Fine-tuned network relies on generic representation to solve unseen cognitive task
2406.18926
0
0
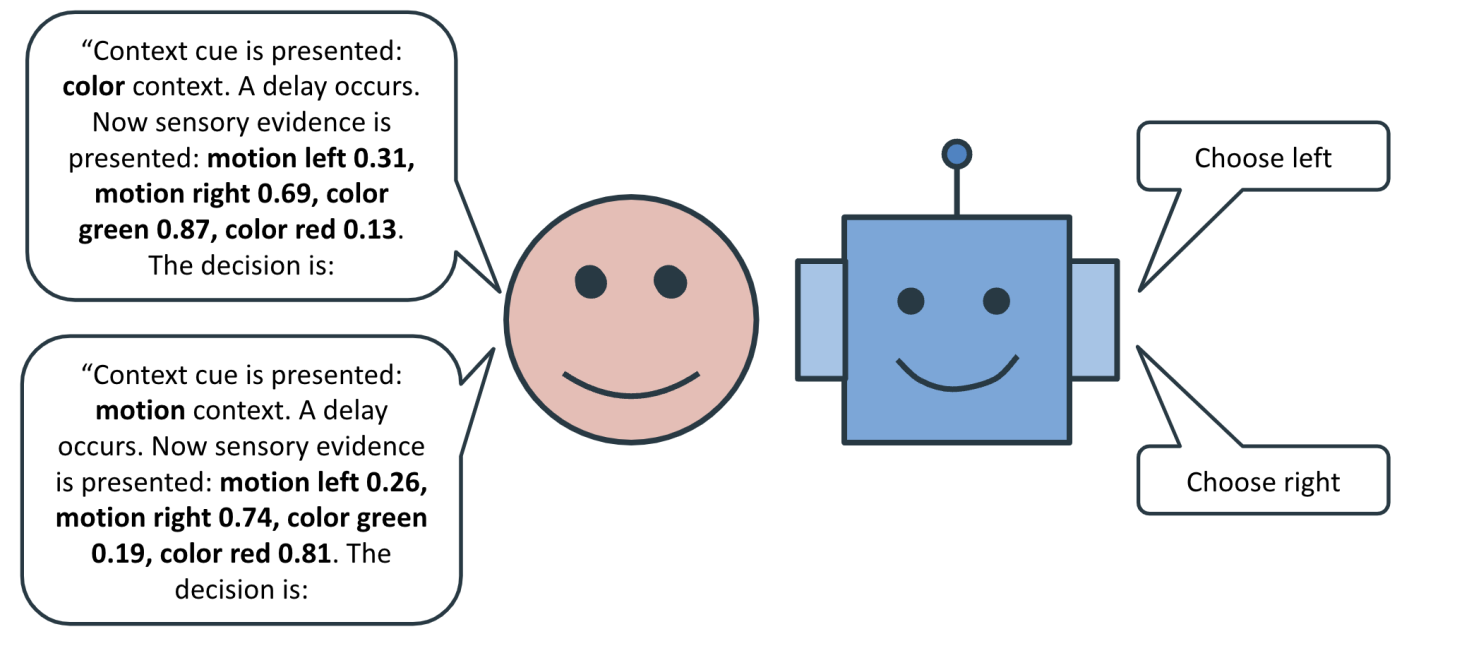
Abstract
Fine-tuning pretrained language models has shown promising results on a wide range of tasks, but when encountering a novel task, do they rely more on generic pretrained representation, or develop brand new task-specific solutions? Here, we fine-tuned GPT-2 on a context-dependent decision-making task, novel to the model but adapted from neuroscience literature. We compared its performance and internal mechanisms to a version of GPT-2 trained from scratch on the same task. Our results show that fine-tuned models depend heavily on pretrained representations, particularly in later layers, while models trained from scratch develop different, more task-specific mechanisms. These findings highlight the advantages and limitations of pretraining for task generalization and underscore the need for further investigation into the mechanisms underpinning task-specific fine-tuning in LLMs.
Create account to get full access
Overview
- This paper examines how a neural network fine-tuned for a specific task can leverage its generic representation to solve a previously unseen cognitive task.
- The researchers investigate the mechanisms behind this transfer of learning, providing insights into the nature of generic representations in deep neural networks.
- The findings have implications for understanding the flexibility and generalization capabilities of AI systems, as well as their potential applications in cognitive science and computational neuroscience.
Plain English Explanation
Neural networks can be "fine-tuned" - trained on a specific task using a smaller dataset - to perform well on that task. But this paper shows that a fine-tuned network can also use its general knowledge to solve a completely new task it wasn't trained on.
The researchers trained a neural network on a set of cognitive tasks, then fine-tuned it on a particular task. They found that even though the network was optimized for that one task, it could still use its learned, general understanding to solve a different, never-before-seen task.
This suggests that fine-tuned neural networks don't just memorize a specific solution. Instead, they develop a more flexible, generic representation of the problem that allows them to adapt to new situations. This ability to transfer learning is important for making AI systems that can be applied broadly, rather than being narrowly constrained.
The findings provide insights into how the human brain might work - our general knowledge and problem-solving skills allow us to tackle novel challenges, not just repeat memorized responses. Understanding these mechanisms in AI systems could lead to more human-like cognitive capabilities.
Technical Explanation
The researchers trained a transformer-based neural network on a set of cognitive tasks, then fine-tuned it on a specific task. They found that even after this fine-tuning process, the network was still able to leverage its general learned representation to solve a completely new, unseen task.
This suggests the network did not simply memorize a specific solution during fine-tuning. Rather, it developed a more flexible, abstract understanding that allowed it to adapt and generalize. This contrasts with the common view that fine-tuning leads to overly specialized performance at the expense of broader capabilities.
The researchers analyzed the network's internal representations and found that the fine-tuned model maintained a significant amount of its generic, task-agnostic knowledge. This generic representation allowed the network to transfer its learning to the novel task, rather than relying solely on the specific skills acquired during fine-tuning.
These findings have implications for understanding intelligence and the nature of representation in artificial neural networks. They suggest that fine-tuning can lead to flexible, generalizable models, rather than narrowly specialized ones. This could enable more human-like cognitive capabilities in AI systems.
Critical Analysis
The paper provides a convincing demonstration of how fine-tuned neural networks can maintain and leverage generic representations to solve unseen cognitive tasks. However, the researchers acknowledge that their findings are specific to the particular tasks and architectures studied.
It remains to be seen whether these results extend to a broader range of cognitive domains and network types. The heuristic core understanding of how fine-tuning preserves generic representations could also benefit from further investigation and validation.
Additionally, the paper does not explore the limits or failure modes of this transfer of learning. There may be cases where fine-tuning leads to overly specialized models that struggle with novel tasks, despite the general insights presented here.
Overall, this research provides an important counterpoint to the view that fine-tuning inevitably leads to brittle, narrow AI systems. By highlighting the potential for flexible, generalizable representations, it opens up new avenues for developing more robust and adaptable AI capabilities.
Conclusion
This paper offers a nuanced perspective on the effects of fine-tuning neural networks for specific tasks. Rather than leading to overly specialized models, the researchers show that fine-tuning can preserve a network's generic representational capabilities, allowing it to solve previously unseen cognitive challenges.
These findings contribute to our understanding of how artificial intelligence systems can develop flexible, human-like problem-solving skills. By studying the mechanisms underlying this transfer of learning, the research has implications for advancing the state of the art in computational neuroscience and cognitive science.
While the results are promising, further investigation is needed to fully characterize the limitations and boundary conditions of this phenomenon. Nonetheless, this work challenges the common perception of fine-tuning as a technique that inevitably compromises a model's broader applicability, offering a more optimistic view of the potential for fine-tuned AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
New!Fine-tuning can cripple your foundation model; preserving features may be the solution
Jishnu Mukhoti, Yarin Gal, Philip H. S. Torr, Puneet K. Dokania
0
0
Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon ''concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called $textit{LDIFS}$ (short for $ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that $textit{LDIFS}$ significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.
7/2/2024
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
0
0
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
7/2/2024
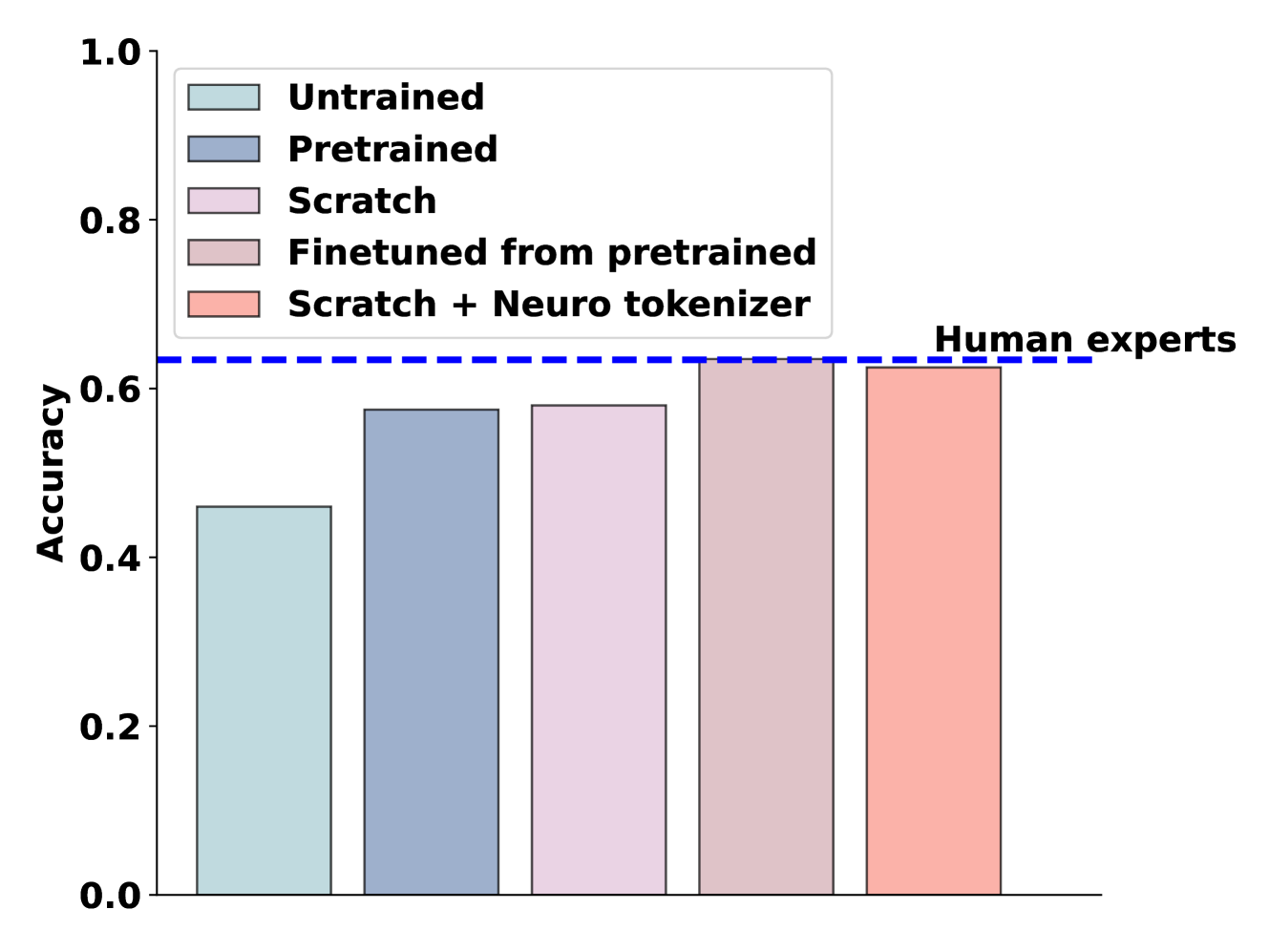
Matching domain experts by training from scratch on domain knowledge
Xiaoliang Luo, Guangzhi Sun, Bradley C. Love
0
0
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
5/16/2024
📈
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Vi'egas, Hanspeter Pfister, Martin Wattenberg
0
0
Language models show a surprising range of capabilities, but the source of their apparent competence is unclear. Do these networks just memorize a collection of surface statistics, or do they rely on internal representations of the process that generates the sequences they see? We investigate this question by applying a variant of the GPT model to the task of predicting legal moves in a simple board game, Othello. Although the network has no a priori knowledge of the game or its rules, we uncover evidence of an emergent nonlinear internal representation of the board state. Interventional experiments indicate this representation can be used to control the output of the network and create latent saliency maps that can help explain predictions in human terms.
6/27/2024