FlexiFilm: Long Video Generation with Flexible Conditions
2404.18620
0
0
🛸
Abstract
Generating long and consistent videos has emerged as a significant yet challenging problem. While most existing diffusion-based video generation models, derived from image generation models, demonstrate promising performance in generating short videos, their simple conditioning mechanism and sampling strategy-originally designed for image generation-cause severe performance degradation when adapted to long video generation. This results in prominent temporal inconsistency and overexposure. Thus, in this work, we introduce FlexiFilm, a new diffusion model tailored for long video generation. Our framework incorporates a temporal conditioner to establish a more consistent relationship between generation and multi-modal conditions, and a resampling strategy to tackle overexposure. Empirical results demonstrate FlexiFilm generates long and consistent videos, each over 30 seconds in length, outperforming competitors in qualitative and quantitative analyses. Project page: https://y-ichen.github.io/FlexiFilm-Page/
Create account to get full access
Overview
- Generating long and consistent videos is a challenging problem in the field of video generation.
- Most existing diffusion-based video generation models, which are derived from image generation models, struggle with long video generation due to their simple conditioning mechanism and sampling strategy.
- This results in issues like temporal inconsistency and overexposure when adapting these models to long video generation.
- To address these challenges, the researchers introduce a new diffusion model called FlexiFilm, specifically designed for long video generation.
Plain English Explanation
The research paper discusses the challenge of generating long and consistent videos using existing video generation models. These models, which are based on diffusion techniques originally developed for image generation, tend to perform poorly when adapted to creating longer videos.
The main problems are that the conditioning mechanisms and sampling strategies used in these models are not well-suited for generating long, temporally consistent videos. This can lead to issues like the video content becoming inconsistent over time (temporal inconsistency) or certain elements being overexposed and repeated too often (overexposure).
To tackle these problems, the researchers have developed a new diffusion-based model called FlexiFilm, which is specifically designed for generating long videos. FlexiFilm incorporates a temporal conditioner to help maintain a more consistent relationship between the video generation and the input conditions. It also uses a resampling strategy to address the overexposure issue.
The researchers claim that FlexiFilm is able to generate high-quality, long videos (over 30 seconds in length) that outperform competing models in both qualitative and quantitative evaluations.
Technical Explanation
The paper introduces FlexiFilm, a new diffusion-based model for generating long and consistent videos. Diffusion models, which have shown promising results in image generation, typically struggle when adapted to video generation tasks due to their simple conditioning mechanism and sampling strategy.
To address these limitations, the FlexiFilm framework incorporates two key innovations:
-
Temporal Conditioner: FlexiFilm uses a temporal conditioner to establish a more consistent relationship between the video generation and the multi-modal input conditions (e.g., text, images). This helps maintain temporal coherence in the generated videos.
-
Resampling Strategy: FlexiFilm employs a resampling strategy to tackle the issue of overexposure, where certain elements of the video are repeatedly generated. This helps improve the diversity and consistency of the generated content.
The researchers conduct extensive experiments to evaluate the performance of FlexiFilm, and they demonstrate that it is able to generate long videos (over 30 seconds) that outperform competing models in both qualitative and quantitative analyses.
Critical Analysis
The paper addresses an important challenge in the field of video generation, and the proposed FlexiFilm model represents a promising approach to generating long and consistent videos. The incorporation of the temporal conditioner and the resampling strategy are relevant and well-motivated innovations.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the FlexiFilm model. For example, it would be interesting to understand the computational complexity and training requirements of the model, as well as any potential biases or artifacts that may arise in the generated videos.
Additionally, the paper could have delved deeper into the potential real-world applications and implications of the FlexiFilm model, as well as how it compares to or complements other video generation approaches, such as LoopAnimate, KOALA, BiVDiff, and MovieChat.
Overall, the paper presents a novel and promising approach to long video generation, but there is room for further exploration and analysis to fully understand the capabilities and limitations of the FlexiFilm model.
Conclusion
The research paper introduces FlexiFilm, a new diffusion-based model designed specifically for generating long and consistent videos. By incorporating a temporal conditioner and a resampling strategy, FlexiFilm addresses the limitations of existing diffusion-based video generation models, which struggle with temporal consistency and overexposure when adapted to long-form video generation.
The results presented in the paper demonstrate that FlexiFilm is able to generate high-quality videos over 30 seconds in length, outperforming competing models in both qualitative and quantitative evaluations. This work represents an important step forward in the field of video generation, with potential applications in areas like video content generation, video summarization, and video-based interactive experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Controllable Longer Image Animation with Diffusion Models
Qiang Wang, Minghua Liu, Junjun Hu, Fan Jiang, Mu Xu
0
0
Generating realistic animated videos from static images is an important area of research in computer vision. Methods based on physical simulation and motion prediction have achieved notable advances, but they are often limited to specific object textures and motion trajectories, failing to exhibit highly complex environments and physical dynamics. In this paper, we introduce an open-domain controllable image animation method using motion priors with video diffusion models. Our method achieves precise control over the direction and speed of motion in the movable region by extracting the motion field information from videos and learning moving trajectories and strengths. Current pretrained video generation models are typically limited to producing very short videos, typically less than 30 frames. In contrast, we propose an efficient long-duration video generation method based on noise reschedule specifically tailored for image animation tasks, facilitating the creation of videos over 100 frames in length while maintaining consistency in content scenery and motion coordination. Specifically, we decompose the denoise process into two distinct phases: the shaping of scene contours and the refining of motion details. Then we reschedule the noise to control the generated frame sequences maintaining long-distance noise correlation. We conducted extensive experiments with 10 baselines, encompassing both commercial tools and academic methodologies, which demonstrate the superiority of our method. Our project page: https://wangqiang9.github.io/Controllable.github.io/
5/29/2024
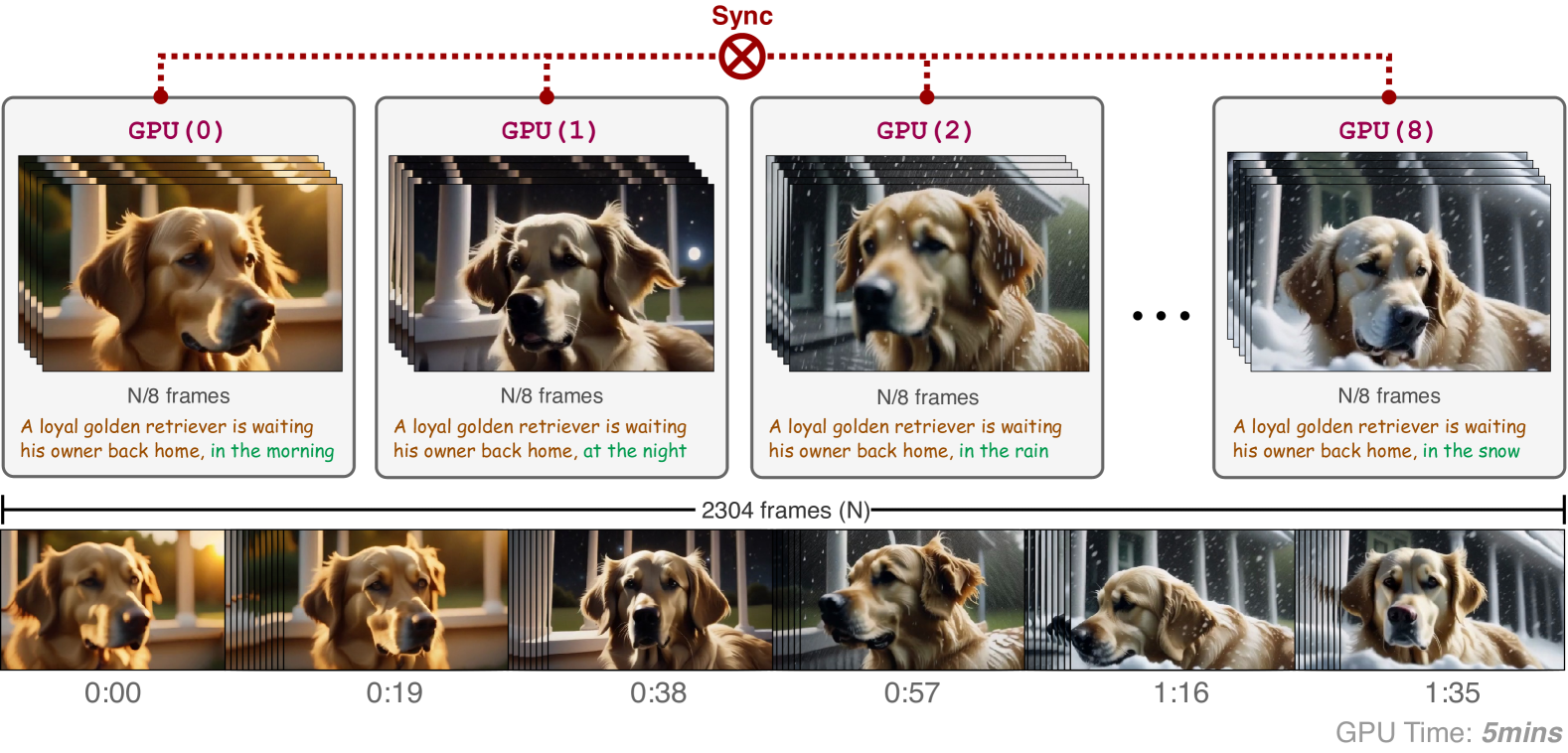
Video-Infinity: Distributed Long Video Generation
Zhenxiong Tan, Xingyi Yang, Songhua Liu, Xinchao Wang
0
0
Diffusion models have recently achieved remarkable results for video generation. Despite the encouraging performances, the generated videos are typically constrained to a small number of frames, resulting in clips lasting merely a few seconds. The primary challenges in producing longer videos include the substantial memory requirements and the extended processing time required on a single GPU. A straightforward solution would be to split the workload across multiple GPUs, which, however, leads to two issues: (1) ensuring all GPUs communicate effectively to share timing and context information, and (2) modifying existing video diffusion models, which are usually trained on short sequences, to create longer videos without additional training. To tackle these, in this paper we introduce Video-Infinity, a distributed inference pipeline that enables parallel processing across multiple GPUs for long-form video generation. Specifically, we propose two coherent mechanisms: Clip parallelism and Dual-scope attention. Clip parallelism optimizes the gathering and sharing of context information across GPUs which minimizes communication overhead, while Dual-scope attention modulates the temporal self-attention to balance local and global contexts efficiently across the devices. Together, the two mechanisms join forces to distribute the workload and enable the fast generation of long videos. Under an 8 x Nvidia 6000 Ada GPU (48G) setup, our method generates videos up to 2,300 frames in approximately 5 minutes, enabling long video generation at a speed 100 times faster than the prior methods.
6/26/2024

StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
0
0
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
5/3/2024
🛸
ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation
Bo Peng, Xinyuan Chen, Yaohui Wang, Chaochao Lu, Yu Qiao
0
0
Recent works have successfully extended large-scale text-to-image models to the video domain, producing promising results but at a high computational cost and requiring a large amount of video data. In this work, we introduce ConditionVideo, a training-free approach to text-to-video generation based on the provided condition, video, and input text, by leveraging the power of off-the-shelf text-to-image generation methods (e.g., Stable Diffusion). ConditionVideo generates realistic dynamic videos from random noise or given scene videos. Our method explicitly disentangles the motion representation into condition-guided and scenery motion components. To this end, the ConditionVideo model is designed with a UNet branch and a control branch. To improve temporal coherence, we introduce sparse bi-directional spatial-temporal attention (sBiST-Attn). The 3D control network extends the conventional 2D controlnet model, aiming to strengthen conditional generation accuracy by additionally leveraging the bi-directional frames in the temporal domain. Our method exhibits superior performance in terms of frame consistency, clip score, and conditional accuracy, outperforming other compared methods.
5/24/2024