SuperCLUE-Fin: Graded Fine-Grained Analysis of Chinese LLMs on Diverse Financial Tasks and Applications
2404.19063
0
0
Abstract
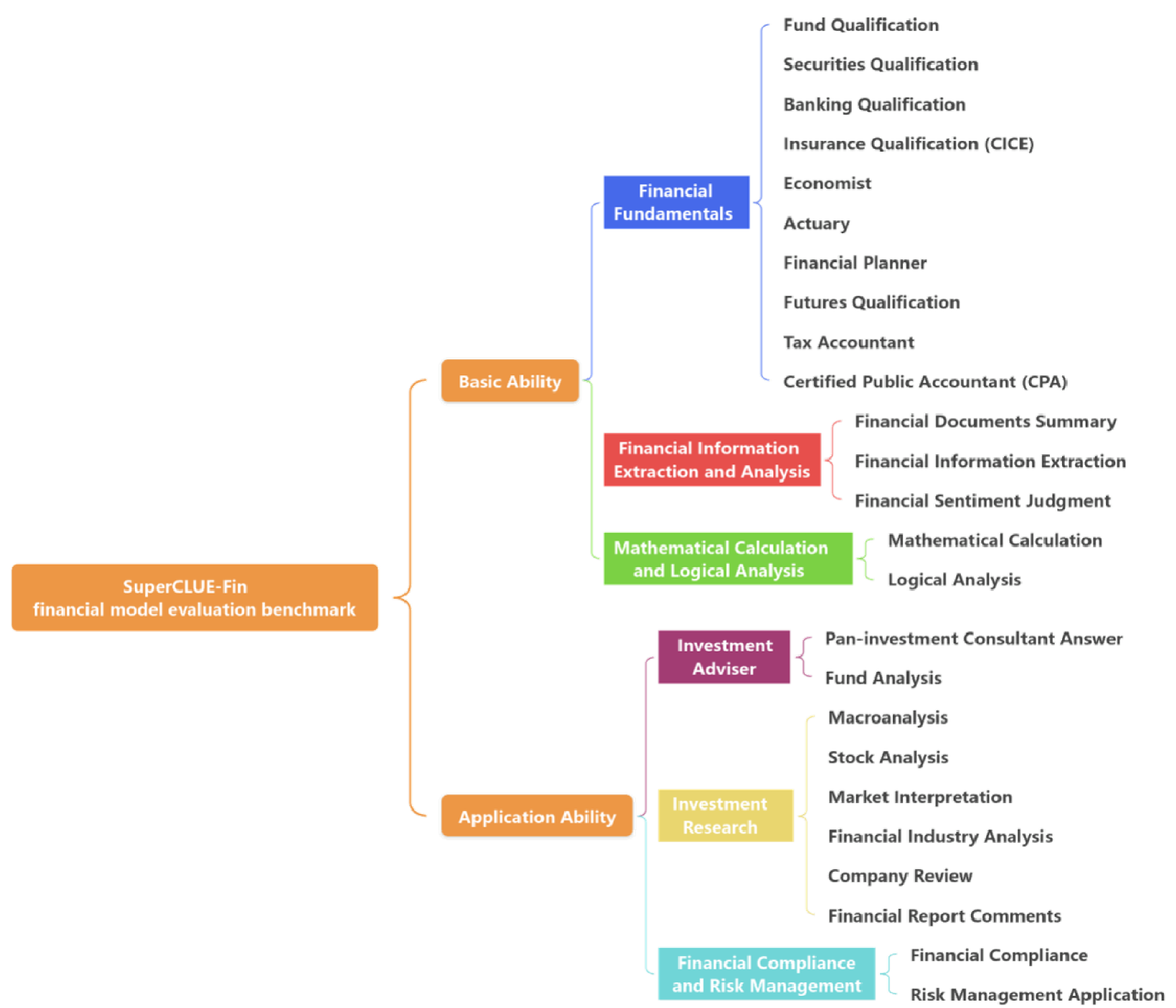
The SuperCLUE-Fin (SC-Fin) benchmark is a pioneering evaluation framework tailored for Chinese-native financial large language models (FLMs). It assesses FLMs across six financial application domains and twenty-five specialized tasks, encompassing theoretical knowledge and practical applications such as compliance, risk management, and investment analysis. Using multi-turn, open-ended conversations that mimic real-life scenarios, SC-Fin measures models on a range of criteria, including accurate financial understanding, logical reasoning, clarity, computational efficiency, business acumen, risk perception, and compliance with Chinese regulations. In a rigorous evaluation involving over a thousand questions, SC-Fin identifies a performance hierarchy where domestic models like GLM-4 and MoonShot-v1-128k outperform others with an A-grade, highlighting the potential for further development in transforming theoretical knowledge into pragmatic financial solutions. This benchmark serves as a critical tool for refining FLMs in the Chinese context, directing improvements in financial knowledge databases, standardizing financial interpretations, and promoting models that prioritize compliance, risk management, and secure practices. We create a contextually relevant and comprehensive benchmark that drives the development of AI in the Chinese financial sector. SC-Fin facilitates the advancement and responsible deployment of FLMs, offering valuable insights for enhancing model performance and usability for both individual and institutional users in the Chinese market..~footnote{Our benchmark can be found at url{https://www.CLUEbenchmarks.com}}.
Create account to get full access
Overview
- This paper presents SuperCLUE-Fin, a comprehensive benchmark for evaluating the performance of large language models (LLMs) on diverse financial tasks in Chinese.
- The benchmark covers a wide range of financial applications, including fundamental knowledge, relationship extraction, and clinical language understanding.
- The authors conduct a detailed analysis of the performance of several leading Chinese LLMs on the SuperCLUE-Fin tasks, providing insights into the strengths and limitations of these models in the financial domain.
Plain English Explanation
The paper describes a new benchmark called SuperCLUE-Fin that is designed to test the capabilities of large language models (LLMs) when it comes to financial tasks in the Chinese language. LLMs are advanced AI systems that can understand and generate human-like text. The benchmark covers a variety of financial applications, such as FoundaBench for evaluating fundamental financial knowledge, CRE-LLM for relation extraction, and CLUE for clinical language understanding.
The researchers tested several leading Chinese LLMs on the SuperCLUE-Fin benchmark and analyzed their performance. This allows them to identify the strengths and weaknesses of these models when it comes to financial tasks in the Chinese language. The goal is to provide a comprehensive evaluation of how well these AI systems can handle a variety of financial applications, which is important as LLMs become more widely used in the financial industry.
Technical Explanation
The paper introduces the SuperCLUE-Fin benchmark, which builds on previous work such as FoundaBench, CRE-LLM, and CLUE. SuperCLUE-Fin consists of 11 diverse financial tasks spanning fundamental knowledge, relationship extraction, and clinical language understanding. The authors evaluate the performance of several leading Chinese LLMs, including SilverSight and FinLangNet, on this benchmark.
The experiments show that while these LLMs demonstrate strong performance on some financial tasks, they still struggle with others, particularly those requiring in-depth domain knowledge or complex reasoning. The authors provide a detailed, graded analysis of the models' capabilities, highlighting areas for improvement and opportunities for future research.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of Chinese LLMs on financial tasks, which is a valuable contribution to the field. However, the authors acknowledge several limitations of the study. For example, the benchmark does not cover all possible financial applications, and the performance of the models may be influenced by factors such as the size and quality of the training data.
Additionally, the paper does not address potential biases or ethical considerations in the deployment of these LLMs in the financial industry. As these models become more widely used, it will be important to ensure that they do not perpetuate or amplify existing biases or make decisions that could have significant financial and societal consequences.
Further research is needed to address these limitations and to explore the long-term implications of using LLMs in the financial domain. Encouraging critical thinking and fostering ongoing discussions around the responsible development and use of these technologies will be crucial as the field continues to evolve.
Conclusion
The SuperCLUE-Fin benchmark provides a valuable tool for evaluating the performance of Chinese LLMs on a wide range of financial tasks. The detailed analysis presented in the paper offers insights into the strengths and limitations of these models, highlighting areas for improvement and potential future research directions.
As LLMs become more widely adopted in the financial industry, it will be important to continue studying their capabilities and limitations, as well as the potential risks and ethical considerations associated with their use. By encouraging critical thinking and fostering ongoing discussions, the research community can help ensure that these powerful AI systems are developed and deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Benchmarking Large Language Models on CFLUE -- A Chinese Financial Language Understanding Evaluation Dataset
Jie Zhu, Junhui Li, Yalong Wen, Lifan Guo
0
0
In light of recent breakthroughs in large language models (LLMs) that have revolutionized natural language processing (NLP), there is an urgent need for new benchmarks to keep pace with the fast development of LLMs. In this paper, we propose CFLUE, the Chinese Financial Language Understanding Evaluation benchmark, designed to assess the capability of LLMs across various dimensions. Specifically, CFLUE provides datasets tailored for both knowledge assessment and application assessment. In knowledge assessment, it consists of 38K+ multiple-choice questions with associated solution explanations. These questions serve dual purposes: answer prediction and question reasoning. In application assessment, CFLUE features 16K+ test instances across distinct groups of NLP tasks such as text classification, machine translation, relation extraction, reading comprehension, and text generation. Upon CFLUE, we conduct a thorough evaluation of representative LLMs. The results reveal that only GPT-4 and GPT-4-turbo achieve an accuracy exceeding 60% in answer prediction for knowledge assessment, suggesting that there is still substantial room for improvement in current LLMs. In application assessment, although GPT-4 and GPT-4-turbo are the top two performers, their considerable advantage over lightweight LLMs is noticeably diminished. The datasets and scripts associated with CFLUE are openly accessible at https://github.com/aliyun/cflue.
5/20/2024
💬
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Yang Lei, Jiangtong Li, Dawei Cheng, Zhijun Ding, Changjun Jiang
0
0
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
5/22/2024
FinDABench: Benchmarking Financial Data Analysis Ability of Large Language Models
Shu Liu, Shangqing Zhao, Chenghao Jia, Xinlin Zhuang, Zhaoguang Long, Jie Zhou, Aimin Zhou, Man Lan, Qingquan Wu, Chong Yang
0
0
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of financial data analysis, particularly focusing on data-driven thinking, remain uncertain. To bridge this gap, we introduce texttt{FinDABench}, a comprehensive benchmark designed to evaluate the financial data analysis capabilities of LLMs within this context. texttt{FinDABench} assesses LLMs across three dimensions: 1) textbf{Foundational Ability}, evaluating the models' ability to perform financial numerical calculation and corporate sentiment risk assessment; 2) textbf{Reasoning Ability}, determining the models' ability to quickly comprehend textual information and analyze abnormal financial reports; and 3) textbf{Technical Skill}, examining the models' use of technical knowledge to address real-world data analysis challenges involving analysis generation and charts visualization from multiple perspectives. We will release texttt{FinDABench}, and the evaluation scripts at url{https://github.com/cubenlp/BIBench}. texttt{FinDABench} aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of financial data analysis.
6/17/2024
🌀
FFN: a Fine-grained Chinese-English Financial Domain Parallel Corpus
Yuxin Fu, Shijing Si, Leyi Mai, Xi-ang Li
0
0
Large Language Models (LLMs) have stunningly advanced the field of machine translation, though their effectiveness within the financial domain remains largely underexplored. To probe this issue, we constructed a fine-grained Chinese-English parallel corpus of financial news called FFN. We acquired financial news articles spanning between January 1st, 2014, to December 31, 2023, from mainstream media websites such as CNN, FOX, and China Daily. The dataset consists of 1,013 main text and 809 titles, all of which have been manually corrected. We measured the translation quality of two LLMs -- ChatGPT and ERNIE-bot, utilizing BLEU, TER and chrF scores as the evaluation metrics. For comparison, we also trained an OpenNMT model based on our dataset. We detail problems of LLMs and provide in-depth analysis, intending to stimulate further research and solutions in this largely uncharted territory. Our research underlines the need to optimize LLMs within the specific field of financial translation to ensure accuracy and quality.
6/28/2024