FFN: a Fine-grained Chinese-English Financial Domain Parallel Corpus

0
🌀
Sign in to get full access
Overview
- This paper introduces a new Chinese-English parallel corpus called FFN (Fine-grained Financial News) for the financial domain.
- The corpus contains fine-grained annotations for various financial concepts and entities, making it a valuable resource for training and evaluating large language models in the financial domain.
- The paper also reports on the development and analysis of this corpus, including data collection, annotation, and validation processes.
Plain English Explanation
This paper describes the creation of a new dataset called FFN (Fine-grained Financial News) that contains parallel text in Chinese and English focused on the financial domain. The dataset includes detailed annotations of various financial concepts and entities, which makes it particularly useful for training and testing language models that need to understand and work with financial information.
The researchers collected a large amount of financial news articles in both Chinese and English, and then carefully went through the process of annotating these articles to identify and label important financial terms, entities, and other relevant information. This resulted in a high-quality parallel corpus that can be used by researchers and companies working on natural language processing for finance-related applications.
The key advantage of this dataset is its fine-grained annotations, which go beyond just translating the text between the two languages. By tagging specific financial concepts, the corpus can help language models better understand the nuances and complexities of financial language, which is important for tasks like automated financial analysis, chatbots for financial advice, and summarization of financial news.
Technical Explanation
The researchers created the FFN: a Fine-grained Chinese-English Financial Domain Parallel Corpus by collecting a large set of parallel Chinese and English financial news articles from various online sources. They then developed a detailed annotation scheme to identify and label a wide range of financial entities, concepts, and relations within the text.
The annotation process involved multiple steps, including automatic pre-processing, manual annotation by domain experts, and validation. This resulted in a high-quality dataset with consistent and reliable annotations, covering topics such as financial institutions, economic indicators, stock market information, and more.
The researchers explored the characteristics of the FFN corpus, including the distribution of different financial entities and the degree of alignment between the Chinese and English text. They also compared the FFN corpus to other existing Chinese-English parallel datasets, demonstrating its unique value for fine-grained financial language understanding.
Critical Analysis
The FFN corpus appears to be a well-designed and carefully constructed resource for the financial domain. The researchers have put significant effort into ensuring the quality and consistency of the annotations, which is crucial for training and evaluating language models in this specialized area.
One potential limitation of the corpus is the scope of the financial topics covered. While the annotations span a range of financial concepts, the dataset may not be comprehensive enough to capture the full breadth and complexity of financial language. Expanding the corpus to include a wider range of financial genres and use cases could further enhance its utility.
Additionally, the paper does not provide detailed insights into the performance of language models trained on the FFN corpus, nor does it compare the corpus to other financial datasets. Evaluating the impact of the FFN corpus on downstream financial language processing tasks would be a valuable addition to the research.
Conclusion
The FFN: a Fine-grained Chinese-English Financial Domain Parallel Corpus represents a significant contribution to the field of financial natural language processing. By providing a high-quality, annotated dataset that spans both Chinese and English financial text, the researchers have created a valuable resource for training and evaluating large language models in the financial domain.
The fine-grained annotations and the focus on financial-specific concepts and entities make the FFN corpus particularly well-suited for applications that require a deep understanding of financial language, such as automated financial analysis, personalized financial advice, and summarization of financial news. As large language models continue to advance, datasets like FFN will be increasingly crucial for pushing the boundaries of what these models can achieve in the financial sector.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
FFN: a Fine-grained Chinese-English Financial Domain Parallel Corpus
Yuxin Fu, Shijing Si, Leyi Mai, Xi-ang Li
Large Language Models (LLMs) have stunningly advanced the field of machine translation, though their effectiveness within the financial domain remains largely underexplored. To probe this issue, we constructed a fine-grained Chinese-English parallel corpus of financial news called FFN. We acquired financial news articles spanning between January 1st, 2014, to December 31, 2023, from mainstream media websites such as CNN, FOX, and China Daily. The dataset consists of 1,013 main text and 809 titles, all of which have been manually corrected. We measured the translation quality of two LLMs -- ChatGPT and ERNIE-bot, utilizing BLEU, TER and chrF scores as the evaluation metrics. For comparison, we also trained an OpenNMT model based on our dataset. We detail problems of LLMs and provide in-depth analysis, intending to stimulate further research and solutions in this largely uncharted territory. Our research underlines the need to optimize LLMs within the specific field of financial translation to ensure accuracy and quality.
Read more6/28/2024
0
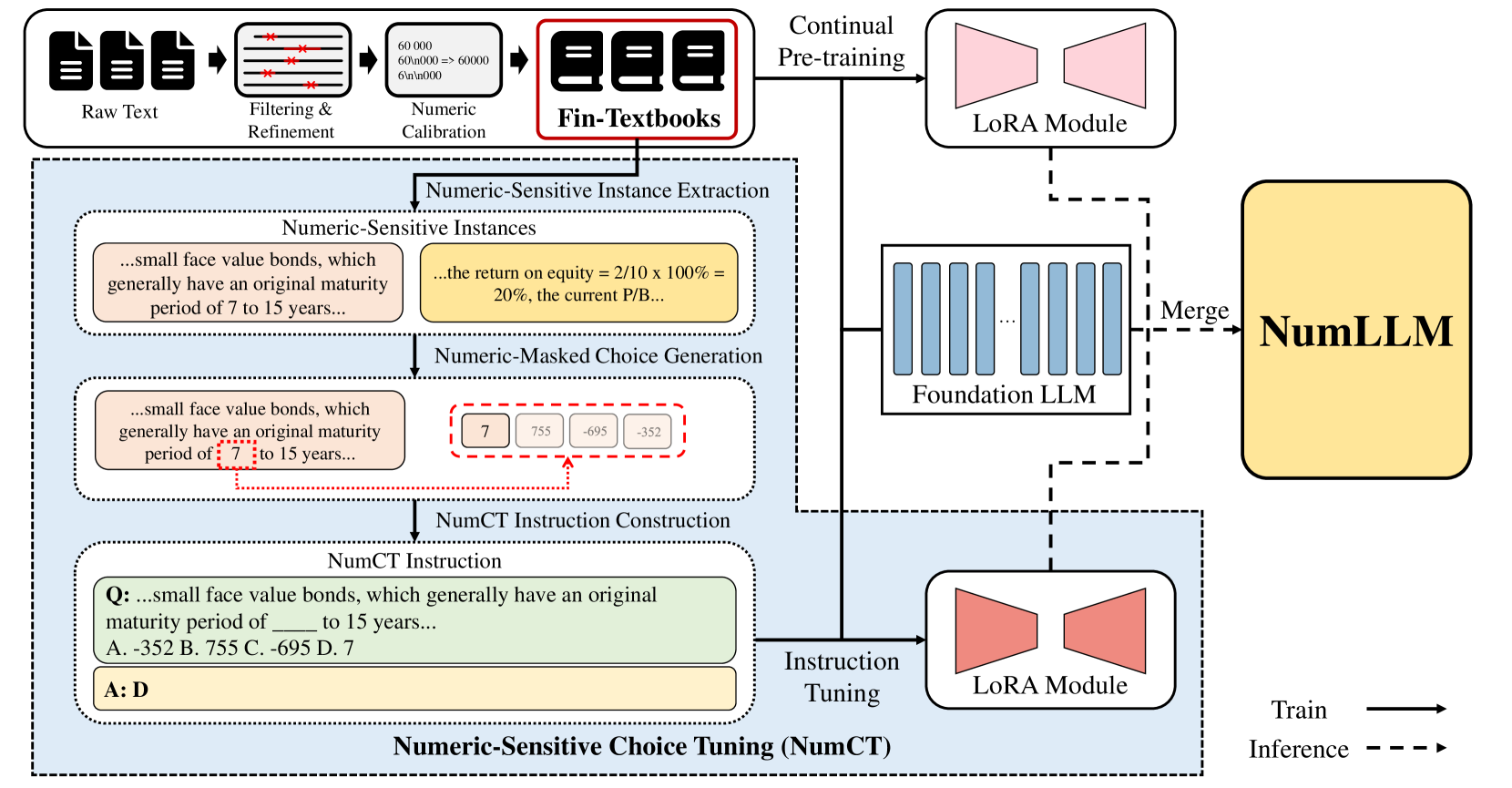
NumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
Huan-Yi Su, Ke Wu, Yu-Hao Huang, Wu-Jun Li
Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.
Read more5/2/2024

0
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Qianqian Xie, Dong Li, Mengxi Xiao, Zihao Jiang, Ruoyu Xiang, Xiao Zhang, Zhengyu Chen, Yueru He, Weiguang Han, Yuzhe Yang, Shunian Chen, Yifei Zhang, Lihang Shen, Daniel Kim, Zhiwei Liu, Zheheng Luo, Yangyang Yu, Yupeng Cao, Zhiyang Deng, Zhiyuan Yao, Haohang Li, Duanyu Feng, Yongfu Dai, VijayaSai Somasundaram, Peng Lu, Yilun Zhao, Yitao Long, Guojun Xiong, Kaleb Smith, Honghai Yu, Yanzhao Lai, Min Peng, Jianyun Nie, Jordan W. Suchow, Xiao-Yang Liu, Benyou Wang, Alejandro Lopez-Lira, Jimin Huang, Sophia Ananiadou
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Read more8/23/2024

0
Benchmarking Large Language Models on CFLUE -- A Chinese Financial Language Understanding Evaluation Dataset
Jie Zhu, Junhui Li, Yalong Wen, Lifan Guo
In light of recent breakthroughs in large language models (LLMs) that have revolutionized natural language processing (NLP), there is an urgent need for new benchmarks to keep pace with the fast development of LLMs. In this paper, we propose CFLUE, the Chinese Financial Language Understanding Evaluation benchmark, designed to assess the capability of LLMs across various dimensions. Specifically, CFLUE provides datasets tailored for both knowledge assessment and application assessment. In knowledge assessment, it consists of 38K+ multiple-choice questions with associated solution explanations. These questions serve dual purposes: answer prediction and question reasoning. In application assessment, CFLUE features 16K+ test instances across distinct groups of NLP tasks such as text classification, machine translation, relation extraction, reading comprehension, and text generation. Upon CFLUE, we conduct a thorough evaluation of representative LLMs. The results reveal that only GPT-4 and GPT-4-turbo achieve an accuracy exceeding 60% in answer prediction for knowledge assessment, suggesting that there is still substantial room for improvement in current LLMs. In application assessment, although GPT-4 and GPT-4-turbo are the top two performers, their considerable advantage over lightweight LLMs is noticeably diminished. The datasets and scripts associated with CFLUE are openly accessible at https://github.com/aliyun/cflue.
Read more5/20/2024