MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
2404.17176
0
0
Abstract
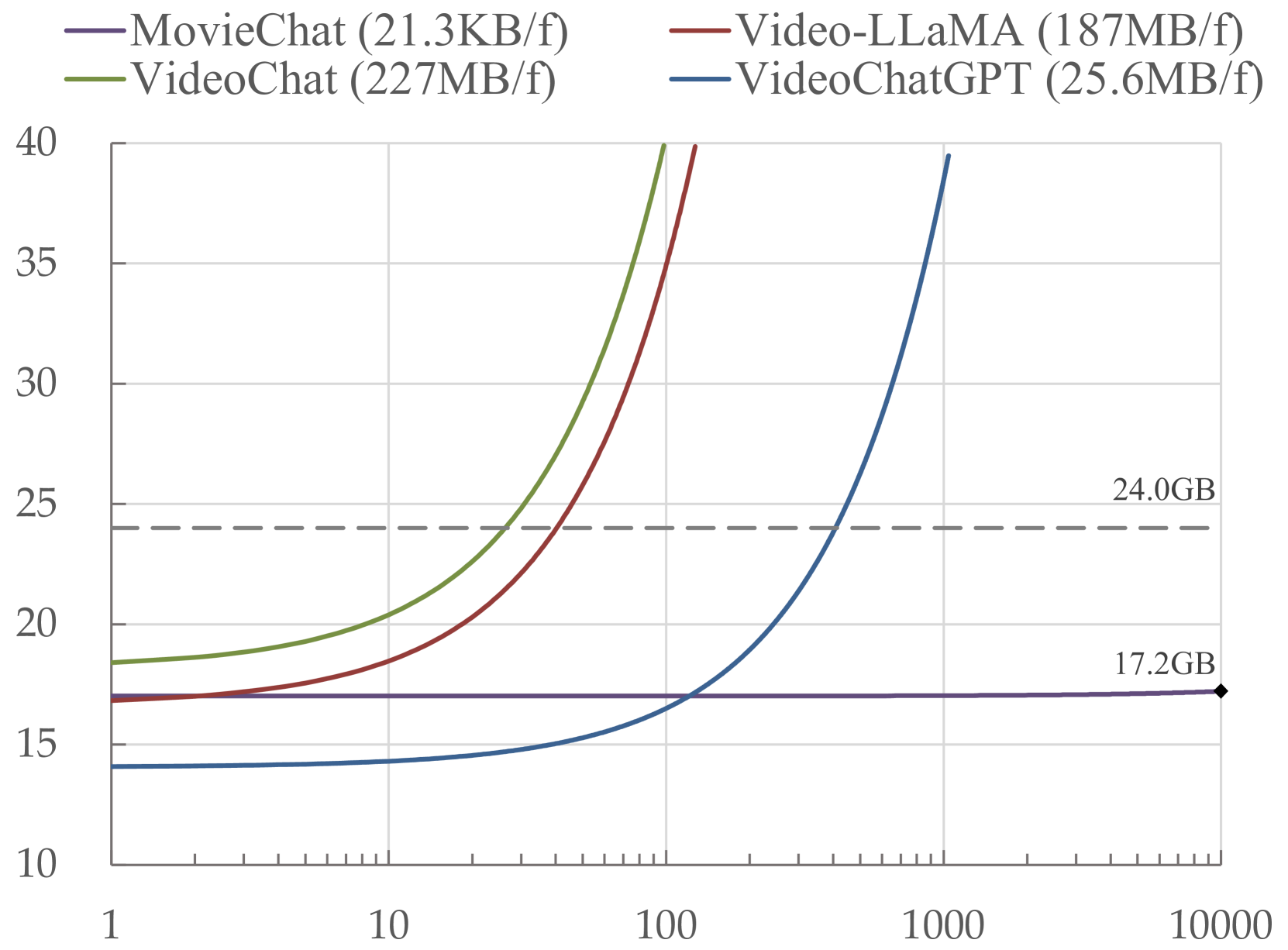
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
Create account to get full access
Overview
- Proposes a novel model called MovieChat+ for long video question answering
- Introduces a question-aware sparse memory module to efficiently process and retrieve relevant information from long videos
- Demonstrates state-of-the-art performance on the MOVIEQA benchmark, which involves answering questions about full-length movies
Plain English Explanation
MovieChat+ is a new AI system designed to help answer questions about long videos, such as full-length movies. Answering questions about long videos can be challenging because there is a lot of information to sift through.
To address this, MovieChat+ uses a "question-aware sparse memory" module. This module selectively focuses on the parts of the video that are most relevant to answering the given question, rather than trying to process the entire video. This makes the system more efficient and effective at finding the right information to answer the question.
The researchers tested MovieChat+ on a dataset called MOVIEQA, which contains questions about full-length movies. MovieChat+ was able to outperform other state-of-the-art approaches, demonstrating the benefits of its question-aware sparse memory design.
This research represents an important step forward in long video understanding, as it shows how AI systems can be made more adept at comprehending and reasoning about the contents of long visual media, like movies and TV shows. This could have applications in areas like video summarization, question answering, and large language models for video understanding.
Technical Explanation
MovieChat+ is a vision-language model designed for long video question answering. It introduces a novel "question-aware sparse memory" module that selectively encodes and retrieves relevant information from long video inputs.
The key innovation is that the sparse memory module attends to the video frames and tokens in a question-guided manner. This allows the model to focus its processing on the parts of the video that are most pertinent to answering the given question, rather than having to encode the entire video sequence.
The researchers evaluate MovieChat+ on the MOVIEQA benchmark, which requires answering questions about the plots and details of full-length movies. MovieChat+ achieves state-of-the-art performance on this task, demonstrating the effectiveness of its question-aware sparse memory approach for long video understanding.
Critical Analysis
The MovieChat+ paper makes a compelling case for the value of selective, question-guided processing of long video inputs. By introducing a sparse memory module that can efficiently retrieve relevant information, the model is able to outperform prior approaches on the challenging MOVIEQA benchmark.
That said, the paper does not address some potential limitations of the approach. For example, it's unclear how well MovieChat+ would generalize to open-ended video question answering, where the questions may be more diverse and less directly tied to the video content.
Additionally, the sparse memory module introduces additional complexity and parameters to the model, which could impact training efficiency and computational costs. The authors do not provide a detailed analysis of the model's efficiency or scaling properties.
Overall, MovieChat+ represents an interesting and promising direction for long-form video understanding. However, further research is needed to better understand the strengths, weaknesses, and broader applicability of this approach.
Conclusion
The MovieChat+ model introduces a novel question-aware sparse memory module to enable efficient long video question answering. By selectively focusing on the most relevant parts of long video inputs, the model is able to achieve state-of-the-art performance on the MOVIEQA benchmark.
This work highlights the importance of developing specialized architectural components and processing strategies for tackling the challenges of long-form video understanding. The question-aware sparse memory approach could have broader applications in areas like video summarization, long-form question answering, and large language models for video. As the field of AI continues to grapple with the complexities of real-world, long-form media, innovations like MovieChat+ will be crucial for unlocking the full potential of machine understanding and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!Hierarchical Memory for Long Video QA
Yiqin Wang, Haoji Zhang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, Xiaojie Jin
0
0
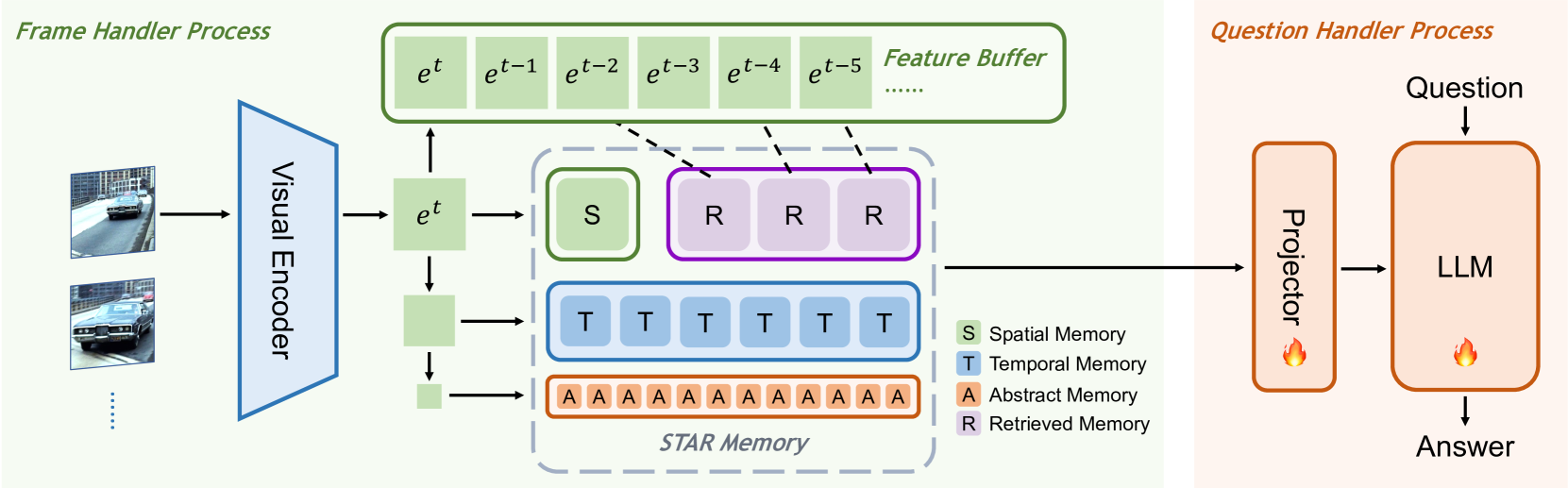
This paper describes our champion solution to the LOVEU Challenge @ CVPR'24, Track 1 (Long Video VQA). Processing long sequences of visual tokens is computationally expensive and memory-intensive, making long video question-answering a challenging task. The key is to compress visual tokens effectively, reducing memory footprint and decoding latency, while preserving the essential information for accurate question-answering. We adopt a hierarchical memory mechanism named STAR Memory, proposed in Flash-VStream, that is capable of processing long videos with limited GPU memory (VRAM). We further utilize the video and audio data of MovieChat-1K training set to fine-tune the pretrained weight released by Flash-VStream, achieving 1st place in the challenge. Code is available at project homepage https://invinciblewyq.github.io/vstream-page
7/2/2024

Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang
0
0
This paper presents VideoStreaming, an advanced vision-language large model (VLLM) for video understanding, that capably understands arbitrary-length video with a constant number of video tokens streamingly encoded and adaptively selected. The challenge of video understanding in the vision language area mainly lies in the significant computational burden caused by the great number of tokens extracted from long videos. Previous works rely on sparse sampling or frame compression to reduce tokens. However, such approaches either disregard temporal information in a long time span or sacrifice spatial details, resulting in flawed compression. To address these limitations, our VideoStreaming has two core designs: Memory-Propagated Streaming Encoding and Adaptive Memory Selection. The Memory-Propagated Streaming Encoding architecture segments long videos into short clips and sequentially encodes each clip with a propagated memory. In each iteration, we utilize the encoded results of the preceding clip as historical memory, which is integrated with the current clip to distill a condensed representation that encapsulates the video content up to the current timestamp. After the encoding process, the Adaptive Memory Selection strategy selects a constant number of question-related memories from all the historical memories and feeds them into the LLM to generate informative responses. The question-related selection reduces redundancy within the memories, enabling efficient and precise video understanding. Meanwhile, the disentangled video extraction and reasoning design allows the LLM to answer different questions about a video by directly selecting corresponding memories, without the need to encode the whole video for each question. Our model achieves superior performance and higher efficiency on long video benchmarks, showcasing precise temporal comprehension for detailed question answering.
5/28/2024
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
0
0
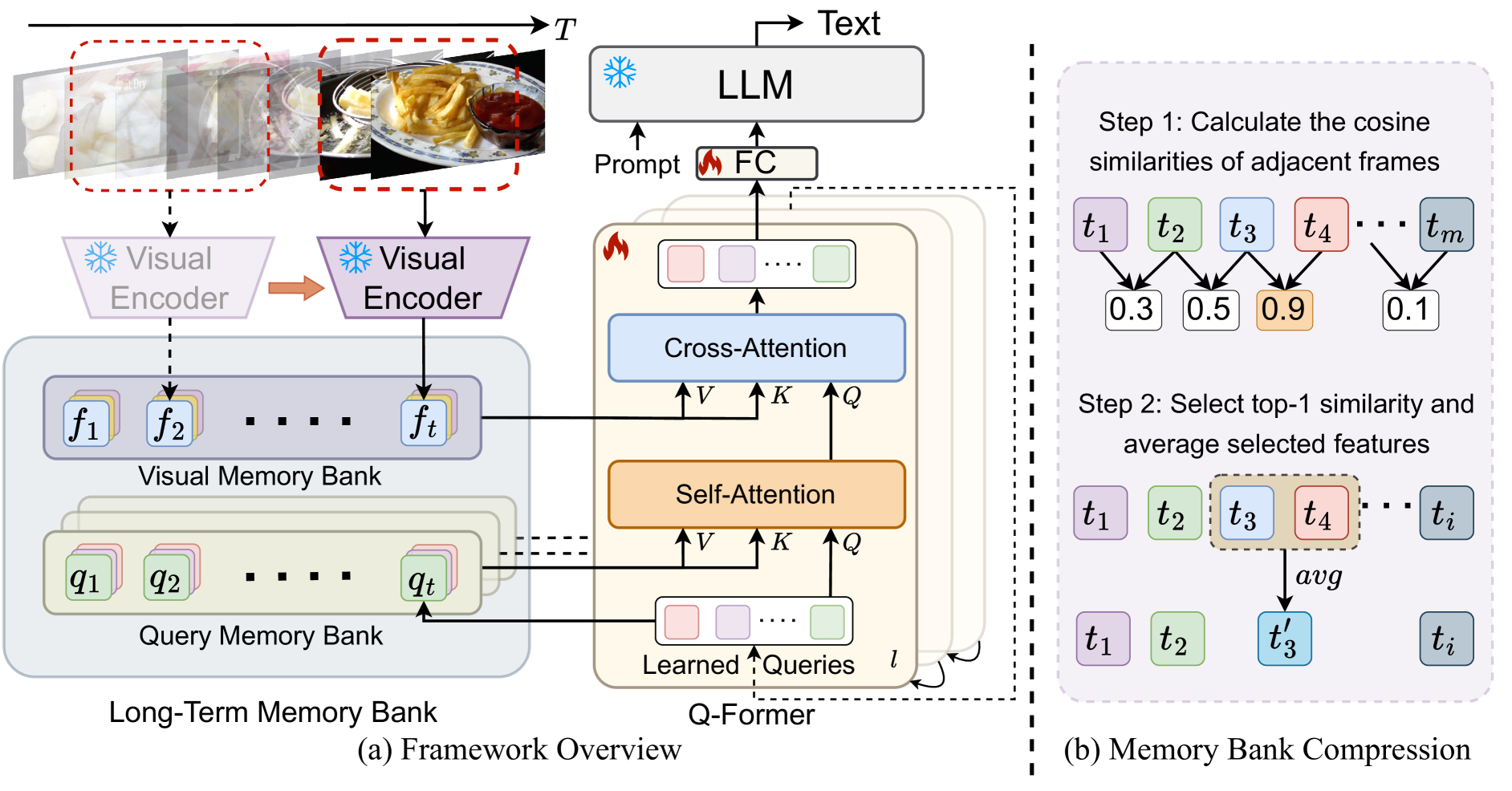
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
4/9/2024

Hallucination Mitigation Prompts Long-term Video Understanding
Yiwei Sun, Zhihang Liu, Chuanbin Liu, Bowei Pu, Zhihan Zhang, Hongtao Xie
0
0
Recently, multimodal large language models have made significant advancements in video understanding tasks. However, their ability to understand unprocessed long videos is very limited, primarily due to the difficulty in supporting the enormous memory overhead. Although existing methods achieve a balance between memory and information by aggregating frames, they inevitably introduce the severe hallucination issue. To address this issue, this paper constructs a comprehensive hallucination mitigation pipeline based on existing MLLMs. Specifically, we use the CLIP Score to guide the frame sampling process with questions, selecting key frames relevant to the question. Then, We inject question information into the queries of the image Q-former to obtain more important visual features. Finally, during the answer generation stage, we utilize chain-of-thought and in-context learning techniques to explicitly control the generation of answers. It is worth mentioning that for the breakpoint mode, we found that image understanding models achieved better results than video understanding models. Therefore, we aggregated the answers from both types of models using a comparison mechanism. Ultimately, We achieved 84.2% and 62.9% for the global and breakpoint modes respectively on the MovieChat dataset, surpassing the official baseline model by 29.1% and 24.1%. Moreover the proposed method won the third place in the CVPR LOVEU 2024 Long-Term Video Question Answering Challenge. The code is avaiable at https://github.com/lntzm/CVPR24Track-LongVideo
6/18/2024