FF-LOGO: Cross-Modality Point Cloud Registration with Feature Filtering and Local to Global Optimization

0
✨
Sign in to get full access
Overview
- The paper proposes a cross-modality point cloud registration framework called FF-LOGO, which addresses the challenges of registering point clouds from different sensor modalities.
- The framework includes a cross-modality feature correlation filtering module to extract geometric transformation-invariant features and perform point selection.
- It also introduces a two-stage optimization process, with a local adaptive key region aggregation module and a global modality consistency fusion optimization module.
Plain English Explanation
The paper tackles the problem of aligning or "registering" 3D point cloud data from different types of sensors, such as laser scanners and cameras. This is a challenging task because the data from these sensors can be quite different, making it hard to find common features to match them up.
To solve this, the researchers developed a FF-LOGO framework that has two main components:
-
Feature Filtering: The framework first extracts distinctive geometric features from the point clouds that are resistant to changes in the sensor modality. It then uses these features to select a subset of points that are most useful for the registration process.
-
Optimization: The framework then performs a two-stage optimization process. First, it looks at local regions of the point clouds and aggregates the features in a way that adapts to the specific data. Then, it performs a global optimization that ensures the final registration is consistent across the entire scene.
By using this two-step approach, the FF-LOGO framework is able to significantly improve the accuracy of cross-modality point cloud registration compared to existing methods. This could have important applications in areas like autonomous driving, robotics, and 3D mapping, where data from different sensors needs to be combined seamlessly.
Technical Explanation
The key technical components of the FF-LOGO framework are:
-
Cross-Modality Feature Correlation Filtering: This module extracts geometric features from the input point clouds that are invariant to changes in sensor modality. It then uses feature matching to select a subset of points that are most useful for registration.
-
Local Adaptive Key Region Aggregation: This component looks at local regions of the point clouds and aggregates the features in a way that adapts to the specific characteristics of the data in that region. This helps improve the registration accuracy in challenging areas.
-
Global Modality Consistency Fusion Optimization: The final optimization step ensures that the overall registration is consistent across the entire scene, by fusing the local adaptations into a globally coherent alignment.
The researchers evaluated their FF-LOGO framework on the 3DCSR dataset, which contains point cloud data from different sensor modalities. They showed that their two-stage optimization approach significantly outperforms existing state-of-the-art methods, improving the recall rate from 40.59% to 75.74%.
Critical Analysis
The paper presents a well-designed and effective solution for the challenging problem of cross-modality point cloud registration. The use of geometric feature filtering and the two-stage optimization process are clever and seem to yield substantial improvements in registration accuracy.
However, the paper does not explore the limitations of the approach or potential areas for further research. For example, it's not clear how the framework would handle extreme differences in sensor modalities, such as registering laser scans with thermal images. Additionally, the computational complexity of the optimization process is not discussed, which could be an important consideration for real-time applications.
It would also be helpful to see more analysis on the types of scenes or environments where the FF-LOGO framework excels or struggles. This could provide useful insights for practitioners looking to apply the technique in their own domains.
Overall, the paper makes a valuable contribution to the field of 3D point cloud registration, and the FF-LOGO framework appears to be a promising solution. However, further research and analysis could help identify the method's strengths, weaknesses, and areas for improvement.
Conclusion
The FF-LOGO framework proposed in this paper represents a significant advancement in the field of cross-modality point cloud registration. By combining geometric feature filtering with a two-stage optimization process, the framework is able to achieve substantial improvements in registration accuracy compared to existing state-of-the-art methods.
This work could have important implications for applications that rely on fusing data from multiple 3D sensors, such as autonomous driving, robotics, and 3D mapping. The ability to accurately register point clouds from different modalities could enable more robust and reliable 3D perception systems, with benefits for both industry and society.
While the paper does not explore all the potential limitations and areas for further research, the core technical contributions of the FF-LOGO framework are impressive and demonstrate the value of innovative approaches to this challenging problem. As the field of 3D perception continues to evolve, this work will likely serve as an important reference for researchers and practitioners alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
FF-LOGO: Cross-Modality Point Cloud Registration with Feature Filtering and Local to Global Optimization
Nan Ma, Mohan Wang, Yiheng Han, Yong-Jin Liu
Cross-modality point cloud registration is confronted with significant challenges due to inherent differences in modalities between different sensors. We propose a cross-modality point cloud registration framework FF-LOGO: a cross-modality point cloud registration method with feature filtering and local-global optimization. The cross-modality feature correlation filtering module extracts geometric transformation-invariant features from cross-modality point clouds and achieves point selection by feature matching. We also introduce a cross-modality optimization process, including a local adaptive key region aggregation module and a global modality consistency fusion optimization module. Experimental results demonstrate that our two-stage optimization significantly improves the registration accuracy of the feature association and selection module. Our method achieves a substantial increase in recall rate compared to the current state-of-the-art methods on the 3DCSR dataset, improving from 40.59% to 75.74%. Our code will be available at https://github.com/wangmohan17/FFLOGO.
Read more4/15/2024
0
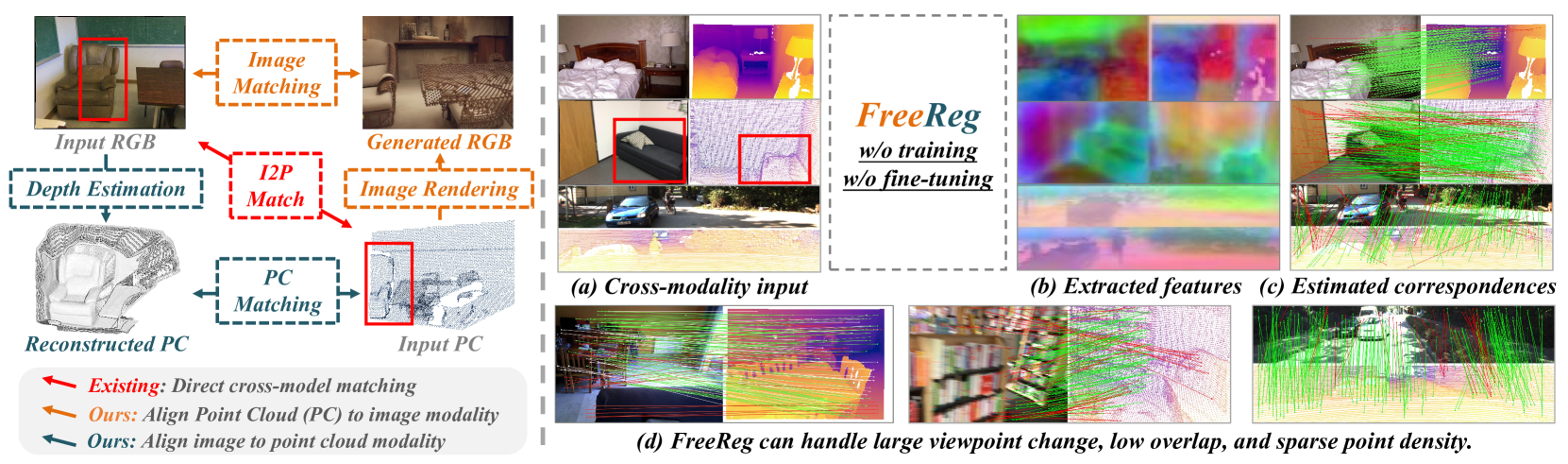
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024
✨
0
RGBD-Glue: General Feature Combination for Robust RGB-D Point Cloud Registration
Congjia Chen, Xiaoyu Jia, Yanhong Zheng, Yufu Qu
Point cloud registration is a fundamental task for estimating rigid transformations between point clouds. Previous studies have used geometric information for extracting features, matching and estimating transformation. Recently, owing to the advancement of RGB-D sensors, researchers have attempted to combine visual and geometric information to improve registration performance. However, these studies focused on extracting distinctive features by deep feature fusion, which cannot effectively solve the negative effects of each feature's weakness, and cannot sufficiently leverage the valid information. In this paper, we propose a new feature combination framework, which applies a looser but more effective combination. An explicit filter based on transformation consistency is designed for the combination framework, which can overcome each feature's weakness. And an adaptive threshold determined by the error distribution is proposed to extract more valid information from the two types of features. Owing to the distinctive design, our proposed framework can estimate more accurate correspondences and is applicable to both hand-crafted and learning-based feature descriptors. Experiments on ScanNet and 3DMatch show that our method achieves a state-of-the-art performance.
Read more8/22/2024

0
ML-SemReg: Boosting Point Cloud Registration with Multi-level Semantic Consistency
Shaocheng Yan, Pengcheng Shi, Jiayuan Li
Recent advances in point cloud registration mostly leverage geometric information. Although these methods have yielded promising results, they still struggle with problems of low overlap, thus limiting their practical usage. In this paper, we propose ML-SemReg, a plug-and-play point cloud registration framework that fully exploits semantic information. Our key insight is that mismatches can be categorized into two types, i.e., inter- and intra-class, after rendering semantic clues, and can be well addressed by utilizing multi-level semantic consistency. We first propose a Group Matching module to address inter-class mismatching, outputting multiple matching groups that inherently satisfy Local Semantic Consistency. For each group, a Mask Matching module based on Scene Semantic Consistency is then introduced to suppress intra-class mismatching. Benefit from those two modules, ML-SemReg generates correspondences with a high inlier ratio. Extensive experiments demonstrate excellent performance and robustness of ML-SemReg, e.g., in hard-cases of the KITTI dataset, the Registration Recall of MAC increases by almost 34 percentage points when our ML-SemReg is equipped. Code is available at url{https://github.com/Laka-3DV/ML-SemReg}
Read more7/16/2024