FedTrans: Efficient Federated Learning Over Heterogeneous Clients via Model Transformation

0
Sign in to get full access
Overview
- This paper explores the challenges and opportunities in federated learning, a machine learning approach where models are trained across multiple decentralized devices without directly sharing the underlying data.
- It introduces a new framework called Towards Multi-Modal Transformers for Federated Learning that aims to improve the performance and robustness of federated learning models.
- The paper also discusses related work on fair concurrent training of multiple models, adaptive clustered federated learning, and federated distillation.
Plain English Explanation
Federated learning is a way of training machine learning models without directly sharing private data. Instead of gathering all the data in one place, the model is trained on many different devices, like phones or computers, and the model updates are shared back to a central server. This is useful for protecting people's privacy, but it also comes with some challenges.
The paper introduces a new approach called "Towards Multi-Modal Transformers for Federated Learning" that tries to make federated learning models better and more reliable. It builds on top of previous work on things like fair concurrent training, adaptive clustering, and federated distillation. The goal is to create federated learning models that can handle different types of data and are more robust to issues that can come up when training on many different devices.
Technical Explanation
The paper proposes a new framework called "Towards Multi-Modal Transformers for Federated Learning" that aims to improve the performance and robustness of federated learning models. The key elements of the framework include:
-
Multi-Modal Transformers: The framework leverages transformer-based models that can handle different types of data, such as text, images, and audio. This allows the federated learning model to learn richer representations from diverse data sources.
-
Adaptive Clustering: The framework dynamically clusters the participating devices based on their data distributions and learning dynamics. This helps address the challenge of heterogeneous data and devices in federated learning.
-
Fair Concurrent Training: The framework ensures fair and efficient concurrent training of multiple models, preventing model collapse and ensuring consistent performance across the personalized models.
-
Federated Distillation: The framework incorporates knowledge distillation techniques to transfer knowledge from the multi-modal transformers to smaller, more efficient models. This allows for the deployment of high-performing models on resource-constrained edge devices.
The paper evaluates the proposed framework on several benchmark datasets and demonstrates its benefits in terms of model performance, robustness, and efficiency compared to existing federated learning approaches.
Critical Analysis
The paper provides a comprehensive overview of the challenges in federated learning and proposes a novel framework to address them. The authors acknowledge that federated learning faces issues such as data heterogeneity, device heterogeneity, and communication efficiency, and their framework attempts to tackle these challenges.
However, the paper does not delve deeply into the limitations of the proposed approach. For example, it does not discuss the computational overhead or the scalability of the multi-modal transformer models, which could be a concern for deployment on resource-constrained edge devices. Additionally, the paper does not explore the potential privacy implications of the federated distillation technique, where knowledge is transferred from a larger model to smaller models.
Further research could also investigate the performance of the framework on a wider range of datasets and real-world federated learning scenarios, as the current evaluation is limited to a few benchmark tasks.
Conclusion
The paper presents a promising framework called "Towards Multi-Modal Transformers for Federated Learning" that aims to address several key challenges in federated learning. By leveraging multi-modal transformers, adaptive clustering, fair concurrent training, and federated distillation, the framework demonstrates improvements in model performance, robustness, and efficiency.
The proposed approach has the potential to advance the state-of-the-art in federated learning and enable the deployment of high-performing machine learning models on a wide range of edge devices while preserving user privacy. However, further research is needed to fully understand the limitations and practical implications of the framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedTrans: Efficient Federated Learning Over Heterogeneous Clients via Model Transformation
Yuxuan Zhu, Jiachen Liu, Mosharaf Chowdhury, Fan Lai
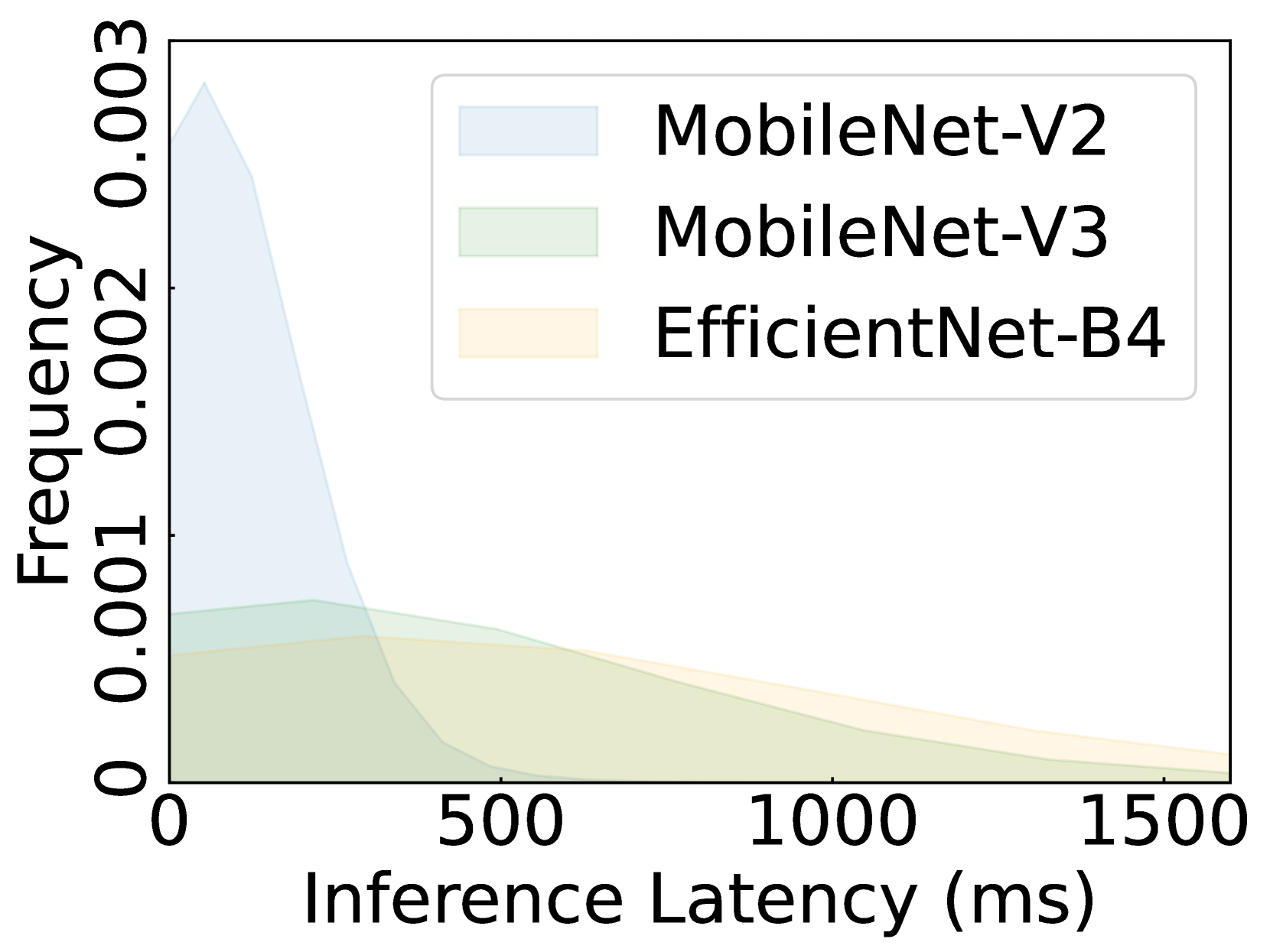
Federated learning (FL) aims to train machine learning (ML) models across potentially millions of edge client devices. Yet, training and customizing models for FL clients is notoriously challenging due to the heterogeneity of client data, device capabilities, and the massive scale of clients, making individualized model exploration prohibitively expensive. State-of-the-art FL solutions personalize a globally trained model or concurrently train multiple models, but they often incur suboptimal model accuracy and huge training costs. In this paper, we introduce FedTrans, a multi-model FL training framework that automatically produces and trains high-accuracy, hardware-compatible models for individual clients at scale. FedTrans begins with a basic global model, identifies accuracy bottlenecks in model architectures during training, and then employs model transformation to derive new models for heterogeneous clients on the fly. It judiciously assigns models to individual clients while performing soft aggregation on multi-model updates to minimize total training costs. Our evaluations using realistic settings show that FedTrans improves individual client model accuracy by 14% - 72% while slashing training costs by 1.6X - 20X over state-of-the-art solutions.
Read more4/29/2024
🛠️
0
FedCross: Towards Accurate Federated Learning via Multi-Model Cross-Aggregation
Ming Hu, Peiheng Zhou, Zhihao Yue, Zhiwei Ling, Yihao Huang, Anran Li, Yang Liu, Xiang Lian, Mingsong Chen
As a promising distributed machine learning paradigm, Federated Learning (FL) has attracted increasing attention to deal with data silo problems without compromising user privacy. By adopting the classic one-to-multi training scheme (i.e., FedAvg), where the cloud server dispatches one single global model to multiple involved clients, conventional FL methods can achieve collaborative model training without data sharing. However, since only one global model cannot always accommodate all the incompatible convergence directions of local models, existing FL approaches greatly suffer from inferior classification accuracy. To address this issue, we present an efficient FL framework named FedCross, which uses a novel multi-to-multi FL training scheme based on our proposed multi-model cross-aggregation approach. Unlike traditional FL methods, in each round of FL training, FedCross uses multiple middleware models to conduct weighted fusion individually. Since the middleware models used by FedCross can quickly converge into the same flat valley in terms of loss landscapes, the generated global model can achieve a well-generalization. Experimental results on various well-known datasets show that, compared with state-of-the-art FL methods, FedCross can significantly improve FL accuracy within both IID and non-IID scenarios without causing additional communication overhead.
Read more7/8/2024
0
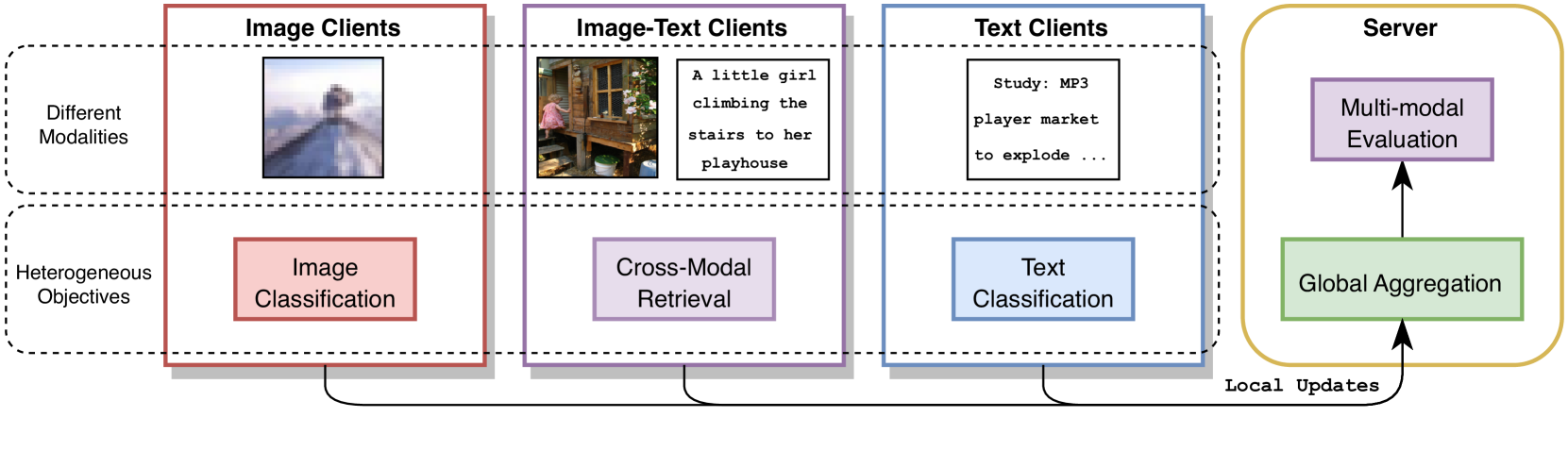
Towards Multi-modal Transformers in Federated Learning
Guangyu Sun, Matias Mendieta, Aritra Dutta, Xin Li, Chen Chen
Multi-modal transformers mark significant progress in different domains, but siloed high-quality data hinders their further improvement. To remedy this, federated learning (FL) has emerged as a promising privacy-preserving paradigm for training models without direct access to the raw data held by different clients. Despite its potential, a considerable research direction regarding the unpaired uni-modal clients and the transformer architecture in FL remains unexplored. To fill this gap, this paper explores a transfer multi-modal federated learning (MFL) scenario within the vision-language domain, where clients possess data of various modalities distributed across different datasets. We systematically evaluate the performance of existing methods when a transformer architecture is utilized and introduce a novel framework called Federated modality complementary and collaboration (FedCola) by addressing the in-modality and cross-modality gaps among clients. Through extensive experiments across various FL settings, FedCola demonstrates superior performance over previous approaches, offering new perspectives on future federated training of multi-modal transformers.
Read more7/18/2024

0
FedAST: Federated Asynchronous Simultaneous Training
Baris Askin, Pranay Sharma, Carlee Joe-Wong, Gauri Joshi
Federated Learning (FL) enables edge devices or clients to collaboratively train machine learning (ML) models without sharing their private data. Much of the existing work in FL focuses on efficiently learning a model for a single task. In this paper, we study simultaneous training of multiple FL models using a common set of clients. The few existing simultaneous training methods employ synchronous aggregation of client updates, which can cause significant delays because large models and/or slow clients can bottleneck the aggregation. On the other hand, a naive asynchronous aggregation is adversely affected by stale client updates. We propose FedAST, a buffered asynchronous federated simultaneous training algorithm that overcomes bottlenecks from slow models and adaptively allocates client resources across heterogeneous tasks. We provide theoretical convergence guarantees for FedAST for smooth non-convex objective functions. Extensive experiments over multiple real-world datasets demonstrate that our proposed method outperforms existing simultaneous FL approaches, achieving up to 46.0% reduction in time to train multiple tasks to completion.
Read more6/4/2024