Filter & Align: Curating Image-Text Data with Human Knowledge

0
📊
Sign in to get full access
Overview
- This paper provides guidelines for formatting author responses to peer reviews in the LaTeX typesetting system.
- Key topics covered include response length, formatting, and best practices for effectively responding to reviewer comments.
Plain English Explanation
The paper outlines guidelines for author responses when submitting papers using the LaTeX typesetting system. The main goal is to help authors format their responses in a clear and consistent way that is easy for reviewers to read and understand.
Some of the key points covered include:
- Response length - Recommendations on how long the response should be, typically around 1-2 pages.
- Formatting - Guidance on using proper LaTeX syntax, section headings, font styles, etc. to make the response visually appealing and well-structured.
- Best practices - Tips for effectively addressing reviewer comments, clarifying points, and providing additional context or analysis as needed.
The guidelines are intended to help authors create high-quality responses that clearly communicate their perspective and facilitate a productive dialogue with the paper's reviewers.
Technical Explanation
The paper provides detailed instructions for formatting author responses using LaTeX. It begins by discussing response length, recommending that responses be approximately 1-2 pages long. Longer responses may be appropriate in some cases, but authors are advised to be concise and focus on the most important points.
The bulk of the paper covers formatting guidelines for the response document. This includes using proper LaTeX syntax for sections, subsections, paragraphs, and other structural elements. The authors also recommend using standard font styles (e.g. bold, italic) to highlight key information and improve readability.
Finally, the paper discusses best practices for crafting an effective author response. This includes directly addressing each reviewer comment, providing additional context or analysis as needed, and maintaining a professional and constructive tone throughout.
Critical Analysis
The guidelines provided in this paper are generally well-reasoned and likely to be helpful for authors formatting LaTeX-based responses to peer reviews. The emphasis on concision, clear structure, and effective communication aligns with best practices for scientific writing and reviewer engagement.
One potential limitation is the LaTeX-centric focus, which may be less relevant for authors using other typesetting systems. While the general principles could still be applied, specific formatting instructions would need to be adapted.
Additionally, the paper does not address potential challenges that may arise when responding to critical or adversarial reviewer comments. Guidance on maintaining a constructive dialogue in the face of disagreement could be a valuable addition.
Overall, this paper provides a solid foundation for authors seeking to optimize the format and content of their peer review responses. Applying these guidelines can help ensure that the reviewer's time and effort is respected, and that the author's perspective is effectively conveyed.
Conclusion
This paper offers a comprehensive set of guidelines for formatting author responses in LaTeX, covering key aspects such as response length, document structure, and best practices for effective communication with reviewers. By following these recommendations, authors can create high-quality responses that are visually appealing, logically organized, and focused on addressing the most important points raised by the reviewers.
Adhering to these guidelines can help facilitate a productive dialogue, increase the likelihood of a favorable review outcome, and contribute to the overall quality and integrity of the peer review process. As such, this paper serves as a valuable resource for authors seeking to optimize their response preparation and submission.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Filter & Align: Curating Image-Text Data with Human Knowledge
Lei Zhang, Fangxun Shu, Tianyang Liu, Sucheng Ren, Hao Jiang, Cihang Xie
The increasing availability of image-text pairs has largely fueled the rapid advancement in vision-language foundation models. However, the vast scale of these datasets inevitably introduces significant variability in data quality, which can adversely affect the model performance. This highlights the critical role of data filtering, not only to enhance training efficiency but also to improve overall data quality. Existing methods typically rely on metrics such as CLIP Score and BLIP Score, which are derived from pre-trained models. However, these models are often trained on uncurated, noisy datasets, which can perpetuate errors and misalignments in the filtered dataset. We present a novel algorithm that incorporates human knowledge on image-text alignment to guide filtering vast corpus of web-crawled image-text datasets into a compact and high-quality form. To systemically capture human preferences on image-text alignments, we collect a diverse image-text dataset where each image is associated with multiple captions from various sources, and establish a comprehensive set of both subjective and objective criteria for critically guiding the alignment assessment from labelers. Additionally, we train a reward model on these human-preference annotations to internalize the nuanced human understanding of image-text alignment. The resulting reward model thus can act as a human-like referee to filter image-text pairs. Extensive experiments demonstrate that we can maintain, sometimes even improve, model performance while compressing the image-text datasets up to ~90%. An impressive example is that, by aggressively reducing the total training sample from 130M to only 15.5M, our BLIP-B/16 models consistently show an average improvement of 2.9% on retrieval tasks and 11.5% on captioning tasks compared to full-size-dataset counterparts.
Read more9/5/2024
0
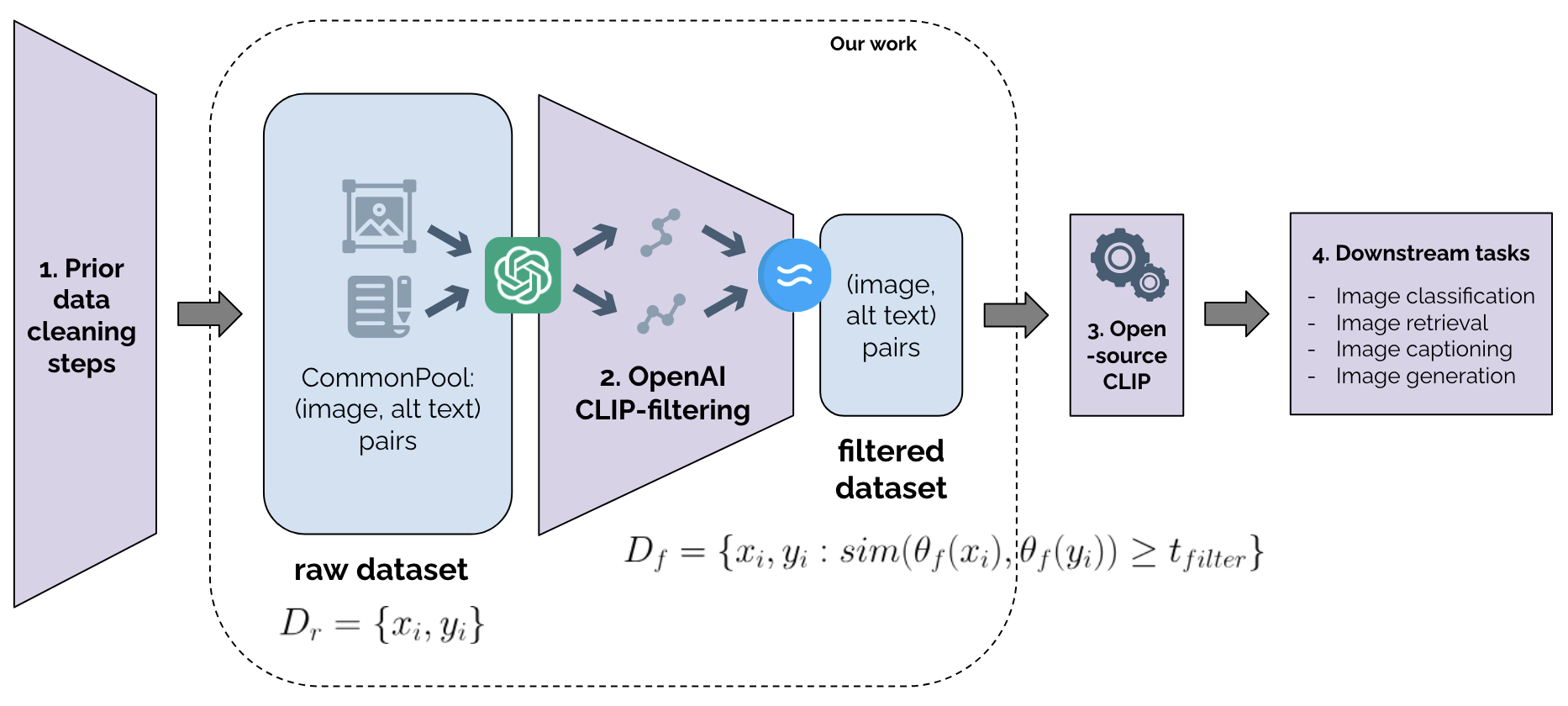
Who's in and who's out? A case study of multimodal CLIP-filtering in DataComp
Rachel Hong, William Agnew, Tadayoshi Kohno, Jamie Morgenstern
As training datasets become increasingly drawn from unstructured, uncontrolled environments such as the web, researchers and industry practitioners have increasingly relied upon data filtering techniques to filter out the noise of web-scraped data. While datasets have been widely shown to reflect the biases and values of their creators, in this paper we contribute to an emerging body of research that assesses the filters used to create these datasets. We show that image-text data filtering also has biases and is value-laden, encoding specific notions of what is counted as high-quality data. In our work, we audit a standard approach of image-text CLIP-filtering on the academic benchmark DataComp's CommonPool by analyzing discrepancies of filtering through various annotation techniques across multiple modalities of image, text, and website source. We find that data relating to several imputed demographic groups -- such as LGBTQ+ people, older women, and younger men -- are associated with higher rates of exclusion. Moreover, we demonstrate cases of exclusion amplification: not only are certain marginalized groups already underrepresented in the unfiltered data, but CLIP-filtering excludes data from these groups at higher rates. The data-filtering step in the machine learning pipeline can therefore exacerbate representation disparities already present in the data-gathering step, especially when existing filters are designed to optimize a specifically-chosen downstream performance metric like zero-shot image classification accuracy. Finally, we show that the NSFW filter fails to remove sexually-explicit content from CommonPool, and that CLIP-filtering includes several categories of copyrighted content at high rates. Our conclusions point to a need for fundamental changes in dataset creation and filtering practices.
Read more5/15/2024
👀
0
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
Read more6/3/2024

0
When Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection
Adam Goodge, Bryan Hooi, Wee Siong Ng
Contrastive Language-Image Pre-training (CLIP) achieves remarkable performance in various downstream tasks through the alignment of image and text input embeddings and holds great promise for anomaly detection. However, our empirical experiments show that the embeddings of text inputs unexpectedly tightly cluster together, far away from image embeddings, contrary to the model's contrastive training objective to align image-text input pairs. We show that this phenomenon induces a `similarity bias' - in which false negative and false positive errors occur due to bias in the similarities between images and the normal label text embeddings. To address this bias, we propose a novel methodology called BLISS which directly accounts for this similarity bias through the use of an auxiliary, external set of text inputs. BLISS is simple, it does not require strong inductive biases about anomalous behaviour nor an expensive training process, and it significantly outperforms baseline methods on benchmark image datasets, even when access to normal data is extremely limited.
Read more7/25/2024