FedTSA: A Cluster-based Two-Stage Aggregation Method for Model-heterogeneous Federated Learning

0

Sign in to get full access
Overview
- This research paper proposes a new federated learning approach called FedTSA (Federated Two-Stage Aggregation) to address model heterogeneity among participating clients.
- FedTSA uses a two-stage aggregation process, first clustering client models based on their similarities, and then aggregating the models within each cluster to obtain a global model.
- The authors claim this approach can improve the performance of federated learning in the presence of model heterogeneity, where clients have different data distributions and model architectures.
Plain English Explanation
In federated learning, multiple devices or clients (e.g., smartphones, IoT sensors) collaborate to train a shared machine learning model without directly sharing their private data. However, when the clients have very different data distributions or use different model architectures, this can lead to "model heterogeneity" and degrade the performance of the global model.
To address this issue, the researchers developed FedTSA, a two-stage approach for aggregating the client models. First, FedTSA groups the client models into clusters based on their similarities. Then, it aggregates the models within each cluster to create the final global model.
This clustering step helps account for the differences between the clients, allowing the global model to better incorporate the diverse perspectives and knowledge from the various participants. By breaking the aggregation process into two stages, FedTSA can create a more accurate and representative global model, even when the clients have very different data and model architectures.
Technical Explanation
The FedTSA approach consists of two main stages:
-
Clustering: In the first stage, FedTSA groups the client models into clusters based on their similarities. The authors use a k-means clustering algorithm to partition the client models into k clusters, where the number of clusters k is a hyperparameter.
-
Aggregation: In the second stage, FedTSA aggregates the models within each cluster to create the final global model. For each cluster, the authors use a weighted average of the client models in that cluster, where the weights are proportional to the number of data samples held by each client.
The authors evaluate FedTSA on several benchmark datasets and compare its performance to other federated learning approaches, such as FedAvg and FedSat. They show that FedTSA can achieve better accuracy and convergence compared to these other methods, particularly when the clients have diverse data distributions and model architectures.
Critical Analysis
The FedTSA approach provides a promising solution for addressing model heterogeneity in federated learning, which is an important practical challenge. By incorporating a clustering step, FedTSA can better account for the differences between client models and create a global model that is more representative of the diverse perspectives of the participants.
However, the authors do not discuss the computational complexity of the clustering step, which could be a potential limitation for large-scale federated learning scenarios with many clients. Additionally, the choice of the number of clusters (k) is a critical hyperparameter that may require careful tuning for different applications.
Furthermore, the authors only evaluate FedTSA on relatively simple benchmark datasets and model architectures. It would be interesting to see how well FedTSA performs on more complex real-world federated learning problems, such as those involving highly heterogeneous data and model types.
Conclusion
The FedTSA approach proposes a novel two-stage aggregation method for federated learning that can effectively handle model heterogeneity among participating clients. By incorporating a clustering step to group similar client models, FedTSA can create a more accurate and representative global model compared to traditional federated learning methods.
This research represents an important step forward in addressing the practical challenges of deploying federated learning in real-world scenarios, where data and model heterogeneity are common. As the field of federated learning continues to evolve, approaches like FedTSA will be crucial for enabling the widespread adoption of this promising distributed learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedTSA: A Cluster-based Two-Stage Aggregation Method for Model-heterogeneous Federated Learning
Boyu Fan, Chenrui Wu, Xiang Su, Pan Hui
Despite extensive research into data heterogeneity in federated learning (FL), system heterogeneity remains a significant yet often overlooked challenge. Traditional FL approaches typically assume homogeneous hardware resources across FL clients, implying that clients can train a global model within a comparable time frame. However, in practical FL systems, clients often have heterogeneous resources, which impacts their training capacity. This discrepancy underscores the importance of exploring model-heterogeneous FL, a paradigm allowing clients to train different models based on their resource capabilities. To address this challenge, we introduce FedTSA, a cluster-based two-stage aggregation method tailored for system heterogeneity in FL. FedTSA begins by clustering clients based on their capabilities, then performs a two-stage aggregation: conventional weight averaging for homogeneous models in Stage 1, and deep mutual learning with a diffusion model for aggregating heterogeneous models in Stage 2. Extensive experiments demonstrate that FedTSA not only outperforms the baselines but also explores various factors influencing model performance, validating FedTSA as a promising approach for model-heterogeneous FL.
Read more7/16/2024
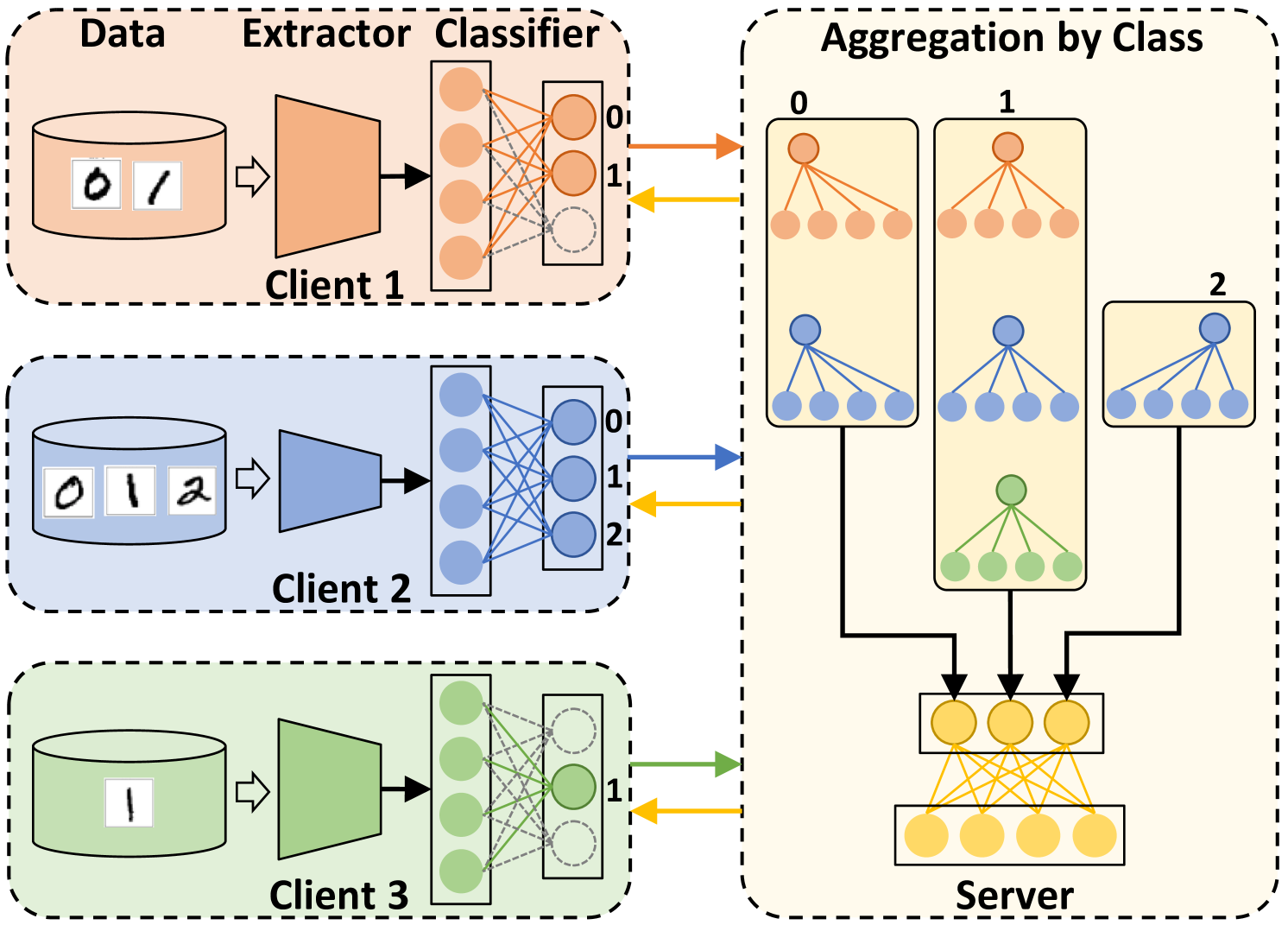
0
FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning
Liping Yi, Han Yu, Zhuan Shi, Gang Wang, Xiaoguang Liu, Lizhen Cui, Xiaoxiao Li
Federated learning (FL) is a privacy-preserving collaboratively machine learning paradigm. Traditional FL requires all data owners (a.k.a. FL clients) to train the same local model. This design is not well-suited for scenarios involving data and/or system heterogeneity. Model-Heterogeneous Personalized FL (MHPFL) has emerged to address this challenge. Existing MHPFL approaches often rely on a public dataset with the same nature as the learning task, or incur high computation and communication costs. To address these limitations, we propose the Federated Semantic Similarity Aggregation (FedSSA) approach for supervised classification tasks, which splits each client's model into a heterogeneous (structure-different) feature extractor and a homogeneous (structure-same) classification header. It performs local-to-global knowledge transfer via semantic similarity-based header parameter aggregation. In addition, global-to-local knowledge transfer is achieved via an adaptive parameter stabilization strategy which fuses the seen-class parameters of historical local headers with that of the latest global header for each client. FedSSA does not rely on public datasets, while only requiring partial header parameter transmission to save costs. Theoretical analysis proves the convergence of FedSSA. Extensive experiments present that FedSSA achieves up to 3.62% higher accuracy, 15.54 times higher communication efficiency, and 15.52 times higher computational efficiency compared to 7 state-of-the-art MHPFL baselines.
Read more4/22/2024

0
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Md Sirajul Islam, Simin Javaherian, Fei Xu, Xu Yuan, Li Chen, Nian-Feng Tzeng
Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {em FedClust} achieves higher model accuracy up to $sim$45% as well as faster convergence with a significantly reduced communication cost up to 2.7$times$ compared to its state-of-the-art counterparts.
Read more7/11/2024

0
An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Yuan Wang, Huazhu Fu, Renuga Kanagavelu, Qingsong Wei, Yong Liu, Rick Siow Mong Goh
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
Read more5/1/2024