Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models

0

Sign in to get full access
Overview
- This paper presents Ferret-v2, an improved baseline model for referring and grounding tasks with large language models (LLMs).
- Referring and grounding tasks involve understanding the meaning and context of language, and then linking it to visual elements in an image.
- The authors show that Ferret-v2 outperforms previous state-of-the-art models on several benchmark datasets, demonstrating its effectiveness as a strong baseline.
Plain English Explanation
The paper describes an improved version of the Ferret model, which is used to understand language and connect it to visual information in images. This type of task, known as referring and grounding, is important for applications like image captioning and visual question answering.
The key idea behind Ferret-v2 is to leverage the capabilities of large language models, which have shown impressive performance on a variety of natural language processing tasks. By fine-tuning these powerful language models on referring and grounding datasets, the authors were able to create a strong baseline model that outperforms previous state-of-the-art approaches.
This is significant because it provides a solid foundation for further research and development in this area. A strong baseline model like Ferret-v2 can help other researchers build upon it and push the boundaries of what's possible in linking language and vision.
Technical Explanation
The paper first provides background on the use of coarse-level and fine-level large language models (LLMs) for referring and grounding tasks. Coarse-level LLMs, like BERT, are trained on general language data, while fine-level LLMs are further trained on specific tasks or datasets.
The authors then introduce the Ferret-v2 model, which builds on the original Ferret model by incorporating a number of enhancements. These include:
- Using a more powerful LLM as the backbone (e.g., GPT-3)
- Introducing a specialized referring expression encoder
- Incorporating multimodal fusion techniques to better integrate language and visual information
The paper describes the model architecture and the training process, which involves fine-tuning the LLM on referring and grounding datasets. The authors then evaluate Ferret-v2 on several benchmark datasets, including Refcoco, Flickr30k Entities, and RefCOCOg. The results show that Ferret-v2 outperforms previous state-of-the-art models, establishing a new benchmark for referring and grounding tasks.
Critical Analysis
The paper provides a thorough evaluation of Ferret-v2 and demonstrates its effectiveness as a strong baseline model. However, the authors acknowledge that there is still room for improvement, particularly in terms of handling more complex language and visual understanding tasks.
One potential limitation is that the model may struggle with referring expressions that require a deeper understanding of context and semantics. Additionally, the performance of the model may be dependent on the quality and diversity of the training data, which could be an area for further research.
While the paper focuses on the referring and grounding tasks, the techniques used in Ferret-v2 could potentially be applied to a wider range of vision-language challenges, such as image captioning and visual question answering. Exploring these possibilities could be an interesting direction for future work.
Conclusion
The Ferret-v2 model presented in this paper represents a significant advancement in the field of referring and grounding tasks with large language models. By leveraging the power of LLMs and introducing several key architectural and training enhancements, the authors have created a strong baseline that outperforms previous state-of-the-art models.
This work highlights the potential of LLMs to serve as a foundation for a wide range of vision-language tasks, and the authors' findings could inspire further research and development in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
Haotian Zhang, Haoxuan You, Philipp Dufter, Bowen Zhang, Chen Chen, Hong-You Chen, Tsu-Jui Fu, William Yang Wang, Shih-Fu Chang, Zhe Gan, Yinfei Yang
While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model's ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
Read more4/12/2024
🤔
37
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, Zhe Gan
Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate any resolution on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
Read more4/9/2024

0
Ferret: Federated Full-Parameter Tuning at Scale for Large Language Models
Yao Shu, Wenyang Hu, See-Kiong Ng, Bryan Kian Hsiang Low, Fei Richard Yu
Large Language Models (LLMs) have become indispensable in numerous real-world applications. Unfortunately, fine-tuning these models at scale, especially in federated settings where data privacy and communication efficiency are critical, presents significant challenges. Existing methods often resort to parameter-efficient fine-tuning (PEFT) to mitigate communication overhead, but this typically comes at the cost of model accuracy. To address these limitations, we propose federated full-parameter tuning at scale for LLMs (Ferret), the first first-order method with shared randomness to enable scalable full-parameter tuning of LLMs across decentralized data sources while maintaining competitive model accuracy. Ferret accomplishes this through three aspects: (1) it employs widely applied first-order methods for efficient local updates; (2) it projects these updates into a low-dimensional space to considerably reduce communication overhead; and (3) it reconstructs local updates from this low-dimensional space with shared randomness to facilitate effective full-parameter global aggregation, ensuring fast convergence and competitive final performance. Our rigorous theoretical analyses and insights along with extensive experiments, show that Ferret significantly enhances the scalability of existing federated full-parameter tuning approaches by achieving high computational efficiency, reduced communication overhead, and fast convergence, all while maintaining competitive model accuracy. Our implementation is available at https://github.com/allen4747/Ferret.
Read more9/12/2024
0
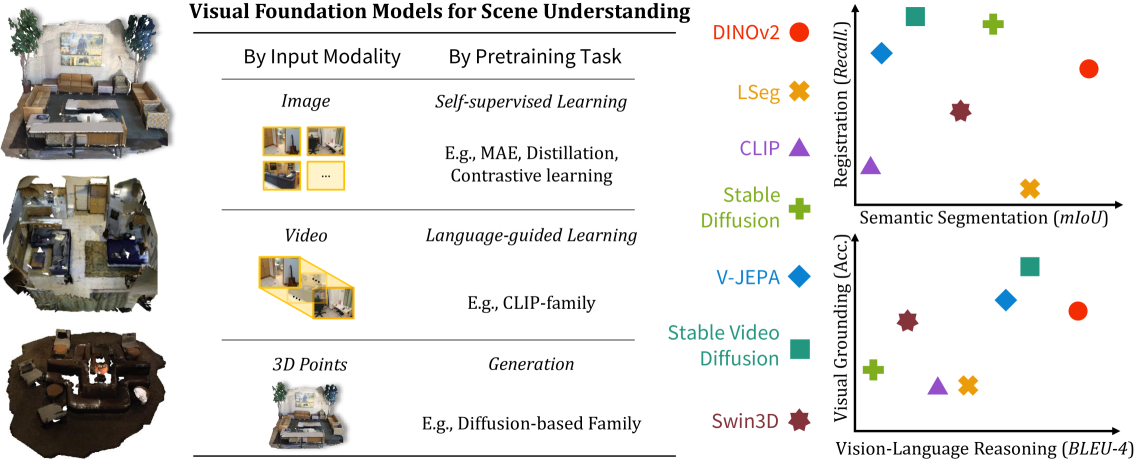
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
Yunze Man, Shuhong Zheng, Zhipeng Bao, Martial Hebert, Liang-Yan Gui, Yu-Xiong Wang
Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
Read more9/6/2024