FinDABench: Benchmarking Financial Data Analysis Ability of Large Language Models
2401.02982
0
0
Abstract
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of financial data analysis, particularly focusing on data-driven thinking, remain uncertain. To bridge this gap, we introduce texttt{FinDABench}, a comprehensive benchmark designed to evaluate the financial data analysis capabilities of LLMs within this context. texttt{FinDABench} assesses LLMs across three dimensions: 1) textbf{Foundational Ability}, evaluating the models' ability to perform financial numerical calculation and corporate sentiment risk assessment; 2) textbf{Reasoning Ability}, determining the models' ability to quickly comprehend textual information and analyze abnormal financial reports; and 3) textbf{Technical Skill}, examining the models' use of technical knowledge to address real-world data analysis challenges involving analysis generation and charts visualization from multiple perspectives. We will release texttt{FinDABench}, and the evaluation scripts at url{https://github.com/cubenlp/BIBench}. texttt{FinDABench} aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of financial data analysis.
Create account to get full access
Overview
- The paper "BIBench: Benchmarking Data Analysis Knowledge of Large Language Models" explores the capabilities of large language models (LLMs) in performing data analysis tasks.
- The researchers developed BIBench, a comprehensive benchmark suite to assess the data analysis skills of LLMs across various domains, including statistics, data visualization, and causal inference.
- The study aims to provide a thorough evaluation of LLM performance on data-centric tasks, which is crucial as these models are increasingly being deployed in applications that require analytical capabilities.
Plain English Explanation
The paper examines how well large language models, such as GPT-3 and BERT, can perform data analysis tasks. These models are trained on vast amounts of text data and have shown impressive language understanding abilities. However, their skills in more technical areas, like statistics and causal inference, are less well-understood.
To address this, the researchers created a new benchmark called BIBench, which tests LLMs on a wide range of data analysis problems. The benchmark covers tasks like interpreting statistical results, creating data visualizations, and identifying causal relationships in data. By evaluating LLMs on these tasks, the researchers can better understand the models' analytical capabilities and limitations.
This is an important area of study as LLMs are increasingly being used in applications that require strong data analysis skills, such as financial risk prediction and fundamental knowledge assessment. Understanding the strengths and weaknesses of these models in data-centric tasks will help researchers and developers use them more effectively in real-world scenarios.
Technical Explanation
The researchers developed BIBench, a comprehensive benchmark suite to assess the data analysis capabilities of large language models (LLMs). BIBench covers a diverse set of tasks, including statistical analysis, data visualization, and causal inference, across various domains such as finance, healthcare, and social sciences.
To construct the benchmark, the researchers collected high-quality datasets from reputable sources and designed challenge-level prompts that require the models to demonstrate their understanding of data analysis concepts and techniques. For example, the statistical analysis tasks might ask the models to interpret the results of regression analyses or hypothesis tests, while the data visualization tasks might require the models to generate appropriate chart types and describe the insights they provide.
The researchers then evaluated the performance of several prominent LLMs, including GPT-3, BERT, and RoBERTa, on the BIBench tasks. The models were assessed on their ability to provide accurate, coherent, and informative responses to the prompts, with the researchers developing automated scoring systems to measure the quality of the models' outputs.
The results of the study revealed that while LLMs have made significant progress in natural language understanding and generation, they still struggle with certain data analysis tasks, particularly those involving causal reasoning and complex statistical concepts. The researchers also found that model performance varied significantly across different domains and task types, highlighting the need for further research and development to improve the data analysis capabilities of these large language models.
Critical Analysis
One of the key strengths of the BIBench study is its comprehensive and rigorous approach to evaluating LLM performance on data analysis tasks. By covering a diverse range of challenges across multiple domains, the researchers have provided a thorough assessment of the current capabilities and limitations of these models.
However, the study also acknowledges several limitations and areas for future research. For example, the researchers note that the BIBench datasets may not fully capture the complexity and nuance of real-world data analysis scenarios, and that the automated scoring systems used to evaluate model outputs may not always accurately reflect the quality of the responses.
Additionally, the study does not explore the potential of fine-tuning or specialized training approaches to improve LLM performance on data analysis tasks. It would be interesting to see if models trained on more domain-specific data or with additional data analysis-focused fine-tuning could achieve better results on the BIBench challenges.
Finally, the study does not delve into the potential societal implications of deploying LLMs in data-centric applications, such as concerns around bias and fairness. As these models become more widely used in areas like financial risk prediction and fundamental knowledge assessment, it will be crucial to carefully consider the ethical and societal impacts of their use.
Conclusion
The BIBench study provides a valuable contribution to the ongoing research on the data analysis capabilities of large language models. By developing a comprehensive benchmark suite and evaluating the performance of several prominent LLMs, the researchers have shed light on the current strengths and limitations of these models in handling data-centric tasks.
The findings of this study have important implications for the development and deployment of LLMs in real-world applications that require strong analytical skills, such as financial risk prediction, healthcare decision support, and policy analysis. As these models continue to advance, it will be essential for researchers and practitioners to carefully assess their capabilities and limitations to ensure they are used responsibly and effectively.
Overall, the BIBench study represents a significant step forward in understanding the data analysis skills of large language models, and it lays the groundwork for future research to further enhance the analytical capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Yang Lei, Jiangtong Li, Dawei Cheng, Zhijun Ding, Changjun Jiang
0
0
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
5/22/2024

New!Financial Knowledge Large Language Model
Cehao Yang, Chengjin Xu, Yiyan Qi
0
0
Artificial intelligence is making significant strides in the finance industry, revolutionizing how data is processed and interpreted. Among these technologies, large language models (LLMs) have demonstrated substantial potential to transform financial services by automating complex tasks, enhancing customer service, and providing detailed financial analysis. Firstly, we introduce IDEA-FinBench, an evaluation benchmark specifically tailored for assessing financial knowledge in large language models (LLMs). This benchmark utilizes questions from two globally respected and authoritative financial professional exams, aimimg to comprehensively evaluate the capability of LLMs to directly address exam questions pertinent to the finance sector. Secondly, we propose IDEA-FinKER, a Financial Knowledge Enhancement framework designed to facilitate the rapid adaptation of general LLMs to the financial domain, introducing a retrieval-based few-shot learning method for real-time context-level knowledge injection, and a set of high-quality financial knowledge instructions for fine-tuning any general LLM. Finally, we present IDEA-FinQA, a financial question-answering system powered by LLMs. This system is structured around a scheme of real-time knowledge injection and factual enhancement using external knowledge. IDEA-FinQA is comprised of three main modules: the data collector, the data querying module, and LLM-based agents tasked with specific functions.
7/2/2024
FinBen: A Holistic Financial Benchmark for Large Language Models
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, Zhiyang Deng, Yuechen Jiang, Zhiyuan Yao, Haohang Li, Yangyang Yu, Gang Hu, Jiajia Huang, Xiao-Yang Liu, Alejandro Lopez-Lira, Benyou Wang, Yanzhao Lai, Hao Wang, Min Peng, Sophia Ananiadou, Jimin Huang
0
0
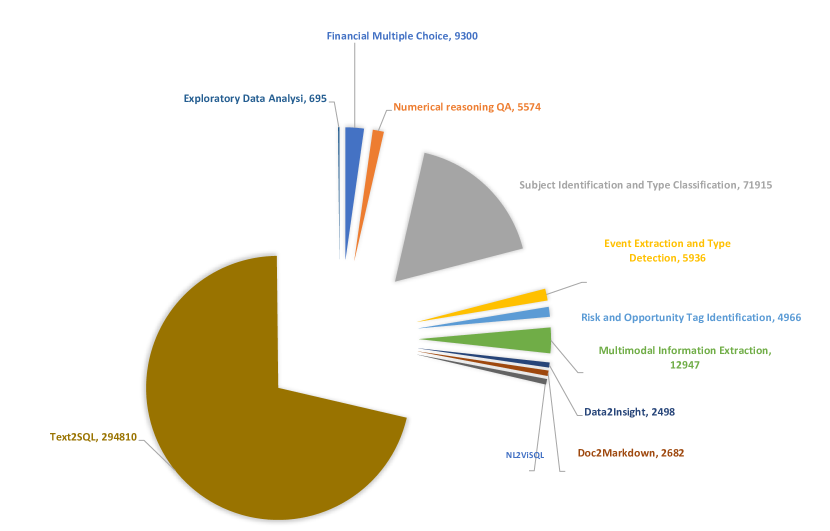
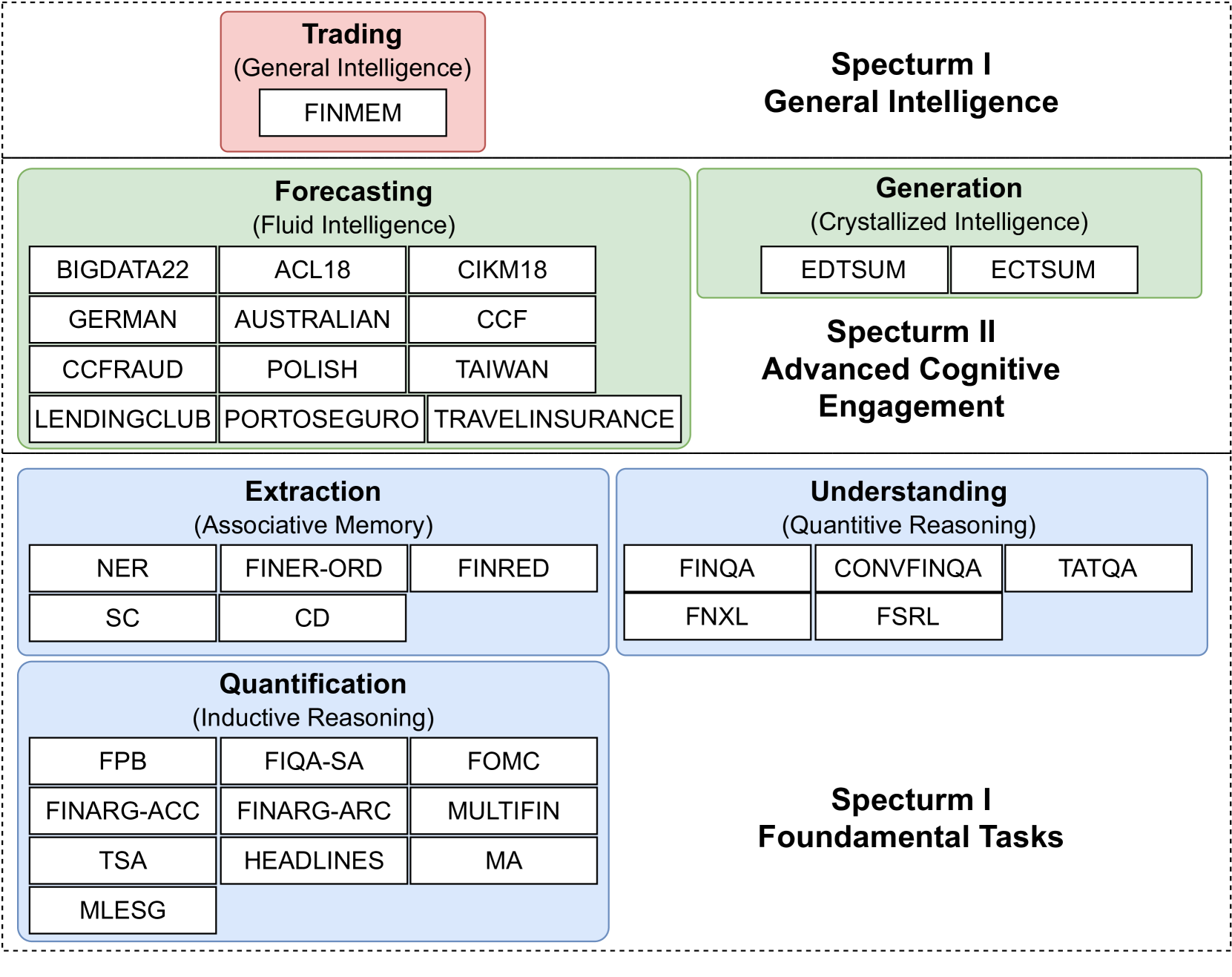
LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of comprehensive evaluation benchmarks, the rapid development of LLMs, and the complexity of financial tasks. In this paper, we introduce FinBen, the first extensive open-source evaluation benchmark, including 36 datasets spanning 24 financial tasks, covering seven critical aspects: information extraction (IE), textual analysis, question answering (QA), text generation, risk management, forecasting, and decision-making. FinBen offers several key innovations: a broader range of tasks and datasets, the first evaluation of stock trading, novel agent and Retrieval-Augmented Generation (RAG) evaluation, and three novel open-source evaluation datasets for text summarization, question answering, and stock trading. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals several key findings: While LLMs excel in IE and textual analysis, they struggle with advanced reasoning and complex tasks like text generation and forecasting. GPT-4 excels in IE and stock trading, while Gemini is better at text generation and forecasting. Instruction-tuned LLMs improve textual analysis but offer limited benefits for complex tasks such as QA. FinBen has been used to host the first financial LLMs shared task at the FinNLP-AgentScen workshop during IJCAI-2024, attracting 12 teams. Their novel solutions outperformed GPT-4, showcasing FinBen's potential to drive innovation in financial LLMs. All datasets, results, and codes are released for the research community: https://github.com/The-FinAI/PIXIU.
6/21/2024

FoundaBench: Evaluating Chinese Fundamental Knowledge Capabilities of Large Language Models
Wei Li, Ren Ma, Jiang Wu, Chenya Gu, Jiahui Peng, Jinyang Len, Songyang Zhang, Hang Yan, Dahua Lin, Conghui He
0
0
In the burgeoning field of large language models (LLMs), the assessment of fundamental knowledge remains a critical challenge, particularly for models tailored to Chinese language and culture. This paper introduces FoundaBench, a pioneering benchmark designed to rigorously evaluate the fundamental knowledge capabilities of Chinese LLMs. FoundaBench encompasses a diverse array of 3354 multiple-choice questions across common sense and K-12 educational subjects, meticulously curated to reflect the breadth and depth of everyday and academic knowledge. We present an extensive evaluation of 12 state-of-the-art LLMs using FoundaBench, employing both traditional assessment methods and our CircularEval protocol to mitigate potential biases in model responses. Our results highlight the superior performance of models pre-trained on Chinese corpora, and reveal a significant disparity between models' reasoning and memory recall capabilities. The insights gleaned from FoundaBench evaluations set a new standard for understanding the fundamental knowledge of LLMs, providing a robust framework for future advancements in the field.
4/30/2024