Finding Replicable Human Evaluations via Stable Ranking Probability

0

Sign in to get full access
Overview
- This paper proposes a method for finding human evaluations that are likely to be replicable, based on the stability of the ranking probability.
- The researchers aim to address the challenge of inconsistent human evaluations by identifying reliable and consistent evaluation results.
- The key idea is to use "stable ranking probability" as a metric to assess the reliability of human evaluations, which can then be used to find the most replicable evaluations.
Plain English Explanation
The paper tackles the problem of inconsistent human evaluations, which can make it difficult to reliably compare the performance of different systems or approaches. Imagine you're evaluating a few different restaurant dishes and ask a group of people to rate them. You might find that the ratings vary a lot between individuals, making it hard to say with confidence which dish is truly the best.
The researchers propose a solution to this issue by focusing on the "stability" of the ranking probability. In other words, they look at how likely it is that the same ranking of options (e.g., dishes) would be produced if the evaluation was repeated. The more stable the ranking, the more confident we can be that the evaluation results are reliable and replicable.
To achieve this, the researchers developed a statistical method that can analyze the ranking data and identify the evaluations that have the highest "stable ranking probability." These are the evaluations that are most likely to be consistent and repeatable, even if the same set of people are asked to evaluate the options again.
By identifying the most replicable human evaluations, the researchers aim to provide a way for researchers and practitioners to have more confidence in the results of their studies and comparisons, leading to more robust and trustworthy insights.
Technical Explanation
The paper proposes a method for finding human evaluations that are likely to be replicable, based on the concept of "stable ranking probability." The key idea is to analyze the ranking data from human evaluations to identify the evaluations that have the highest probability of producing the same ranking if the evaluation was repeated.
The researchers first define the "stable ranking probability" as the probability that the same ranking of options would be produced in a repeated evaluation. They then develop a statistical model to estimate this probability from the available ranking data.
The model works by analyzing the ranking data to estimate the underlying "preference" of each individual for the different options. It then uses this information to calculate the probability that the observed ranking would be produced, and the probability that the same ranking would be produced in a repeated evaluation.
The researchers then use this stable ranking probability as a metric to identify the most replicable human evaluations. By focusing on the evaluations with the highest stable ranking probability, they can provide a way for researchers and practitioners to have more confidence in the reliability and consistency of the evaluation results.
The paper also includes several experiments and case studies to demonstrate the effectiveness of the proposed approach, showing that it can indeed identify the most replicable human evaluations and lead to more robust and trustworthy insights.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the challenge of inconsistent human evaluations. The focus on "stable ranking probability" as a metric for assessing the reliability of evaluations is a clever and intuitive idea, and the statistical model developed by the researchers appears to be a sound and principled way of estimating this metric from the available data.
One potential limitation of the approach is that it relies on the assumption that the underlying "preferences" of the individuals being evaluated are stable and consistent. In reality, human preferences can be influenced by a variety of factors, and may not always be as consistent as the model assumes. Additionally, the paper does not address the potential impact of factors such as sample size, demographic diversity, or task complexity on the stability of the rankings.
Another area for further research could be the exploration of alternative approaches to identifying replicable human evaluations, such as techniques from the field of decision theory or social choice theory. It would be interesting to see how the stable ranking probability approach compares to other methods in terms of accuracy, robustness, and practical applicability.
Overall, the paper presents a valuable contribution to the field of human evaluation and measurement, and the proposed method has the potential to significantly improve the reliability and trustworthiness of research and development in a wide range of domains.
Conclusion
This paper introduces a novel approach to identifying replicable human evaluations by focusing on the "stable ranking probability" of the evaluation results. By developing a statistical model to estimate this probability, the researchers have provided a practical tool for researchers and practitioners to assess the reliability and consistency of their human evaluation data.
The potential impact of this work is significant, as it could lead to more robust and trustworthy insights in a wide range of fields, from product development to social science research. By ensuring that the most replicable human evaluations are given the appropriate weight and consideration, the proposed method can help to improve the overall quality and reliability of research and decision-making.
While the paper does not address all of the potential limitations and challenges of the approach, it represents an important step forward in the ongoing efforts to improve the quality and reliability of human evaluation methods. As the field continues to evolve, it will be exciting to see how this work inspires further innovations and advancements in this critical area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Finding Replicable Human Evaluations via Stable Ranking Probability
Parker Riley, Daniel Deutsch, George Foster, Viresh Ratnakar, Ali Dabirmoghaddam, Markus Freitag
Reliable human evaluation is critical to the development of successful natural language generation models, but achieving it is notoriously difficult. Stability is a crucial requirement when ranking systems by quality: consistent ranking of systems across repeated evaluations is not just desirable, but essential. Without it, there is no reliable foundation for hill-climbing or product launch decisions. In this paper, we use machine translation and its state-of-the-art human evaluation framework, MQM, as a case study to understand how to set up reliable human evaluations that yield stable conclusions. We investigate the optimal configurations for item allocation to raters, number of ratings per item, and score normalization. Our study on two language pairs provides concrete recommendations for designing replicable human evaluation studies. We also collect and release the largest publicly available dataset of multi-segment translations rated by multiple professional translators, consisting of nearly 140,000 segment annotations across two language pairs.
Read more4/3/2024
💬
0
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
Read more5/24/2024
0
Ranking Generated Answers: On the Agreement of Retrieval Models with Humans on Consumer Health Questions
Sebastian Heineking, Jonas Probst, Daniel Steinbach, Martin Potthast, Harrisen Scells
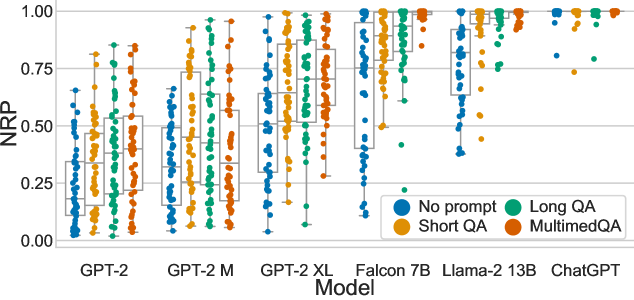
Evaluating the output of generative large language models (LLMs) is challenging and difficult to scale. Most evaluations of LLMs focus on tasks such as single-choice question-answering or text classification. These tasks are not suitable for assessing open-ended question-answering capabilities, which are critical in domains where expertise is required, such as health, and where misleading or incorrect answers can have a significant impact on a user's health. Using human experts to evaluate the quality of LLM answers is generally considered the gold standard, but expert annotation is costly and slow. We present a method for evaluating LLM answers that uses ranking signals as a substitute for explicit relevance judgements. Our scoring method correlates with the preferences of human experts. We validate it by investigating the well-known fact that the quality of generated answers improves with the size of the model as well as with more sophisticated prompting strategies.
Read more8/20/2024
0
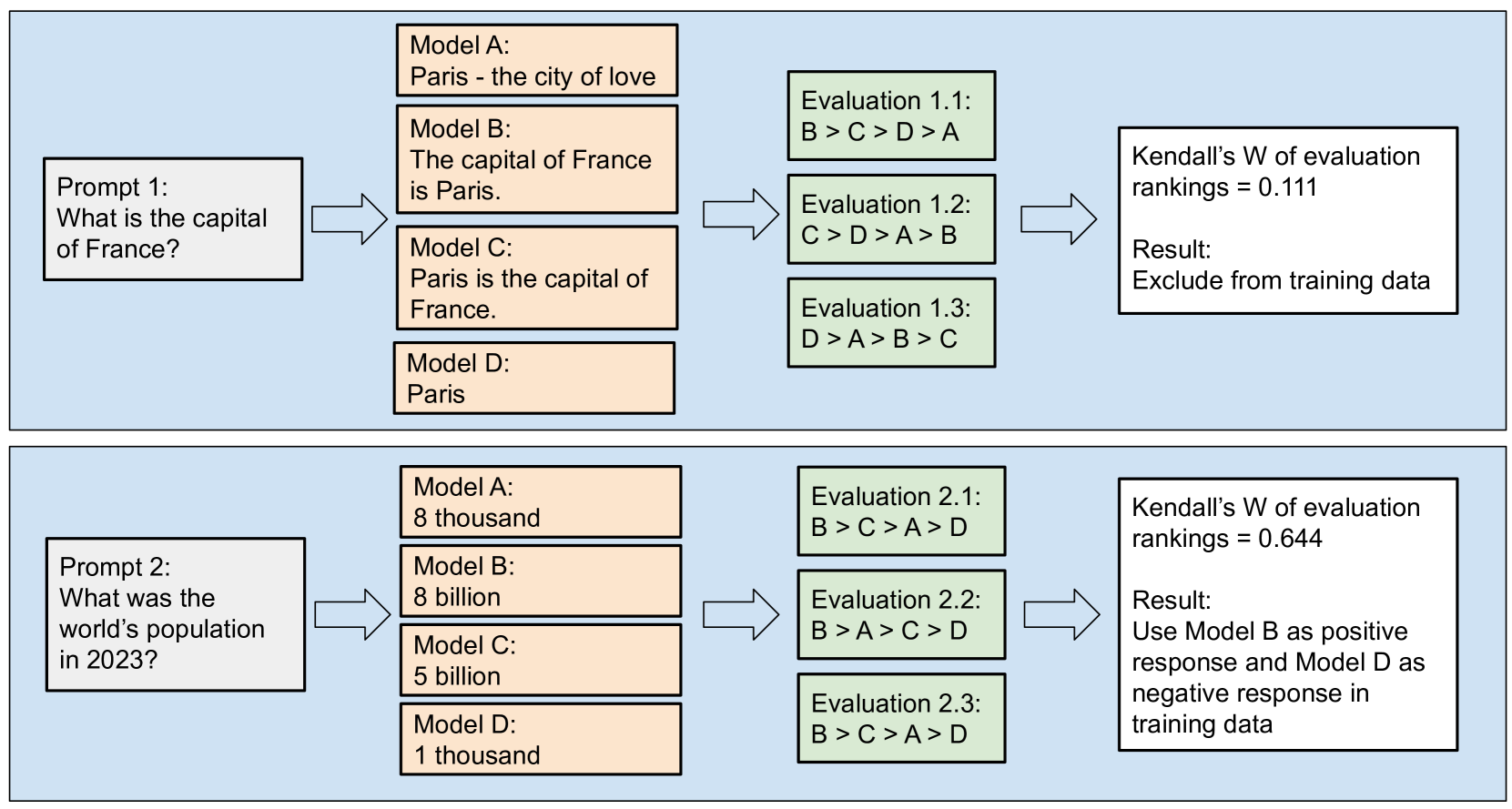
Are You Sure? Rank Them Again: Repeated Ranking For Better Preference Datasets
Peter Devine
Training Large Language Models (LLMs) with Reinforcement Learning from AI Feedback (RLAIF) aligns model outputs more closely with human preferences. This involves an evaluator model ranking multiple candidate responses to user prompts. However, the rankings from popular evaluator models such as GPT-4 can be inconsistent. We propose the Repeat Ranking method - where we evaluate the same responses multiple times and train only on those responses which are consistently ranked. Using 2,714 prompts in 62 languages, we generated responses from 7 top multilingual LLMs and had GPT-4 rank them five times each. Evaluating on MT-Bench chat benchmarks in six languages, our method outperformed the standard practice of training on all available prompts. Our work highlights the quality versus quantity trade-off in RLAIF dataset generation and offers a stackable strategy for enhancing dataset and thus model quality.
Read more6/4/2024