Is Flash Attention Stable?

0
🤖
Sign in to get full access
Overview
- Training large-scale machine learning models poses unique system challenges due to the size and complexity of modern workloads.
- Many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often in the form of loss spikes.
- Numeric deviation has emerged as a potential cause of this training instability, but quantifying its impact is challenging given the costly nature of training runs.
Plain English Explanation
Building powerful AI models like Generative AI requires training extremely large and complex machine learning systems. This can lead to some tricky technical problems.
For example, many organizations working on the latest Generative AI models have noticed their training process can become unstable at times, causing the model's performance to suddenly spike up or down. Researchers suspect that a phenomenon called "numeric deviation" may be a key factor in this instability, but it's hard to measure the exact impact because training these models is so computationally expensive.
In this research paper, the authors develop a principled approach to better understand the effects of numeric deviation. They use this framework to analyze a popular optimization technique called Flash Attention, which is used to speed up the attention mechanism in large language models.
The key finding is that Flash Attention sees about 10 times more numeric deviation during a single forward pass compared to a baseline attention mechanism, when both are using a data format called BF16. However, the researchers then use advanced statistical analysis to show that this level of numeric deviation is actually less impactful on the model's weights during training than using lower-precision data formats like APTQ.
Technical Explanation
The researchers developed a framework to quantify the effects of numeric deviation, a phenomenon where small numerical errors accumulate during the computations involved in training large machine learning models. They applied this framework to analyze the Flash Attention optimization, which is a popular technique used to speed up the attention mechanism in large language models.
Through isolated forward pass experiments, the researchers found that Flash Attention sees roughly an order of magnitude more numeric deviation compared to a baseline attention mechanism when both are using the BF16 data format. To understand the real-world impact of this numeric deviation, the researchers conducted a data-driven analysis based on the Wasserstein Distance - a statistical measure of how different two probability distributions are.
This analysis revealed that the numeric deviation present in Flash Attention is actually 2-5 times less significant in terms of its impact on model weights during training, compared to the effects of using lower-precision data formats like APTQ. This suggests that the numeric deviation in Flash Attention, while non-trivial, is not the primary driver of the training instability issues reported by some Generative AI practitioners.
Critical Analysis
The researchers acknowledge several limitations in their work. Firstly, they only analyzed the numeric deviation during a single forward pass, whereas training involves many iterative updates over time. The cumulative effects of numeric deviation over thousands of training steps may differ from their isolated measurements.
Additionally, the researchers focused solely on the attention mechanism, but training large language models involves many other complex computations beyond just attention. Numeric deviation in other parts of the model architecture could potentially have a bigger impact on training stability.
It would also be valuable to extend this analysis to a wider range of optimization techniques and data formats, beyond just Flash Attention and BF16. Exploring the numeric deviation characteristics of other model components and training configurations could provide a more comprehensive understanding of the issue.
Conclusion
This research provides a principled framework for quantifying the effects of numeric deviation, a potential contributor to training instability in large-scale machine learning models. Applying this framework to the Flash Attention optimization revealed that while it sees significantly more numeric deviation than a baseline attention mechanism, this deviation is less impactful on model weights during training than the effects of using lower-precision data formats.
These findings suggest that numeric deviation, while an important consideration, may not be the primary driver of the training instability issues reported by Generative AI practitioners. The research opens the door for further exploration of the complex system-level challenges involved in training state-of-the-art machine learning models at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Is Flash Attention Stable?
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
Read more5/7/2024

0
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$times$ lower numerical error than a baseline FP8 attention.
Read more7/16/2024

0
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
Read more5/20/2024
1
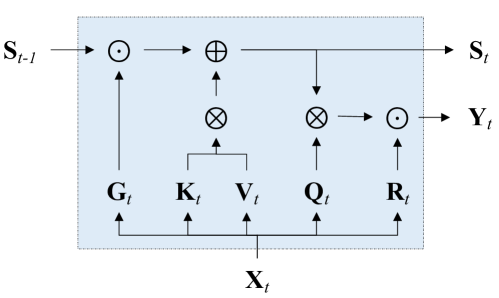
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Read more6/6/2024