When Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection

0

Sign in to get full access
Overview
- This paper introduces a method to correct for biases in language-image similarity scores used for anomaly detection.
- Anomaly detection is the task of identifying images that are significantly different from a dataset's norm.
- The proposed approach adjusts similarity scores to account for biases that can lead to inaccurate anomaly detection.
Plain English Explanation
Imagine you have a large collection of images, and you want to find the ones that are very different from the rest. This is called anomaly detection. One way to do this is to compare each image to the others using a "similarity score" - the higher the score, the more similar the images are.
However, the researchers found that these similarity scores can be biased, leading to inaccurate anomaly detection. For example, the scores might be influenced by the presence of text in the images, even though the text isn't the most important part.
To fix this, the researchers developed a new method to "correct" the similarity scores and remove these biases. This allows them to better identify the truly anomalous images in the dataset.
Technical Explanation
The paper proposes a method to bias-correct language-image similarity scores used for anomaly detection. Anomaly detection is the task of identifying images that are significantly different from the majority of a dataset.
The key insight is that existing language-image similarity models can be biased, leading to inaccurate anomaly detection. For example, the presence of text in an image can inflate its similarity score, even if the text is not the most important aspect.
To address this, the authors introduce a bias-correction module that adjusts the similarity scores to account for these biases. They train this module using a contrastive learning approach, which encourages the model to focus on the semantically relevant aspects of the image-text pairs.
The experiments show that the bias-corrected similarity scores lead to improved anomaly detection performance compared to the original, uncorrected scores.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing a real-world problem in the field of anomaly detection. The bias-correction module is a clever solution to a common issue with language-image similarity models.
However, the paper does not discuss potential limitations of the proposed method. For example, it's unclear how the approach would perform on datasets with different types of biases or on more complex anomaly detection tasks.
Additionally, the authors mention that their method relies on the availability of a large, diverse dataset for training the bias-correction module. In some real-world scenarios, such datasets may not be readily available.
Conclusion
This paper introduces an effective technique for improving anomaly detection by correcting biases in language-image similarity scores. The proposed method could have important applications in areas like image-based quality control, security, and content moderation. While the approach is well-designed, further research is needed to explore its limitations and generalizability to a wider range of scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection
Adam Goodge, Bryan Hooi, Wee Siong Ng
Contrastive Language-Image Pre-training (CLIP) achieves remarkable performance in various downstream tasks through the alignment of image and text input embeddings and holds great promise for anomaly detection. However, our empirical experiments show that the embeddings of text inputs unexpectedly tightly cluster together, far away from image embeddings, contrary to the model's contrastive training objective to align image-text input pairs. We show that this phenomenon induces a `similarity bias' - in which false negative and false positive errors occur due to bias in the similarities between images and the normal label text embeddings. To address this bias, we propose a novel methodology called BLISS which directly accounts for this similarity bias through the use of an auxiliary, external set of text inputs. BLISS is simple, it does not require strong inductive biases about anomalous behaviour nor an expensive training process, and it significantly outperforms baseline methods on benchmark image datasets, even when access to normal data is extremely limited.
Read more7/25/2024
0
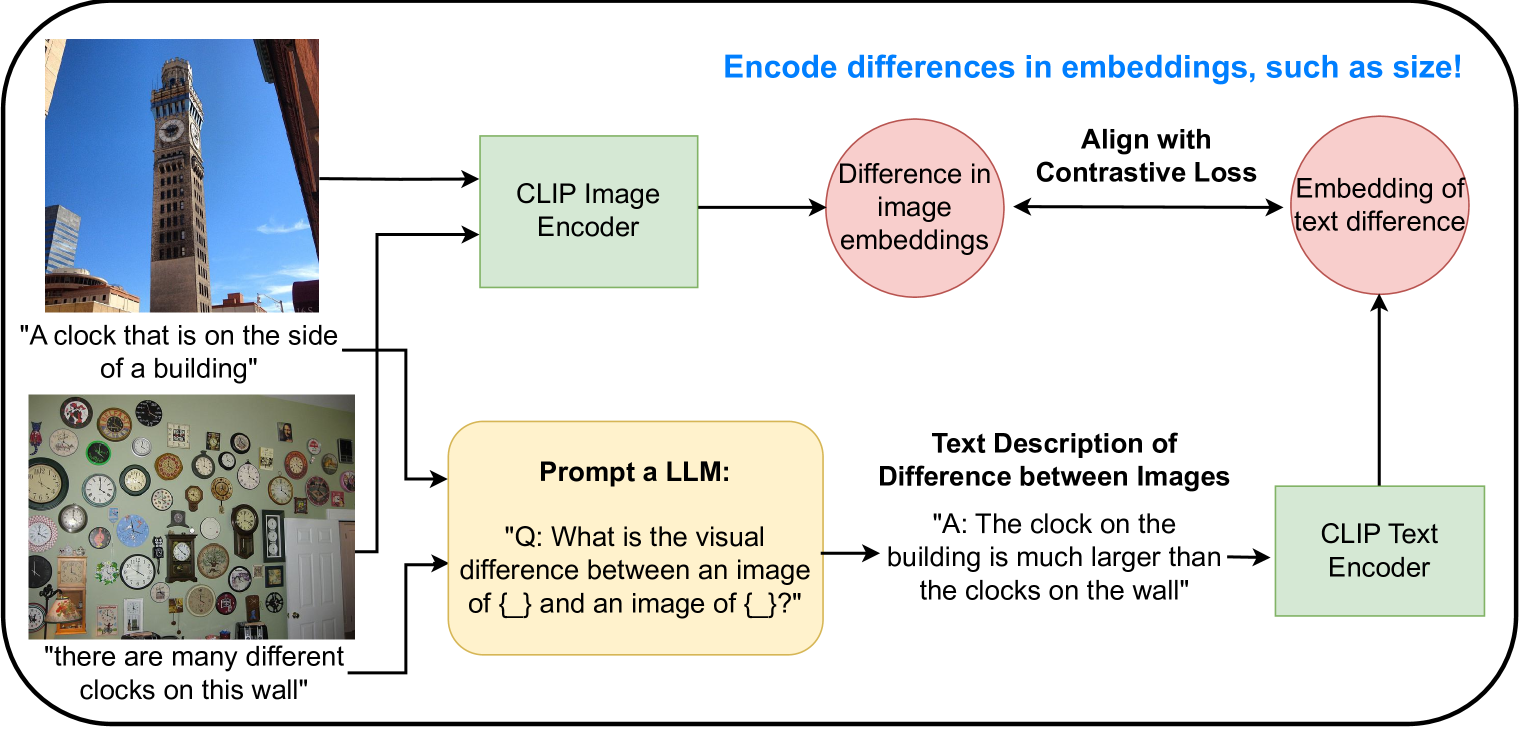
Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024

0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024