Finetuning Language Models to Emit Linguistic Expressions of Uncertainty

0
Sign in to get full access
Overview
- Researchers explored methods to fine-tune large language models to emit linguistic expressions of uncertainty, rather than just providing point estimates.
- The goal was to enable language models to convey the reliability and confidence of their outputs, which is important for their safe and responsible deployment.
- The researchers experimented with different fine-tuning approaches and evaluated the model's ability to express uncertainty using both automatic and human evaluation metrics.
Plain English Explanation
When large language models like GPT-3 generate text, they often provide a single, definitive output without any indication of how confident they are in that output. However, in many real-world applications, it's important for these models to be able to convey the reliability and uncertainty of their predictions.
This research explores ways to fine-tune or modify these large language models so that they can produce linguistic expressions of uncertainty, such as "I think...", "It's possible that...", or "I'm not sure, but..." This allows the model to communicate the level of confidence it has in its generated text, rather than just providing a single, certain output.
By fine-tuning the models in this way, the researchers aimed to make the models' outputs more transparent and trustworthy, which is crucial for the safe and responsible deployment of these powerful AI systems. The study evaluated different fine-tuning approaches to see which ones were most effective at enabling the models to express appropriate levels of uncertainty.
Technical Explanation
The researchers experimented with several fine-tuning approaches to imbue large language models with the ability to express linguistic uncertainty:
-
Uncertainty Token Fine-tuning: The model was fine-tuned on a dataset of text containing uncertainty expressions, teaching it to generate those expressions in appropriate contexts.
-
Confidence Prediction Fine-tuning: The model was trained to predict a confidence score alongside its text outputs, which could then be mapped to uncertainty expressions.
-
Contrastive Fine-tuning: The model was trained to distinguish certain from uncertain statements, learning to generate appropriate uncertainty markers.
The researchers evaluated the fine-tuned models using both automatic metrics (e.g., perplexity, F1 score) and human evaluation, assessing the models' ability to express uncertainty in a natural and coherent manner. The results showed that the fine-tuning approaches were effective in enabling the language models to convey uncertainty, with the contrastive fine-tuning approach performing particularly well.
Critical Analysis
The researchers acknowledge several limitations and areas for further research:
- The fine-tuning datasets used were relatively small, and the researchers suggest that larger, more diverse datasets may be needed to fully capture the nuances of expressing uncertainty.
- The evaluation primarily focused on the linguistic expressions of uncertainty, but did not assess the actual reliability or accuracy of the models' outputs. Further research is needed to understand how well the uncertainty expressions align with the models' true confidence levels.
- The study only examined fine-tuning approaches, and other architectural or training modifications may be needed to fully integrate uncertainty modeling into large language models.
Additionally, while the research represents an important step towards more transparent and trustworthy language models, there are still substantial challenges in ensuring that these models can reliably and accurately convey their level of confidence, especially in high-stakes applications.
Conclusion
This research demonstrates that it is possible to fine-tune large language models to emit linguistic expressions of uncertainty, which is a crucial capability for the safe and responsible deployment of these powerful AI systems. By enabling language models to communicate the reliability and confidence of their outputs, the research paves the way for more transparent and trustworthy AI assistants and applications. However, further work is needed to fully integrate uncertainty modeling into language models and ensure that their expressed uncertainty aligns with their actual capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty
Arslan Chaudhry, Sridhar Thiagarajan, Dilan Gorur
Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.
Read more9/19/2024

0
Large Language Models Must Be Taught to Know What They Don't Know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, Andrew Gordon Wilson
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
Read more6/13/2024
0
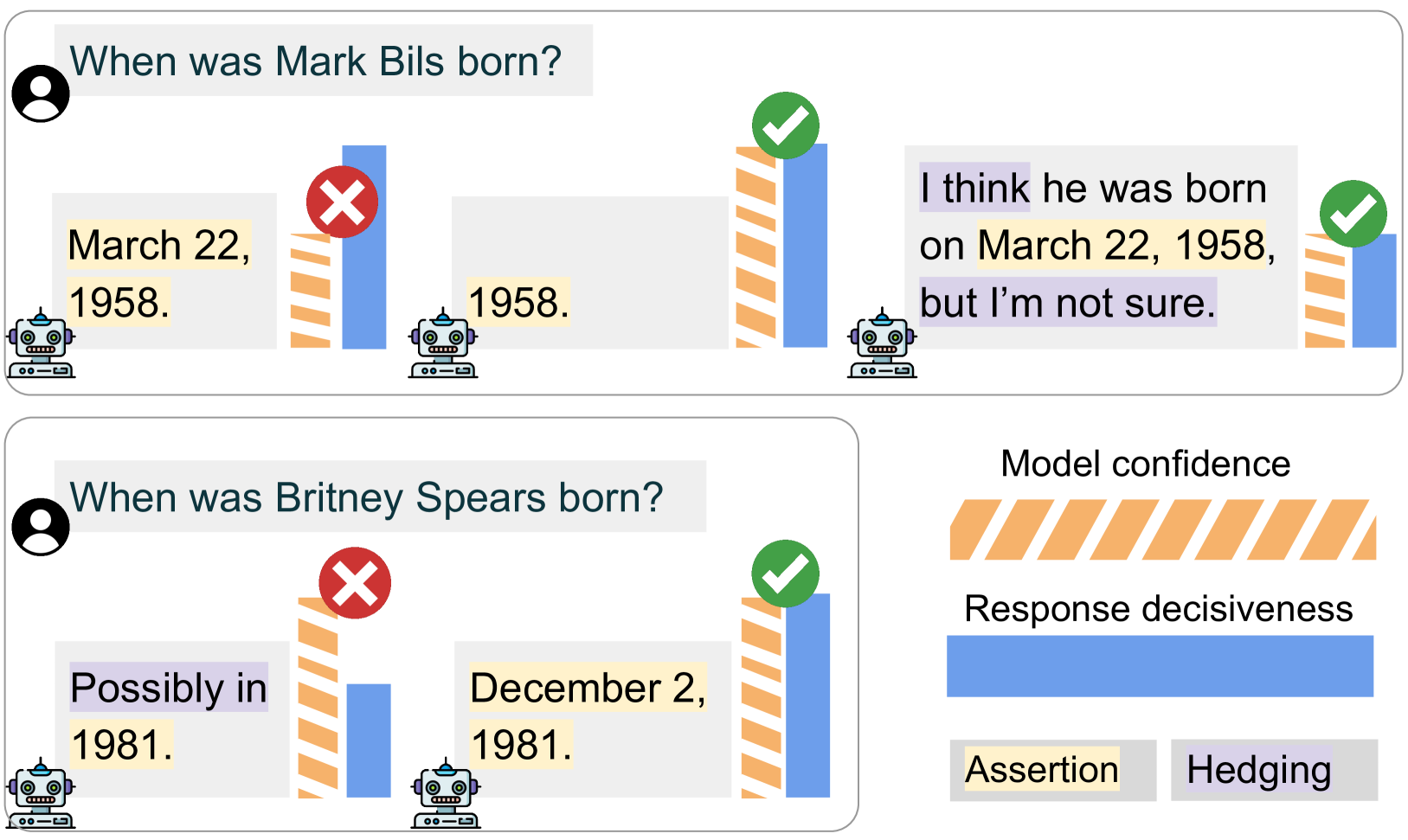
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more9/27/2024

0
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Maarten Sap
As natural language becomes the default interface for human-AI interaction, there is a need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence in responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are reluctant to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (an average of 47%) among confident responses. We test the risks of LM overconfidence by conducting human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in post training alignment and find that humans are biased against texts with uncertainty. Our work highlights new safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Read more7/11/2024