FIRE: Food Image to REcipe generation

0
🖼️
Sign in to get full access
Overview
- The paper proposes a novel multimodal methodology called FIRE for recipe generation based on food images.
- FIRE leverages powerful language and vision models to generate food titles, extract ingredients, and produce cooking instructions.
- The paper also explores two practical applications of FIRE: recipe customization and automated recipe-to-code transformation.
Plain English Explanation
The paper discusses a new approach to automating the process of creating recipes from food images. Current methods for generating recipes from images rely on retrieving information from large datasets, which can be limited in size and diversity. However, the emergence of advanced language and vision models presents an opportunity to develop more accurate and versatile recipe generation systems.
The researchers introduce a system called FIRE that uses a combination of powerful models to tackle different aspects of recipe generation. FIRE can analyze a food image and automatically generate the title, list of ingredients, and step-by-step cooking instructions. This could be useful for automating recipe creation or personalizing recipes to individual preferences.
The paper also explores two potential applications of FIRE that could make cooking more accessible and efficient. One is "recipe customization," where the system can adapt recipes to fit a user's dietary needs or taste preferences. The other is "recipe-to-code transformation," which could enable automated cooking processes by translating recipes into machine-readable instructions.
Overall, the research aims to advance the field of food computing by developing intelligent systems that can autonomously generate high-quality recipes from visual inputs, potentially unlocking new possibilities in areas like personalized nutrition and automated cooking.
Technical Explanation
The paper proposes a novel multimodal methodology called FIRE (Food Image to REcipe) for the task of recipe generation. FIRE leverages the capabilities of state-of-the-art language and vision models to tackle different components of the recipe generation process.
To generate food titles, FIRE utilizes the BLIP model, a powerful vision-language model. For ingredient extraction, the system employs a Vision Transformer with a decoder. Finally, FIRE uses the T5 model to generate the full recipe instructions, incorporating the generated title and ingredients as inputs.
The researchers showcase two practical applications that can benefit from integrating FIRE with large language model prompting. The first is "recipe customization," where FIRE can adapt recipes to fit user preferences, such as dietary restrictions or taste preferences. The second is "recipe-to-code transformation," which could enable automated cooking processes by translating recipes into machine-readable instructions.
The experimental evaluation of FIRE demonstrates the effectiveness of the proposed approach, highlighting its potential for future advancements and widespread adoption in the field of food computing.
Critical Analysis
The paper presents a promising approach to automating recipe generation from food images, but there are a few areas that could be explored further.
One potential limitation is the reliance on large, pre-trained language and vision models, which may introduce biases or limitations inherent in the training data. The authors could investigate techniques to mitigate these issues, such as data augmentation or fine-tuning the models on more diverse food-related datasets.
Additionally, the paper does not provide detailed insights into the model's ability to handle rare or unusual ingredients, complex cooking techniques, or cultural variations in recipes. Evaluating the system's performance on a wider range of recipe types could shed light on its generalizability and robustness.
While the proposed applications of recipe customization and automated cooking are compelling, the paper could benefit from a more in-depth discussion of the real-world implications, potential challenges, and ethical considerations surrounding the deployment of such systems. For example, how might recipe personalization impact dietary habits, and how can the system ensure the safety and nutritional soundness of the generated recipes?
Overall, the research presented in this paper represents an exciting step forward in the field of food computing, and the authors have demonstrated the potential of large language and vision models to enable intelligent, multimodal systems for recipe generation. Further exploration of the system's capabilities, limitations, and societal impact could lead to even more impactful advancements in this domain.
Conclusion
This paper proposes FIRE, a novel multimodal methodology for recipe generation from food images. By leveraging state-of-the-art language and vision models, FIRE can automatically generate food titles, extract ingredients, and produce cooking instructions, showcasing the potential of intelligent systems to streamline and enhance the recipe creation process.
The researchers also explore two practical applications of FIRE: recipe customization and recipe-to-code transformation. These innovations could have far-reaching implications, from enabling personalized nutrition to facilitating automated cooking workflows.
Overall, the research presented in this paper represents a significant advancement in the field of food computing, demonstrating the power of multimodal approaches and the integration of large language models to tackle complex food-related challenges. As the field continues to evolve, the insights and methodologies introduced in this work could pave the way for even more transformative developments in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
FIRE: Food Image to REcipe generation
Prateek Chhikara, Dhiraj Chaurasia, Yifan Jiang, Omkar Masur, Filip Ilievski
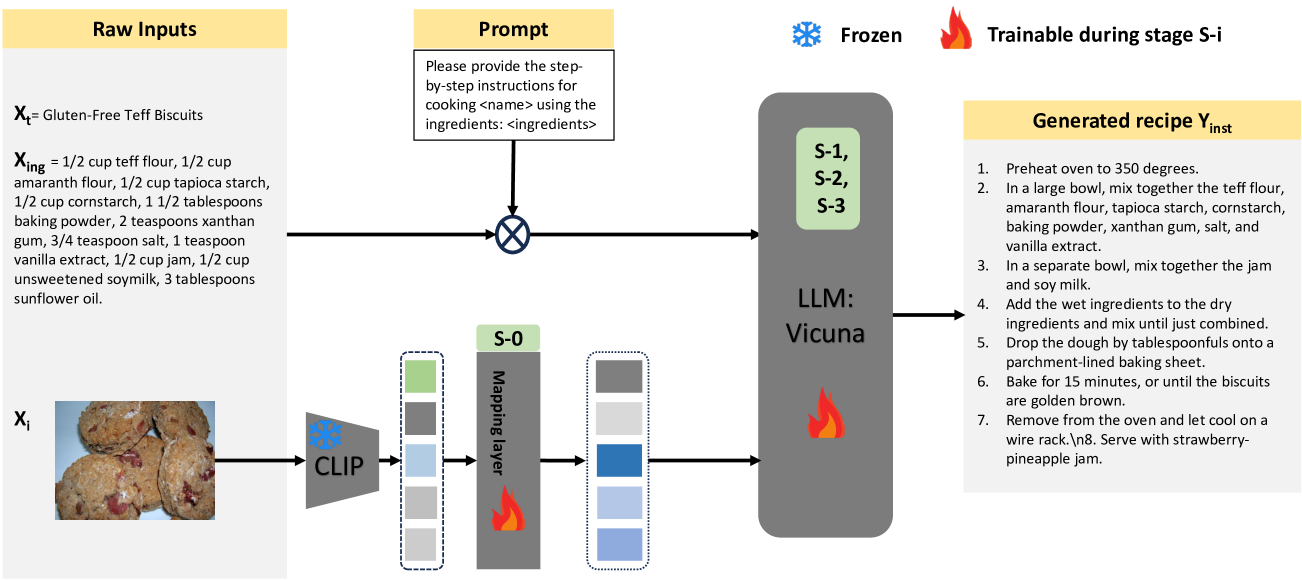
Food computing has emerged as a prominent multidisciplinary field of research in recent years. An ambitious goal of food computing is to develop end-to-end intelligent systems capable of autonomously producing recipe information for a food image. Current image-to-recipe methods are retrieval-based and their success depends heavily on the dataset size and diversity, as well as the quality of learned embeddings. Meanwhile, the emergence of powerful attention-based vision and language models presents a promising avenue for accurate and generalizable recipe generation, which has yet to be extensively explored. This paper proposes FIRE, a novel multimodal methodology tailored to recipe generation in the food computing domain, which generates the food title, ingredients, and cooking instructions based on input food images. FIRE leverages the BLIP model to generate titles, utilizes a Vision Transformer with a decoder for ingredient extraction, and employs the T5 model to generate recipes incorporating titles and ingredients as inputs. We showcase two practical applications that can benefit from integrating FIRE with large language model prompting: recipe customization to fit recipes to user preferences and recipe-to-code transformation to enable automated cooking processes. Our experimental findings validate the efficacy of our proposed approach, underscoring its potential for future advancements and widespread adoption in food computing.
Read more5/14/2024
0
Deep Image-to-Recipe Translation
Jiangqin Ma, Bilal Mawji, Franz Williams
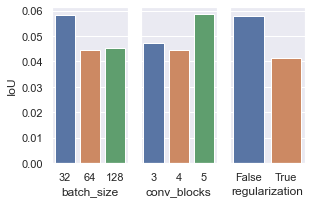
The modern saying, You Are What You Eat resonates on a profound level, reflecting the intricate connection between our identities and the food we consume. Our project, Deep Image-to-Recipe Translation, is an intersection of computer vision and natural language generation that aims to bridge the gap between cherished food memories and the art of culinary creation. Our primary objective involves predicting ingredients from a given food image. For this task, we first develop a custom convolutional network and then compare its performance to a model that leverages transfer learning. We pursue an additional goal of generating a comprehensive set of recipe steps from a list of ingredients. We frame this process as a sequence-to-sequence task and develop a recurrent neural network that utilizes pre-trained word embeddings. We address several challenges of deep learning including imbalanced datasets, data cleaning, overfitting, and hyperparameter selection. Our approach emphasizes the importance of metrics such as Intersection over Union (IoU) and F1 score in scenarios where accuracy alone might be misleading. For our recipe prediction model, we employ perplexity, a commonly used and important metric for language models. We find that transfer learning via pre-trained ResNet-50 weights and GloVe embeddings provide an exceptional boost to model performance, especially when considering training resource constraints. Although we have made progress on the image-to-recipe translation, there is an opportunity for future exploration with advancements in model architectures, dataset scalability, and enhanced user interaction.
Read more7/2/2024
0
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Fnu Mohbat, Mohammed J. Zaki
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Read more9/2/2024

0
FMiFood: Multi-modal Contrastive Learning for Food Image Classification
Xinyue Pan, Jiangpeng He, Fengqing Zhu
Food image classification is the fundamental step in image-based dietary assessment, which aims to estimate participants' nutrient intake from eating occasion images. A common challenge of food images is the intra-class diversity and inter-class similarity, which can significantly hinder classification performance. To address this issue, we introduce a novel multi-modal contrastive learning framework called FMiFood, which learns more discriminative features by integrating additional contextual information, such as food category text descriptions, to enhance classification accuracy. Specifically, we propose a flexible matching technique that improves the similarity matching between text and image embeddings to focus on multiple key information. Furthermore, we incorporate the classification objectives into the framework and explore the use of GPT-4 to enrich the text descriptions and provide more detailed context. Our method demonstrates improved performance on both the UPMC-101 and VFN datasets compared to existing methods.
Read more8/9/2024