Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding

0
Sign in to get full access
Overview
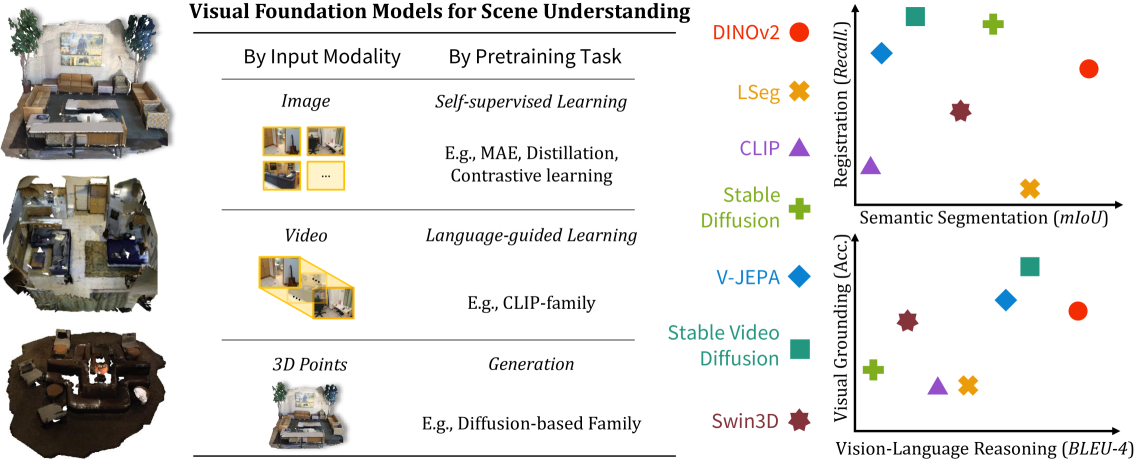
- Lexicon3D is a study that probes the 3D scene understanding capabilities of visual foundation models.
- The paper explores how well these models can reason about complex 3D environments and their constituent objects.
- Experiments are conducted to assess the models' performance on tasks like object detection, pose estimation, and 3D scene graph recovery.
- The findings provide insights into the 3D awareness of current state-of-the-art vision models.
Plain English Explanation
The Lexicon3D paper investigates how well advanced artificial intelligence (AI) vision models can understand and reason about 3D scenes. These "visual foundation models" have shown impressive performance on many 2D image understanding tasks, but it's not clear how well they can handle the additional complexity of 3D environments.
The researchers designed a series of experiments to probe the 3D capabilities of these models. They tested the models' ability to detect objects in 3D scenes, estimate the 3D poses of those objects, and even reconstruct the overall 3D scene structure. By analyzing the models' performance on these tasks, the researchers gained insights into the extent of the models' 3D understanding.
The findings suggest that current state-of-the-art vision models do have some 3D awareness, but there is still significant room for improvement. The models struggled with certain 3D-specific challenges, like accurately estimating object poses and recovering the full 3D scene graph. This work highlights the need for continued advancements in AI's 3D perception and reasoning abilities.
Technical Explanation
The Lexicon3D paper presents a comprehensive evaluation of how well visual foundation models can handle 3D scene understanding tasks. The researchers used a diverse set of 3D datasets, including ScanNet and OpenSUNNY3D, to assess the models' performance on object detection, 6D pose estimation, and 3D scene graph recovery.
The experiments involved fine-tuning and evaluating popular 2D vision models, such as CLIP and ViT, on these 3D-centric tasks. The researchers also explored the impact of various training strategies, including self-supervised pretraining and few-shot learning, on the models' 3D understanding capabilities.
The results reveal that while the tested models exhibit some 3D awareness, they struggle with many 3D-specific challenges. The models performed reasonably well on object detection but had difficulty accurately estimating object poses and reconstructing the full 3D scene structure. The paper provides detailed analyses of the models' strengths and weaknesses, offering insights into the current state of 3D scene understanding in visual foundation models.
Critical Analysis
The Lexicon3D study takes an important step in understanding the 3D capabilities of state-of-the-art vision models. By probing the models' performance on a range of 3D tasks, the researchers have shed light on the current limitations and future research directions for achieving more robust 3D scene understanding.
One potential limitation of the study is the reliance on a relatively small set of 3D datasets. While the chosen datasets, such as ScanNet and OpenSUNNY3D, are well-established benchmarks, expanding the evaluation to a broader and more diverse set of 3D scenes could provide a more comprehensive understanding of the models' capabilities.
Additionally, the paper could have explored the impact of different architectural choices and training regimes in more depth. Investigating how specific model designs or pretraining strategies affect 3D performance could yield valuable insights for future model development.
Overall, the Lexicon3D study is a valuable contribution to the field of 3D scene understanding, highlighting the progress and limitations of current visual foundation models. The findings presented in this paper can inform the design of more capable 3D perception systems and guide future research in this important area of computer vision.
Conclusion
The Lexicon3D paper provides a comprehensive evaluation of the 3D scene understanding capabilities of state-of-the-art visual foundation models. The study's findings suggest that while these models exhibit some level of 3D awareness, they still struggle with various 3D-specific tasks, such as accurate object pose estimation and complete 3D scene reconstruction.
The insights gained from this work can inform the development of more advanced 3D perception systems, which are crucial for applications like robotics, autonomous vehicles, and augmented reality. By understanding the current limitations of visual foundation models in 3D understanding, researchers and engineers can focus their efforts on addressing these challenges and advancing the field of 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
Yunze Man, Shuhong Zheng, Zhipeng Bao, Martial Hebert, Liang-Yan Gui, Yu-Xiong Wang
Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
Read more9/6/2024

0
Probing the 3D Awareness of Visual Foundation Models
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, Varun Jampani
Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
Read more4/15/2024
0
OpenSU3D: Open World 3D Scene Understanding using Foundation Models
Rafay Mohiuddin, Sai Manoj Prakhya, Fiona Collins, Ziyuan Liu, Andr'e Borrmann
In this paper, we present a novel, scalable approach for constructing open set, instance-level 3D scene representations, advancing open world understanding of 3D environments. Existing methods require pre-constructed 3D scenes and face scalability issues due to per-point feature vector learning, limiting their efficacy with complex queries. Our method overcomes these limitations by incrementally building instance-level 3D scene representations using 2D foundation models, efficiently aggregating instance-level details such as masks, feature vectors, names, and captions. We introduce fusion schemes for feature vectors to enhance their contextual knowledge and performance on complex queries. Additionally, we explore large language models for robust automatic annotation and spatial reasoning tasks. We evaluate our proposed approach on multiple scenes from ScanNet and Replica datasets demonstrating zero-shot generalization capabilities, exceeding current state-of-the-art methods in open world 3D scene understanding.
Read more9/17/2024
🤔
0
Language-Image Models with 3D Understanding
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krahenbuhl, Yan Wang, Marco Pavone
Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
Read more5/7/2024