Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment

0

Sign in to get full access
Overview
- The paper focuses on optimizing CLIP models for image retrieval while maintaining their joint-embedding alignment.
- CLIP models are a type of multimodal neural network that can learn joint representations of images and text.
- The researchers propose a method to fine-tune CLIP models for improved image retrieval performance without compromising their joint-embedding alignment.
Plain English Explanation
The paper is about improving the performance of CLIP models for the task of image retrieval. CLIP models are a type of artificial intelligence that can understand both images and text, allowing them to perform tasks like matching images to relevant text descriptions.
The researchers found that when CLIP models are fine-tuned (further trained) for image retrieval, their ability to align images and text can sometimes be compromised. This means the model may not be as good at understanding the relationship between an image and its description after the fine-tuning process.
To address this, the researchers developed a new method to fine-tune CLIP models for image retrieval while maintaining the alignment between the image and text representations. This allows the models to be optimized for image retrieval without losing their core understanding of the connection between visual and textual information.
Technical Explanation
The paper proposes a fine-tuning approach for CLIP models to improve their performance on image retrieval tasks, while preserving the joint-embedding alignment between the image and text representations.
The researchers note that when CLIP models are fine-tuned for specific tasks like image retrieval, their ability to align the image and text embeddings can degrade. This alignment is a key property of CLIP models that allows them to excel at multimodal tasks.
To address this, the researchers introduce a contrastive loss function that encourages the fine-tuned model to maintain the joint-embedding alignment, in addition to optimizing for the image retrieval objective. This loss function is applied alongside the standard image retrieval loss during the fine-tuning process.
The paper also explores different architectural modifications, such as adding an additional projection head to the image encoder, to further improve the fine-tuned model's performance on image retrieval while preserving the joint-embedding alignment.
The researchers evaluate their approach on several standard image retrieval benchmarks and demonstrate that their method can improve image retrieval performance while maintaining the CLIP model's joint-embedding alignment, which is crucial for its generalization to other multimodal tasks.
Critical Analysis
The paper presents a well-designed approach to fine-tune CLIP models for image retrieval, addressing an important limitation of previous fine-tuning methods. The preservation of joint-embedding alignment is a valuable contribution, as it allows CLIP models to retain their strong multimodal capabilities even when optimized for a specific task.
However, the paper does not discuss potential limitations or caveats of the proposed approach. For example, it is unclear how the method would scale to larger, more complex CLIP models or datasets. Additionally, the paper could have explored the trade-offs between retrieval performance and the degree of alignment preservation, as these two objectives may not always be perfectly aligned.
Future research could investigate alternative fine-tuning strategies or architectural modifications that could further improve the balance between retrieval performance and alignment preservation. Exploring the generalization of the fine-tuned models to other multimodal tasks would also be a valuable direction.
Conclusion
This paper presents a novel approach to fine-tuning CLIP models for image retrieval while maintaining their joint-embedding alignment. By introducing a contrastive loss function and exploring architectural modifications, the researchers demonstrate how to optimize CLIP models for image retrieval without compromising their core multimodal capabilities.
This work has important implications for the practical application of CLIP models, as it allows them to be tailored to specific tasks while preserving their general-purpose feature extraction abilities. The proposed methods could be valuable for a wide range of multimodal applications, such as interactive fine-tuning of text-image models or robust vision-language representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024

0
Jina CLIP: Your CLIP Model Is Also Your Text Retriever
Andreas Koukounas, Georgios Mastrapas, Michael Gunther, Bo Wang, Scott Martens, Isabelle Mohr, Saba Sturua, Mohammad Kalim Akram, Joan Fontanals Mart'inez, Saahil Ognawala, Susana Guzman, Maximilian Werk, Nan Wang, Han Xiao
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.
Read more6/27/2024
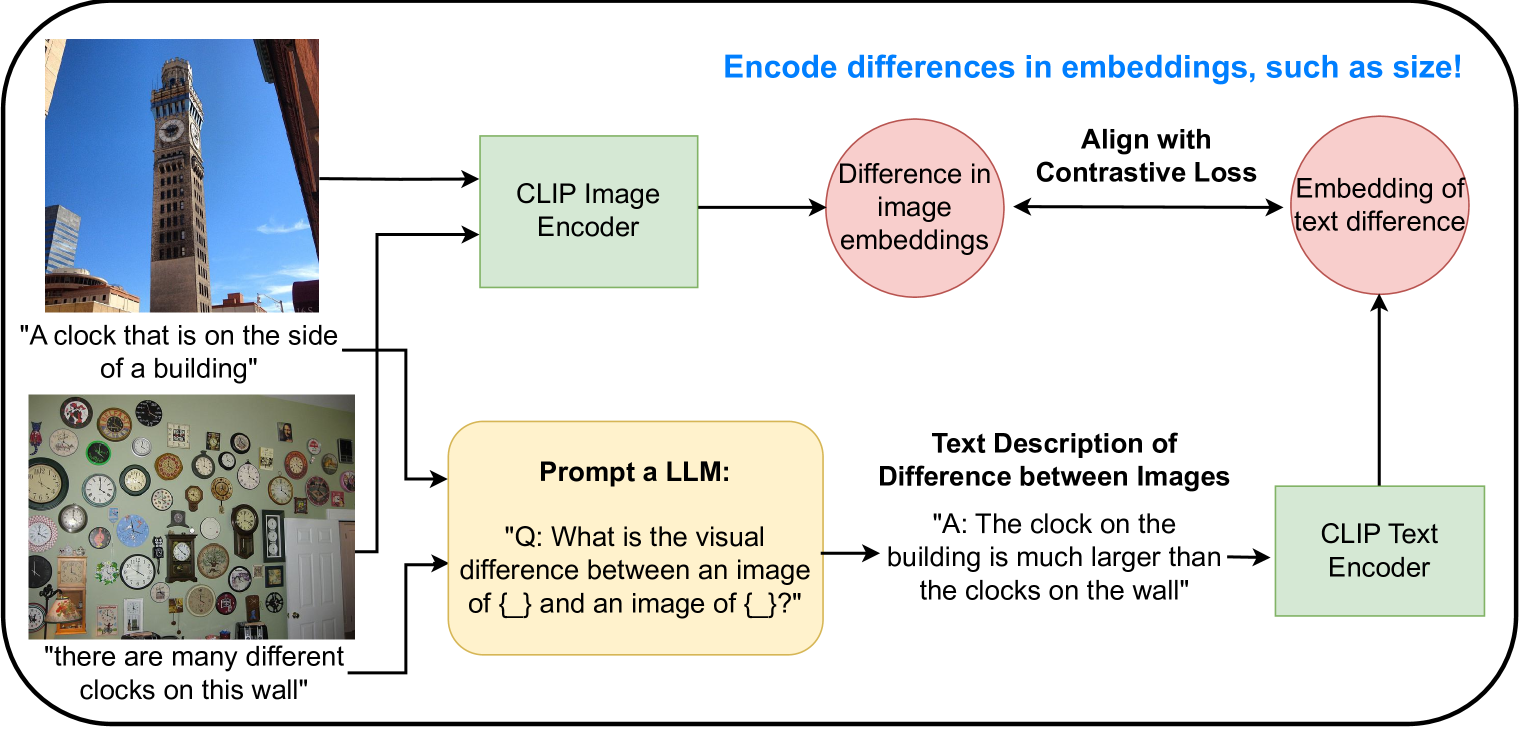
0
New!Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024