Are You Sure? Rank Them Again: Repeated Ranking For Better Preference Datasets
2405.18952
0
0
Abstract
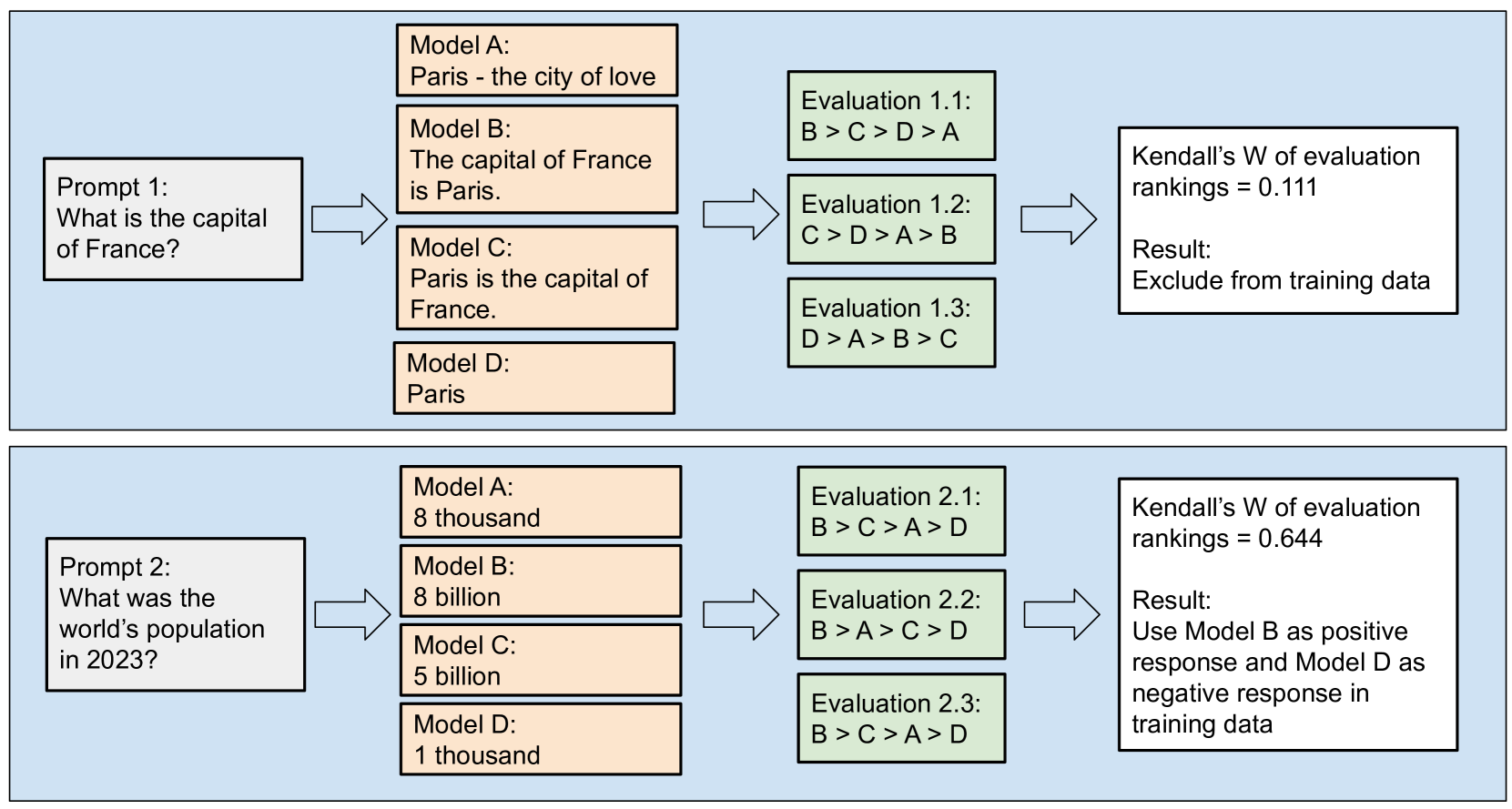
Training Large Language Models (LLMs) with Reinforcement Learning from AI Feedback (RLAIF) aligns model outputs more closely with human preferences. This involves an evaluator model ranking multiple candidate responses to user prompts. However, the rankings from popular evaluator models such as GPT-4 can be inconsistent. We propose the Repeat Ranking method - where we evaluate the same responses multiple times and train only on those responses which are consistently ranked. Using 2,714 prompts in 62 languages, we generated responses from 7 top multilingual LLMs and had GPT-4 rank them five times each. Evaluating on MT-Bench chat benchmarks in six languages, our method outperformed the standard practice of training on all available prompts. Our work highlights the quality versus quantity trade-off in RLAIF dataset generation and offers a stackable strategy for enhancing dataset and thus model quality.
Create account to get full access
Overview
- This paper proposes a novel approach called "Repeated Ranking" to improve the quality of preference datasets for machine learning models.
- The key idea is to have participants rank the same set of items multiple times, allowing the researchers to better understand the consistency and confidence in the participants' preferences.
- The authors conduct extensive experiments to validate the effectiveness of their approach and provide insights into the benefits of repeated ranking.
Plain English Explanation
The paper focuses on the challenge of collecting high-quality preference data for training machine learning models. Preference datasets, where people rank or rate a set of items, are crucial for building recommendation systems and other applications. However, people's preferences can be subjective and inconsistent, making it difficult to obtain reliable data.
The researchers' solution is to have participants rank the same set of items multiple times, rather than just asking them to rank it once. This "Repeated Ranking" approach allows the researchers to better understand how consistent each person's preferences are and how confident they are in their rankings.
By analyzing the repeated rankings, the researchers can identify items that participants are unsure about or rank inconsistently. This information can then be used to improve the dataset, either by removing unreliable data or by gathering more information from the participants to clarify their preferences.
The authors demonstrate the benefits of Repeated Ranking through extensive experiments, showing that it leads to better-quality preference datasets that can in turn improve the performance of machine learning models. This work has important implications for the development of prediction-powered ranking systems using large language models, evaluating the ability of large language models to accurately predict searcher preferences, and enabling weak language models to better judge the reliability of their responses.
Technical Explanation
The paper introduces a new approach called "Repeated Ranking" to improve the quality of preference datasets. In a traditional preference dataset, participants are asked to rank a set of items once, based on their preferences. However, people's preferences can be subjective and inconsistent, leading to noisy and unreliable data.
To address this issue, the authors propose having participants rank the same set of items multiple times. By analyzing the repeated rankings, the researchers can identify items that participants are unsure about or rank inconsistently. This information can then be used to improve the dataset, either by removing unreliable data or by gathering more information from the participants to clarify their preferences.
The authors conduct extensive experiments to validate the effectiveness of their Repeated Ranking approach. They compare the quality of preference datasets obtained through traditional single ranking and their Repeated Ranking method, using both synthetic and real-world datasets. The results show that Repeated Ranking leads to better-quality preference datasets, which in turn improve the performance of machine learning models trained on the data.
The paper also provides insights into the benefits of Repeated Ranking, such as its ability to identify weak signals in large language model outputs to enable better judgments of response reliability and its potential applications in automatic evaluation of language models as conversational assistants.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear explanation of the Repeated Ranking approach and its benefits. However, there are a few potential limitations and areas for further research:
-
The paper focuses on the collection of preference data, but does not delve into how the repeated ranking information can be best utilized by machine learning models. Further research could explore techniques for leveraging this data to improve the performance of prediction-powered ranking models or large language models' ability to accurately predict searcher preferences.
-
The experiments in the paper are limited to relatively small-scale datasets. It would be valuable to see how the Repeated Ranking approach scales to larger, more complex preference datasets, and whether there are any practical challenges or limitations that arise.
-
The paper does not address the potential burden on participants of having to rank the same items multiple times. Further research could explore ways to minimize this burden, such as by only requiring repeated ranking for a subset of the items or by incorporating the repeated ranking process into the normal user experience.
Overall, the paper presents a promising approach to improving the quality of preference datasets, with valuable insights and a solid experimental foundation. The potential applications and further research directions suggested in the paper indicate the broader significance of this work for the field of machine learning and its real-world applications.
Conclusion
The "Are You Sure? Rank Them Again: Repeated Ranking For Better Preference Datasets" paper introduces a novel approach called Repeated Ranking to address the challenge of collecting high-quality preference data for machine learning models. By having participants rank the same set of items multiple times, the researchers can better understand the consistency and confidence in the participants' preferences, allowing them to improve the resulting preference datasets.
The authors' extensive experiments demonstrate the benefits of Repeated Ranking, showing that it leads to better-quality preference data that can enhance the performance of machine learning models. This work has important implications for the development of prediction-powered ranking systems using large language models, evaluating the ability of large language models to accurately predict searcher preferences, and enabling weak language models to better judge the reliability of their responses.
While the paper presents a well-designed and promising approach, there are a few potential limitations and areas for further research, such as exploring how the repeated ranking data can be best utilized by machine learning models and investigating the scalability of the approach to larger, more complex preference datasets. Overall, this work makes a valuable contribution to the field of machine learning and has the potential to significantly improve the quality of preference data used in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
0
0
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
5/24/2024
Ranking Large Language Models without Ground Truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
0
0
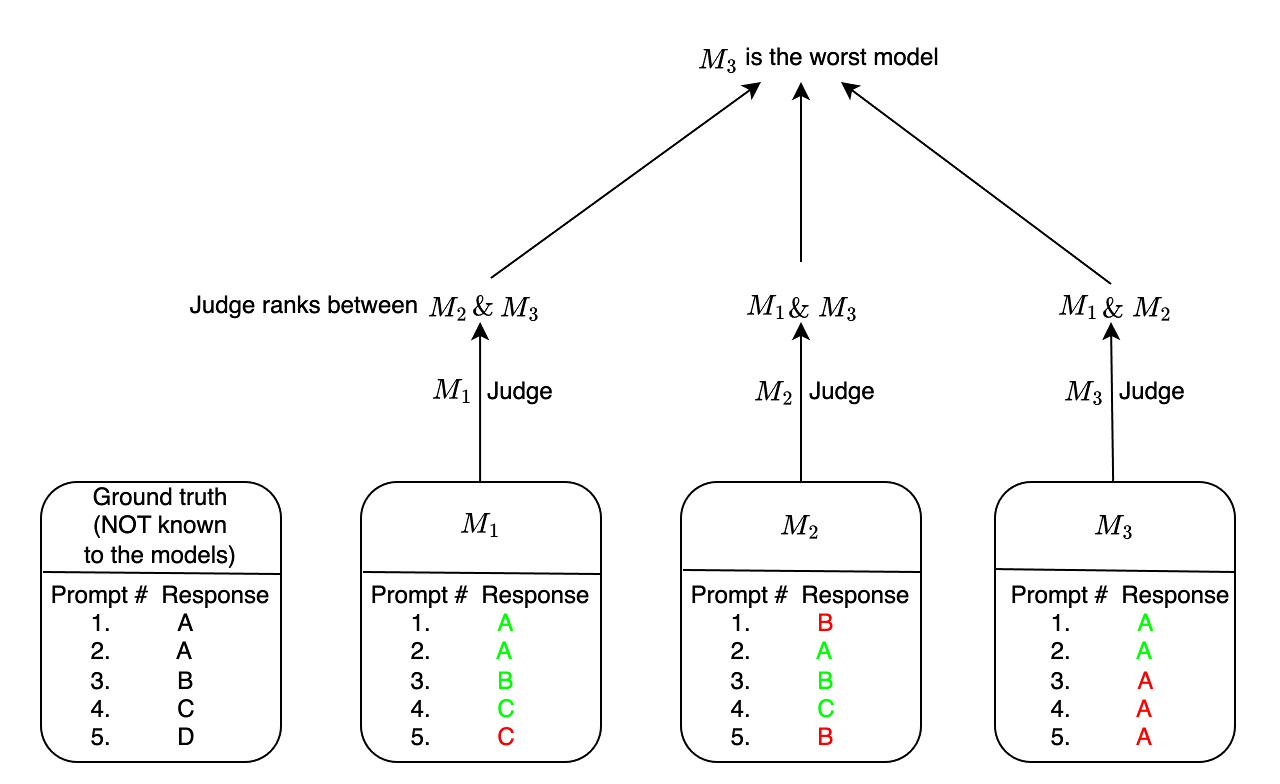
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
6/11/2024
Large language models can accurately predict searcher preferences
Paul Thomas, Seth Spielman, Nick Craswell, Bhaskar Mitra
0
0
Relevance labels, which indicate whether a search result is valuable to a searcher, are key to evaluating and optimising search systems. The best way to capture the true preferences of users is to ask them for their careful feedback on which results would be useful, but this approach does not scale to produce a large number of labels. Getting relevance labels at scale is usually done with third-party labellers, who judge on behalf of the user, but there is a risk of low-quality data if the labeller doesn't understand user needs. To improve quality, one standard approach is to study real users through interviews, user studies and direct feedback, find areas where labels are systematically disagreeing with users, then educate labellers about user needs through judging guidelines, training and monitoring. This paper introduces an alternate approach for improving label quality. It takes careful feedback from real users, which by definition is the highest-quality first-party gold data that can be derived, and develops an large language model prompt that agrees with that data. We present ideas and observations from deploying language models for large-scale relevance labelling at Bing, and illustrate with data from TREC. We have found large language models can be effective, with accuracy as good as human labellers and similar capability to pick the hardest queries, best runs, and best groups. Systematic changes to the prompts make a difference in accuracy, but so too do simple paraphrases. To measure agreement with real searchers needs high-quality gold labels, but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.
5/20/2024

APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Can Jin, Hongwu Peng, Shiyu Zhao, Zhenting Wang, Wujiang Xu, Ligong Han, Jiahui Zhao, Kai Zhong, Sanguthevar Rajasekaran, Dimitris N. Metaxas
0
0
Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
6/21/2024