Flexible and Adaptable Summarization via Expertise Separation

0

Sign in to get full access
Overview
- This paper presents a new approach to text summarization that separates expertise between different models to achieve more flexible and adaptable summarization.
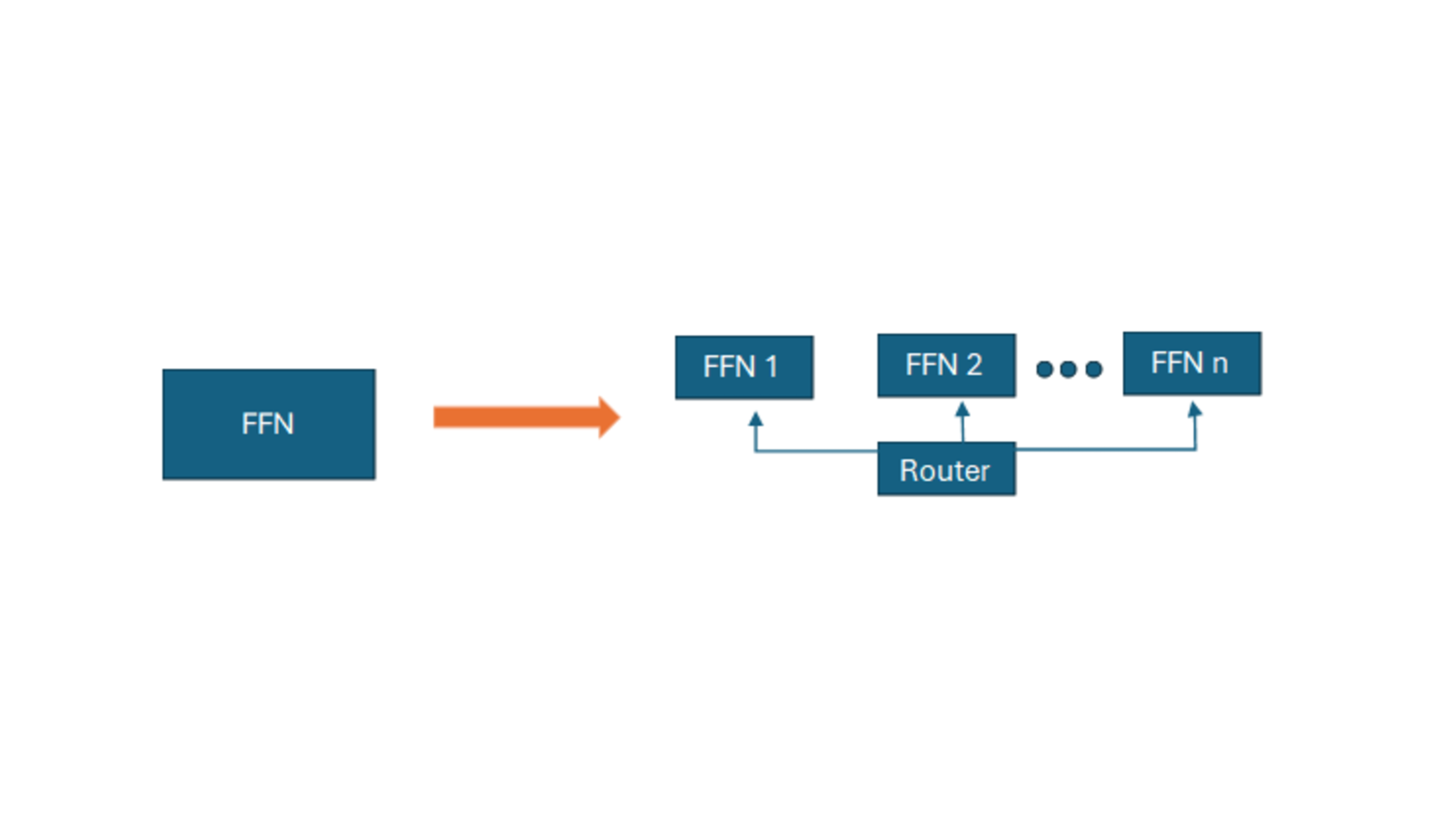
- The key idea is to use a "mixture of experts" model, where each expert specializes in a different aspect of summarization, such as identifying key concepts or generating coherent text.
- This allows the model to adapt to different summarization tasks and domains, rather than relying on a single, rigid summarization model.
Plain English Explanation
The paper describes a new way to automatically summarize text that is more flexible and adaptable than existing methods. The core idea is to use a "mixture of experts" approach, where the summarization task is divided across several specialized models or "experts."
Each expert focuses on a particular aspect of summarization, such as identifying important concepts or generating coherent text. By combining the outputs of these experts, the system can adapt to different summarization needs, rather than being limited to a single, one-size-fits-all approach.
This is similar to how a team of specialists might work together to summarize a complex topic, each contributing their unique expertise. The authors show that this flexible mixture-of-experts model outperforms traditional summarization methods on a variety of tasks and datasets.
Technical Explanation
The paper introduces a new text summarization model that uses a mixture-of-experts architecture to achieve more flexible and adaptable summarization. The key components are:
-
Expert Models: The system includes several expert models, each specializing in a different aspect of summarization, such as identifying key concepts or generating coherent text.
-
Gating Network: A "gating network" learns to dynamically combine the outputs of the experts based on the input text, allowing the model to adapt to different summarization needs.
-
Training: The experts and gating network are trained jointly on a large corpus of text, enabling the model to learn effective summarization strategies across a wide range of domains.
The experiments show that this mixture-of-experts approach outperforms traditional sequence-to-sequence summarization models on several benchmarks. The flexible and adaptable nature of the system allows it to generate high-quality summaries for diverse types of input text.
Critical Analysis
The paper presents a compelling approach to text summarization that addresses some of the limitations of existing methods. The key strengths of the mixture-of-experts model are its flexibility and adaptability, which allow it to perform well across a variety of summarization tasks and domains.
However, the paper does not thoroughly explore the potential weaknesses or limitations of this approach. For example, it is unclear how the system would perform on summarizing highly technical or specialized content, where the experts may need to have very domain-specific knowledge. Additionally, the training process for the mixture-of-experts model may be more complex and computationally expensive than simpler summarization models.
Further research could investigate the robustness of the system to noisy or incomplete input data, as well as its ability to maintain coherence and factual accuracy in the generated summaries. Comparisons to more efficient expert models could also shed light on the tradeoffs between performance and computational requirements.
Conclusion
This paper presents a novel approach to text summarization that uses a mixture-of-experts model to achieve greater flexibility and adaptability. By separating the summarization task across several specialized experts, the system can dynamically combine their outputs to generate high-quality summaries tailored to different needs and domains.
The results demonstrate the potential of this flexible approach to outperform traditional summarization methods. While there are still open questions and areas for further research, this work represents an important step towards more advanced and versatile text summarization systems that can be deployed in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Flexible and Adaptable Summarization via Expertise Separation
Xiuying Chen, Mingzhe Li, Shen Gao, Xin Cheng, Qingqing Zhu, Rui Yan, Xin Gao, Xiangliang Zhang
A proficient summarization model should exhibit both flexibility -- the capacity to handle a range of in-domain summarization tasks, and adaptability -- the competence to acquire new knowledge and adjust to unseen out-of-domain tasks. Unlike large language models (LLMs) that achieve this through parameter scaling, we propose a more parameter-efficient approach in this study. Our motivation rests on the principle that the general summarization ability to capture salient information can be shared across different tasks, while the domain-specific summarization abilities need to be distinct and tailored. Concretely, we propose MoeSumm, a Mixture-of-Expert Summarization architecture, which utilizes a main expert for gaining the general summarization capability and deputy experts that selectively collaborate to meet specific summarization task requirements. We further propose a max-margin loss to stimulate the separation of these abilities. Our model's distinct separation of general and domain-specific summarization abilities grants it with notable flexibility and adaptability, all while maintaining parameter efficiency. MoeSumm achieves flexibility by managing summarization across multiple domains with a single model, utilizing a shared main expert and selected deputy experts. It exhibits adaptability by tailoring deputy experts to cater to out-of-domain few-shot and zero-shot scenarios. Experimental results on 11 datasets show the superiority of our model compared with recent baselines and LLMs. We also provide statistical and visual evidence of the distinct separation of the two abilities in MoeSumm (https://github.com/iriscxy/MoE_Summ).
Read more6/11/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
🔍
0
Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
Jialin Wu, Xia Hu, Yaqing Wang, Bo Pang, Radu Soricut
Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use. We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.
Read more4/4/2024
0
Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts
Rhui Dih Lee, Laura Wynter, Raghu Kiran Ganti
We present a toolkit for creating low-cost Mixture-of-Domain-Experts (MOE) from trained models. The toolkit can be used for creating a mixture from models or from adapters. We perform extensive tests and offer guidance on defining the architecture of the resulting MOE using the toolkit. A public repository is available.
Read more9/12/2024