FinBen: A Holistic Financial Benchmark for Large Language Models

0
Sign in to get full access
Overview
- The paper introduces the FinBen, a comprehensive financial benchmark for evaluating the performance of large language models.
- The benchmark covers a wide range of financial tasks, including fundamental analysis, portfolio management, and macroeconomic forecasting.
- The goal is to provide a standardized and holistic assessment of a model's financial reasoning and decision-making capabilities.
Plain English Explanation
The FinBen is a new benchmark designed to test the financial skills of large language models. These are powerful AI systems that can understand and generate human-like text. The benchmark covers a variety of financial tasks, such as analyzing company financial statements, managing investment portfolios, and forecasting economic trends.
The idea is to provide a standardized way to measure how well these language models can reason about financial information and make informed decisions. This is important because financial tasks require a deep understanding of complex concepts and the ability to integrate information from multiple sources. The FinBen aims to be a comprehensive assessment that goes beyond just testing specific skills, but looks at a model's overall financial intelligence.
Technical Explanation
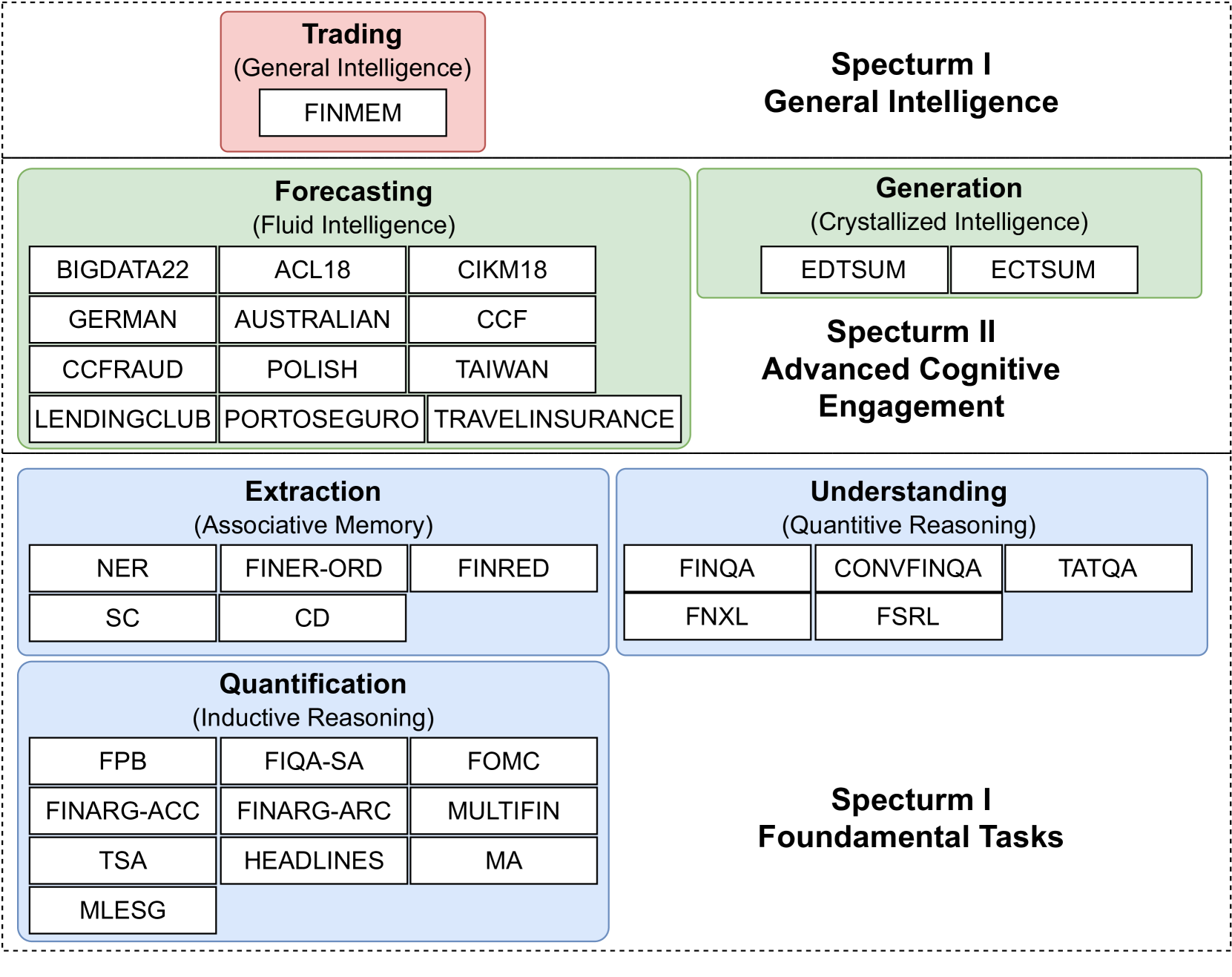
The FinBen is structured around three main "spectrums" of financial tasks:
-
Fundamental Tasks: This includes things like financial statement analysis, corporate valuation, and macroeconomic forecasting.
-
Portfolio Management: Tasks in this spectrum involve portfolio optimization, risk management, and investment decision-making.
-
Macroeconomic Analysis: Here, the benchmark tests a model's ability to analyze economic trends, understand monetary policy, and make projections about the broader economy.
Each spectrum contains a variety of subtasks and datasets that are designed to comprehensively evaluate a language model's financial reasoning capabilities. The benchmark uses both open-ended and multiple-choice question formats to assess different aspects of performance.
Critical Analysis
The FinBen appears to be a well-designed and comprehensive benchmark that addresses important gaps in existing financial AI evaluation frameworks. By covering a diverse set of financial tasks, it provides a more holistic assessment of a model's capabilities compared to narrowly focused benchmarks.
However, the paper acknowledges that the benchmark does not fully capture the real-world complexity of financial decision-making, which involves factors like uncertainty, incomplete information, and evolving market conditions. There is also the potential for language models to "game" the benchmark by exploiting biases in the datasets or question formats.
Additionally, the benchmark may not be equally relevant or accessible to all language models, as their pretraining data and architectures can vary significantly. Careful consideration of these limitations will be important when interpreting the results of the FinBen.
Conclusion
The FinBen represents an important step forward in developing robust and standardized benchmarks for evaluating the financial intelligence of large language models. By assessing a wide range of financial tasks, it provides a more comprehensive and nuanced understanding of a model's capabilities, which can inform their real-world applications in the financial sector.
As language models continue to advance, benchmarks like the FinBen will play a crucial role in driving progress and ensuring that these powerful AI systems are being developed and deployed responsibly in the domain of finance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FinBen: A Holistic Financial Benchmark for Large Language Models
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, Zhiyang Deng, Yuechen Jiang, Zhiyuan Yao, Haohang Li, Yangyang Yu, Gang Hu, Jiajia Huang, Xiao-Yang Liu, Alejandro Lopez-Lira, Benyou Wang, Yanzhao Lai, Hao Wang, Min Peng, Sophia Ananiadou, Jimin Huang
LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of comprehensive evaluation benchmarks, the rapid development of LLMs, and the complexity of financial tasks. In this paper, we introduce FinBen, the first extensive open-source evaluation benchmark, including 36 datasets spanning 24 financial tasks, covering seven critical aspects: information extraction (IE), textual analysis, question answering (QA), text generation, risk management, forecasting, and decision-making. FinBen offers several key innovations: a broader range of tasks and datasets, the first evaluation of stock trading, novel agent and Retrieval-Augmented Generation (RAG) evaluation, and three novel open-source evaluation datasets for text summarization, question answering, and stock trading. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals several key findings: While LLMs excel in IE and textual analysis, they struggle with advanced reasoning and complex tasks like text generation and forecasting. GPT-4 excels in IE and stock trading, while Gemini is better at text generation and forecasting. Instruction-tuned LLMs improve textual analysis but offer limited benefits for complex tasks such as QA. FinBen has been used to host the first financial LLMs shared task at the FinNLP-AgentScen workshop during IJCAI-2024, attracting 12 teams. Their novel solutions outperformed GPT-4, showcasing FinBen's potential to drive innovation in financial LLMs. All datasets, results, and codes are released for the research community: https://github.com/The-FinAI/PIXIU.
Read more6/21/2024
0
FinDABench: Benchmarking Financial Data Analysis Ability of Large Language Models
Shu Liu, Shangqing Zhao, Chenghao Jia, Xinlin Zhuang, Zhaoguang Long, Jie Zhou, Aimin Zhou, Man Lan, Qingquan Wu, Chong Yang
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. However, their proficiency and reliability in the specialized domain of financial data analysis, particularly focusing on data-driven thinking, remain uncertain. To bridge this gap, we introduce texttt{FinDABench}, a comprehensive benchmark designed to evaluate the financial data analysis capabilities of LLMs within this context. texttt{FinDABench} assesses LLMs across three dimensions: 1) textbf{Foundational Ability}, evaluating the models' ability to perform financial numerical calculation and corporate sentiment risk assessment; 2) textbf{Reasoning Ability}, determining the models' ability to quickly comprehend textual information and analyze abnormal financial reports; and 3) textbf{Technical Skill}, examining the models' use of technical knowledge to address real-world data analysis challenges involving analysis generation and charts visualization from multiple perspectives. We will release texttt{FinDABench}, and the evaluation scripts at url{https://github.com/cubenlp/BIBench}. texttt{FinDABench} aims to provide a measure for in-depth analysis of LLM abilities and foster the advancement of LLMs in the field of financial data analysis.
Read more6/17/2024

0
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Zhongshen Zeng, Yinhong Liu, Yingjia Wan, Jingyao Li, Pengguang Chen, Jianbo Dai, Yuxuan Yao, Rongwu Xu, Zehan Qi, Wanru Zhao, Linling Shen, Jianqiao Lu, Haochen Tan, Yukang Chen, Hao Zhang, Zhan Shi, Bailin Wang, Zhijiang Guo, Jiaya Jia
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
Read more6/21/2024
💬
0
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Seungone Kim, Juyoung Suk, Ji Yong Cho, Shayne Longpre, Chaeeun Kim, Dongkeun Yoon, Guijin Son, Yejin Cho, Sheikh Shafayat, Jinheon Baek, Sue Hyun Park, Hyeonbin Hwang, Jinkyung Jo, Hyowon Cho, Haebin Shin, Seongyun Lee, Hanseok Oh, Noah Lee, Namgyu Ho, Se June Joo, Miyoung Ko, Yoonjoo Lee, Hyungjoo Chae, Jamin Shin, Joel Jang, Seonghyeon Ye, Bill Yuchen Lin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, Minjoon Seo
As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Read more6/11/2024