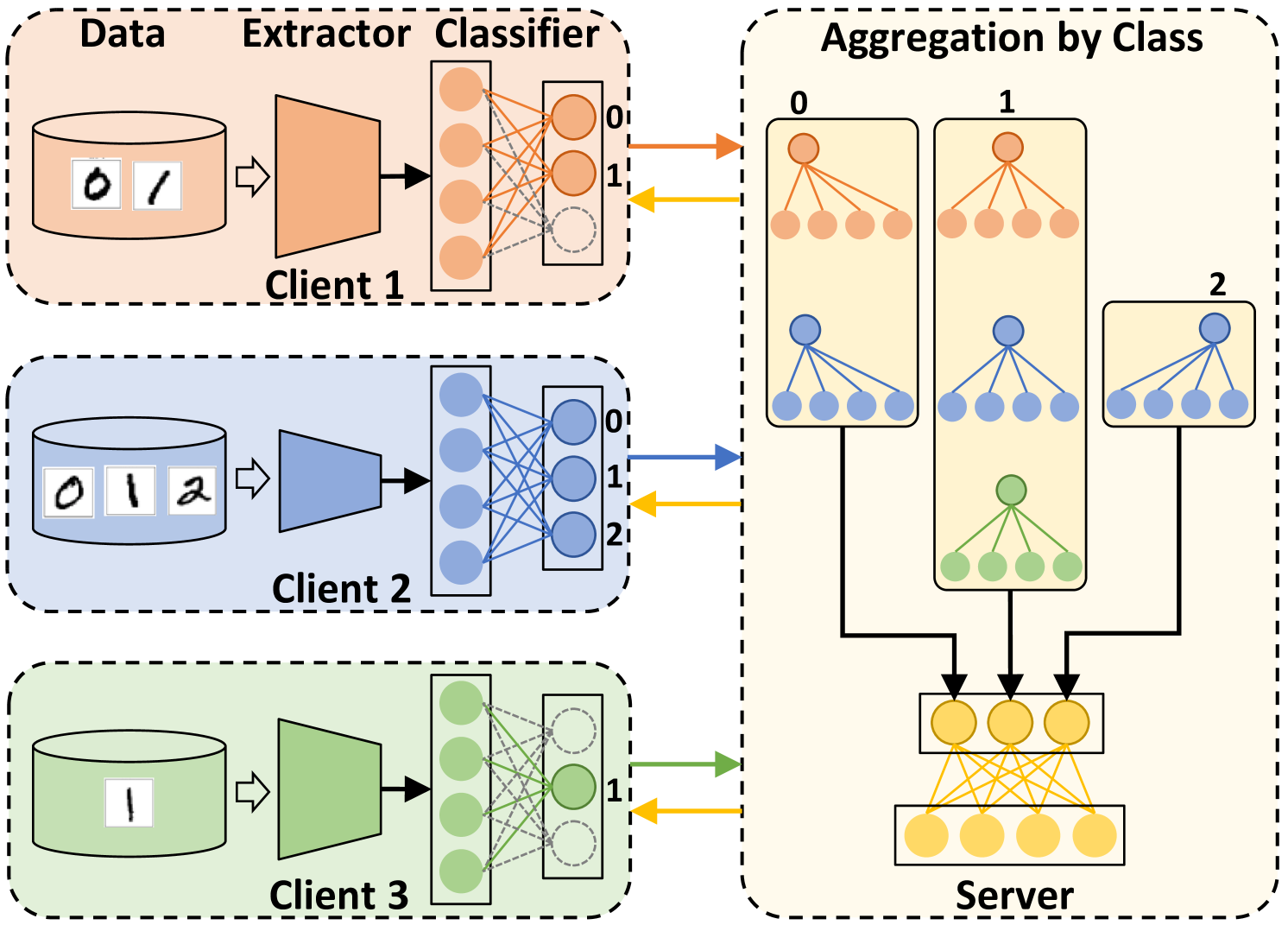
The FedSSA approach addresses this by using the
The key insight is that even if the model structures don't match, the actual learned representations may still be similar in meaning. FedSSA leverages this to combine the updates in a way that preserves the valuable information from each client, leading to faster convergence and better overall model performance.
Technical Explanation
The FedSSA approach works by first
During the federated learning process, each client computes their model updates and sends them to the server. The server then uses the semantic embeddings to
The aggregated update is then sent back to the clients, who apply it to their local models. This process repeats over multiple rounds, with the semantic alignment helping to overcome the challenges of model heterogeneity and leading to faster convergence.
Critical Analysis
The FedSSA approach represents an interesting and promising solution for improving the efficiency of federated learning in heterogeneous settings. By leveraging semantic similarity, it can better handle the challenges of diverse model architectures across clients.
However, the paper does not address potential issues around the scalability of the semantic embedding and alignment process, especially as the number of clients and model complexity increases. There may also be concerns around the computational and communication overhead required to perform the semantic matching.
Additionally, the paper does not explore the robustness of FedSSA to situations where the semantic similarity of model parameters may not align well with the actual task performance. In such cases, the semantic-based aggregation could potentially lead to suboptimal results.
Further research and experimentation would be needed to fully understand the limitations and tradeoffs of the FedSSA approach, as well as its performance compared to other federated learning techniques like FedMES or FedAC.
Conclusion
The FedSSA approach introduced in this paper represents an important step forward in addressing the challenges of model heterogeneity in federated learning. By leveraging semantic similarity, it enables more effective aggregation of model updates across diverse client architectures, leading to faster convergence and better overall performance.
While the paper raises some open questions and potential limitations, the core idea of using semantic alignment to overcome model heterogeneity is a valuable contribution to the field of federated learning. Further research and refinement of the FedSSA approach could lead to significant improvements in the practical deployment of federated learning systems, particularly in scenarios with diverse and distributed data sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning
Liping Yi, Han Yu, Zhuan Shi, Gang Wang, Xiaoguang Liu, Lizhen Cui, Xiaoxiao Li
Federated learning (FL) is a privacy-preserving collaboratively machine learning paradigm. Traditional FL requires all data owners (a.k.a. FL clients) to train the same local model. This design is not well-suited for scenarios involving data and/or system heterogeneity. Model-Heterogeneous Personalized FL (MHPFL) has emerged to address this challenge. Existing MHPFL approaches often rely on a public dataset with the same nature as the learning task, or incur high computation and communication costs. To address these limitations, we propose the Federated Semantic Similarity Aggregation (FedSSA) approach for supervised classification tasks, which splits each client's model into a heterogeneous (structure-different) feature extractor and a homogeneous (structure-same) classification header. It performs local-to-global knowledge transfer via semantic similarity-based header parameter aggregation. In addition, global-to-local knowledge transfer is achieved via an adaptive parameter stabilization strategy which fuses the seen-class parameters of historical local headers with that of the latest global header for each client. FedSSA does not rely on public datasets, while only requiring partial header parameter transmission to save costs. Theoretical analysis proves the convergence of FedSSA. Extensive experiments present that FedSSA achieves up to 3.62% higher accuracy, 15.54 times higher communication efficiency, and 15.52 times higher computational efficiency compared to 7 state-of-the-art MHPFL baselines.
Read more4/22/2024

0
FedTSA: A Cluster-based Two-Stage Aggregation Method for Model-heterogeneous Federated Learning
Boyu Fan, Chenrui Wu, Xiang Su, Pan Hui
Despite extensive research into data heterogeneity in federated learning (FL), system heterogeneity remains a significant yet often overlooked challenge. Traditional FL approaches typically assume homogeneous hardware resources across FL clients, implying that clients can train a global model within a comparable time frame. However, in practical FL systems, clients often have heterogeneous resources, which impacts their training capacity. This discrepancy underscores the importance of exploring model-heterogeneous FL, a paradigm allowing clients to train different models based on their resource capabilities. To address this challenge, we introduce FedTSA, a cluster-based two-stage aggregation method tailored for system heterogeneity in FL. FedTSA begins by clustering clients based on their capabilities, then performs a two-stage aggregation: conventional weight averaging for homogeneous models in Stage 1, and deep mutual learning with a diffusion model for aggregating heterogeneous models in Stage 2. Extensive experiments demonstrate that FedTSA not only outperforms the baselines but also explores various factors influencing model performance, validating FedTSA as a promising approach for model-heterogeneous FL.
Read more7/16/2024

0
Algorithms for Collaborative Machine Learning under Statistical Heterogeneity
Seok-Ju Hahn
Learning from distributed data without accessing them is undoubtedly a challenging and non-trivial task. Nevertheless, the necessity for distributed training of a statistical model has been increasing, due to the privacy concerns of local data owners and the cost in centralizing the massively distributed data. Federated learning (FL) is currently the de facto standard of training a machine learning model across heterogeneous data owners, without leaving the raw data out of local silos. Nevertheless, several challenges must be addressed in order for FL to be more practical in reality. Among these challenges, the statistical heterogeneity problem is the most significant and requires immediate attention. From the main objective of FL, three major factors can be considered as starting points -- textit{parameter}, textit{mixing coefficient}, and textit{local data distributions}. In alignment with the components, this dissertation is organized into three parts. In Chapter II, a novel personalization method, texttt{SuPerFed}, inspired by the mode-connectivity is introduced. In Chapter III, an adaptive decision-making algorithm, texttt{AAggFF}, is introduced for inducing uniform performance distributions in participating clients, which is realized by online convex optimization framework. Finally, in Chapter IV, a collaborative synthetic data generation method, texttt{FedEvg}, is introduced, leveraging the flexibility and compositionality of an energy-based modeling approach. Taken together, all of these approaches provide practical solutions to mitigate the statistical heterogeneity problem in data-decentralized settings, paving the way for distributed systems and applications using collaborative machine learning methods.
Read more8/2/2024

0
SCALE: Self-regulated Clustered federAted LEarning in a Homogeneous Environment
Sai Puppala, Ismail Hossain, Md Jahangir Alam, Sajedul Talukder, Zahidur Talukder, Syed Bahauddin
Federated Learning (FL) has emerged as a transformative approach for enabling distributed machine learning while preserving user privacy, yet it faces challenges like communication inefficiencies and reliance on centralized infrastructures, leading to increased latency and costs. This paper presents a novel FL methodology that overcomes these limitations by eliminating the dependency on edge servers, employing a server-assisted Proximity Evaluation for dynamic cluster formation based on data similarity, performance indices, and geographical proximity. Our integrated approach enhances operational efficiency and scalability through a Hybrid Decentralized Aggregation Protocol, which merges local model training with peer-to-peer weight exchange and a centralized final aggregation managed by a dynamically elected driver node, significantly curtailing global communication overhead. Additionally, the methodology includes Decentralized Driver Selection, Check-pointing to reduce network traffic, and a Health Status Verification Mechanism for system robustness. Validated using the breast cancer dataset, our architecture not only demonstrates a nearly tenfold reduction in communication overhead but also shows remarkable improvements in reducing training latency and energy consumption while maintaining high learning performance, offering a scalable, efficient, and privacy-preserving solution for the future of federated learning ecosystems.
Read more7/29/2024