Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty

0

Sign in to get full access
Overview
- This research paper examines the reluctance of large language models (LLMs) to express uncertainty, and the impact this has on their reliability and trustworthiness.
- The paper explores how LLMs use "epistemic markers" (words and phrases that indicate uncertainty) and how this usage differs from human language.
- The researchers conduct experiments to understand the factors that influence LLMs' willingness to express uncertainty and the implications for real-world applications.
Plain English Explanation
Artificial intelligence (AI) systems, specifically large language models (LLMs), are becoming increasingly powerful and widely used. However, this research suggests that these models often struggle to express uncertainty, which can undermine their reliability and trustworthiness.
Humans naturally use certain words and phrases, called "epistemic markers," to indicate when we're unsure about something. For example, we might say "I think" or "It's possible that" to signal that we're not completely certain. The researchers found that LLMs often lack this nuance, tending to express themselves with more confidence than is warranted.
This reluctance to express uncertainty can have significant consequences. If an LLM provides a definitive answer to a question, even when it's not entirely sure, users may blindly trust the response, leading to misinformation or poor decision-making. The paper suggests that LLMs need to be trained to better understand and use epistemic markers, so they can communicate their level of certainty more accurately.
Ultimately, this research highlights the importance of developing AI systems that can acknowledge the limits of their knowledge and express uncertainty when appropriate. Only then can we build truly trustworthy and reliable AI assistants that can work effectively alongside humans.
Technical Explanation
The researchers conducted a comprehensive study to understand how large language models (LLMs) use epistemic markers, such as "I think," "maybe," and "possibly," to express uncertainty. They compared the usage of these markers in LLM outputs to their usage in human-written text, across multiple languages.
The experiments revealed that LLMs tend to be much less willing to express uncertainty compared to humans. LLMs often provide definitive answers, even when they should be more cautious. This reluctance to use epistemic markers was observed across different model architectures, training datasets, and languages.
The researchers identified several factors that influence an LLM's willingness to express uncertainty, including the specific task, the level of confidence in the model's own predictions, and the presence of certain types of content in the input text. They found that LLMs are more likely to express uncertainty when faced with open-ended questions or when their confidence in the output is lower.
The implications of this research are significant. If users rely on LLM outputs without understanding the model's level of certainty, they may make decisions based on inaccurate or unreliable information. The paper suggests that LLMs need to be trained to better express their uncertainty, perhaps through the use of specialized modules or techniques that encourage the appropriate use of epistemic markers.
Critical Analysis
The research presented in this paper provides valuable insights into the limitations of current large language models (LLMs) and the importance of developing AI systems that can accurately communicate their level of certainty. The findings highlight a significant gap between how LLMs and humans use language to express uncertainty.
One limitation of the study is that it focuses primarily on the usage of epistemic markers, which may not capture the full range of ways in which humans convey uncertainty. Future research could explore other linguistic and contextual cues that contribute to the perception of uncertainty.
Additionally, the paper does not delve deeply into the specific reasons why LLMs are reluctant to express uncertainty. While the researchers identify several influential factors, a more comprehensive understanding of the underlying mechanisms and biases within these models could lead to more effective solutions.
Another area for further exploration is the impact of uncertainty expression on the perceived trustworthiness and reliability of LLMs in real-world applications. The paper suggests that overconfident responses can lead to poor decision-making, but empirical studies are needed to fully understand the consequences.
Overall, this research highlights the critical need for AI developers to prioritize the development of language models that can faithfully communicate their level of certainty. By addressing this challenge, we can build more transparent and trustworthy AI assistants that can collaborate effectively with humans.
Conclusion
This research paper sheds light on a significant limitation of current large language models (LLMs): their reluctance to express uncertainty. The findings demonstrate that LLMs often provide definitive answers, even when they should be more cautious, which can undermine their reliability and trustworthiness.
The study's exploration of how LLMs use "epistemic markers" to convey uncertainty, and how this usage differs from human language, provides valuable insights into the inner workings of these AI systems. The identified factors that influence an LLM's willingness to express uncertainty offer a starting point for developing more nuanced and transparent language models.
Ultimately, this research highlights the importance of training AI systems to better understand and communicate their level of certainty. By developing LLMs that can acknowledge the limits of their knowledge and express uncertainty when appropriate, we can build AI assistants that are more reliable, trustworthy, and effective in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Maarten Sap
As natural language becomes the default interface for human-AI interaction, there is a need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence in responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are reluctant to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (an average of 47%) among confident responses. We test the risks of LM overconfidence by conducting human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in post training alignment and find that humans are biased against texts with uncertainty. Our work highlights new safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Read more7/11/2024
💬
0
I'm Not Sure, But...: Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, Jennifer Wortman Vaughan
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., I'm not sure, but...) decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., It's not clear, but...), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
Read more5/16/2024

0
Perceptions of Linguistic Uncertainty by Language Models and Humans
Catarina G Belem, Markelle Kelly, Mark Steyvers, Sameer Singh, Padhraic Smyth
Uncertainty expressions such as ``probably'' or ``highly unlikely'' are pervasive in human language. While prior work has established that there is population-level agreement in terms of how humans interpret these expressions, there has been little inquiry into the abilities of language models to interpret such expressions. In this paper, we investigate how language models map linguistic expressions of uncertainty to numerical responses. Our approach assesses whether language models can employ theory of mind in this setting: understanding the uncertainty of another agent about a particular statement, independently of the model's own certainty about that statement. We evaluate both humans and 10 popular language models on a task created to assess these abilities. Unexpectedly, we find that 8 out of 10 models are able to map uncertainty expressions to probabilistic responses in a human-like manner. However, we observe systematically different behavior depending on whether a statement is actually true or false. This sensitivity indicates that language models are substantially more susceptible to bias based on their prior knowledge (as compared to humans). These findings raise important questions and have broad implications for human-AI alignment and AI-AI communication.
Read more7/23/2024
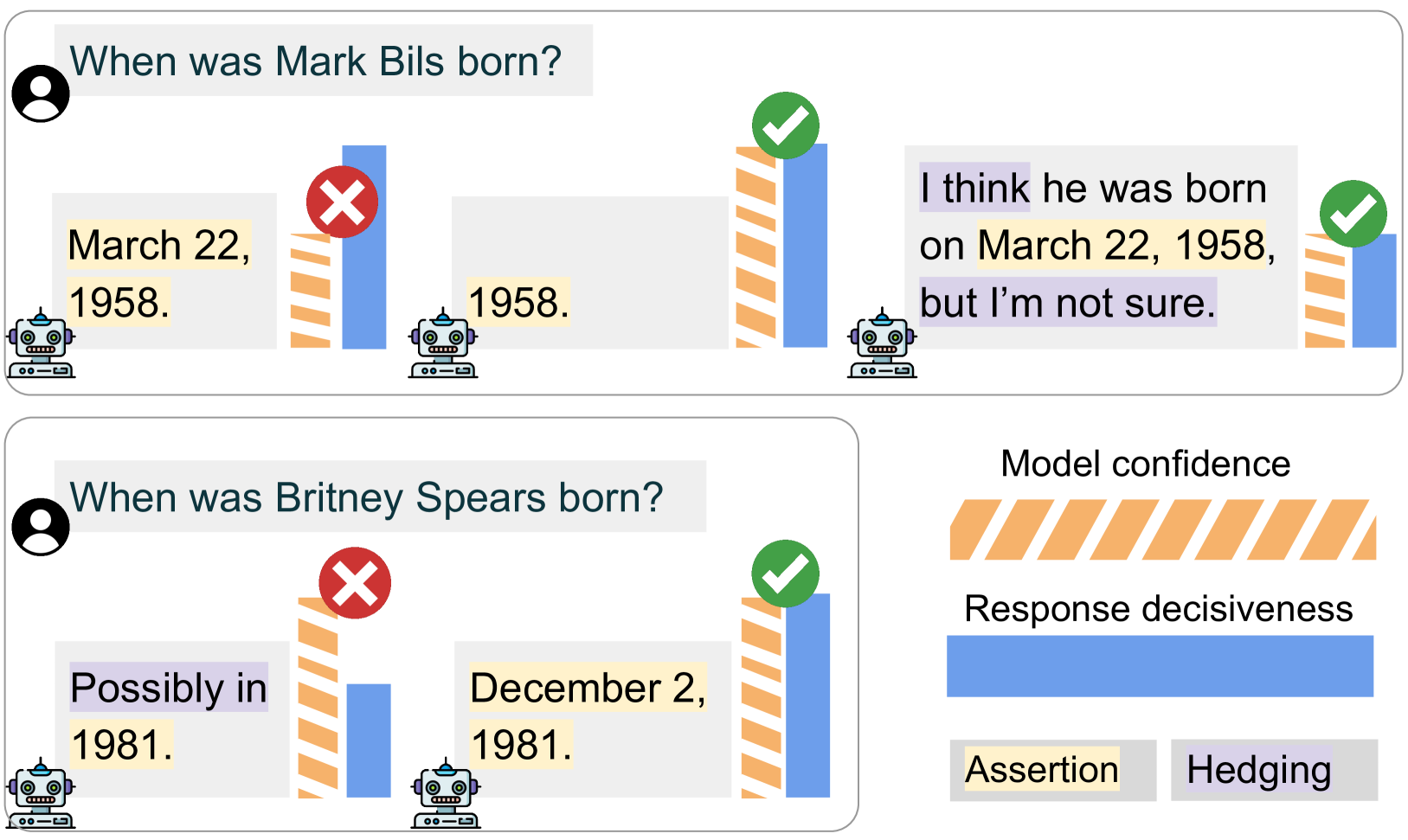
0
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more5/28/2024