FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks

0

Sign in to get full access
Overview
- This paper presents FM-OSD, a novel approach for one-shot detection of anatomical landmarks using foundation models.
- The method leverages the powerful feature representation capabilities of foundation models like CLIP to enable accurate one-shot detection of landmarks with limited training data.
- The system is evaluated on challenging medical imaging datasets and achieves state-of-the-art performance, demonstrating the potential of foundation models for few-shot and one-shot learning tasks.
Plain English Explanation
The researchers developed a new system called FM-OSD that can quickly and accurately detect important anatomical landmarks in medical images, even when there is limited training data available.
The key innovation is the use of "foundation models" - large, pre-trained AI models that have learned powerful visual feature representations from massive datasets. By combining these foundation models with a specialized one-shot learning approach, FM-OSD can detect landmarks like bones, organs, and other structures after seeing just a single example.
This is a significant improvement over traditional landmark detection methods, which typically require a large amount of labeled training data. The FM-OSD approach is more efficient and flexible, making it well-suited for real-world medical imaging applications where data can be scarce or expensive to annotate.
The researchers demonstrated the effectiveness of FM-OSD on several medical image datasets, showing that it outperforms other state-of-the-art techniques. This work highlights the potential of foundation models to enable powerful few-shot and one-shot learning capabilities, which could transform how we approach a variety of computer vision problems in the medical domain and beyond.
Technical Explanation
The core innovation of the FM-OSD system is the integration of foundation models, such as CLIP, into a one-shot learning architecture for anatomical landmark detection.
Foundation models are large, pre-trained AI models that have learned rich visual feature representations from vast datasets. By leveraging these powerful features, FM-OSD can accurately detect anatomical landmarks with just a single labeled example, overcoming the data scarcity challenges of traditional landmark detection methods.
The FM-OSD approach works as follows:
- A foundation model, such as CLIP, is used to extract visual features from the input medical image.
- The user provides a single labeled example of the target landmark, which is also encoded using the foundation model.
- The system then compares the features of the input image to the reference landmark features, using a specialized one-shot learning algorithm to identify the landmark location.
The researchers evaluate FM-OSD on several challenging medical imaging datasets, including FaceLift, Infinite-3D Landmarks, and Facial Landmark Detection. The results demonstrate that FM-OSD outperforms other state-of-the-art landmark detection techniques, particularly in settings with limited training data.
Critical Analysis
The FM-OSD approach shows promising results, but there are a few potential limitations and areas for further research:
-
Generalization to diverse datasets: While the method performs well on the evaluated medical imaging datasets, it would be valuable to test its generalization to a wider range of modalities and anatomical structures, including those with greater variability in appearance and context.
-
Robustness to noisy or low-quality data: The paper does not address the system's performance on medical images with common challenges like noise, occlusions, or low resolution. Evaluating the robustness of FM-OSD in these more realistic scenarios would be an important next step.
-
Interpretability and explainability: As with many deep learning-based systems, the internal workings of FM-OSD may be opaque, making it difficult to understand how the model arrives at its predictions. Developing more interpretable and explainable versions of the system could improve trust and facilitate clinical adoption.
-
Computational efficiency: The use of foundation models, while powerful, can come with increased computational requirements. Exploring ways to optimize the efficiency of the FM-OSD pipeline would be valuable, especially for real-time or edge-based applications.
Overall, the FM-OSD approach represents an exciting advancement in the field of one-shot learning for medical image analysis, leveraging the capabilities of foundation models to overcome data scarcity challenges. Further research to address the limitations identified above could help unlock the full potential of this technique.
Conclusion
The FM-OSD system presented in this paper demonstrates the power of foundation models for enabling accurate one-shot detection of anatomical landmarks in medical images. By combining the rich visual feature representations of foundation models with a specialized one-shot learning algorithm, the researchers have developed a highly effective and efficient landmark detection system that outperforms other state-of-the-art methods.
The implications of this work extend beyond the medical domain, as the core principles of leveraging foundation models for few-shot and one-shot learning could be applied to a wide range of computer vision tasks. As the field of AI continues to evolve, innovations like FM-OSD will play a crucial role in making these powerful techniques more accessible and applicable to real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Juzheng Miao, Cheng Chen, Keli Zhang, Jie Chuai, Quanzheng Li, Pheng-Ann Heng
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Read more7/9/2024
💬
0
Which images to label for few-shot medical landmark detection?
Quan Quan, Qingsong Yao, Jun Li, S. Kevin Zhou
The success of deep learning methods relies on the availability of well-labeled large-scale datasets. However, for medical images, annotating such abundant training data often requires experienced radiologists and consumes their limited time. Few-shot learning is developed to alleviate this burden, which achieves competitive performances with only several labeled data. However, a crucial yet previously overlooked problem in few-shot learning is about the selection of template images for annotation before learning, which affects the final performance. We herein propose a novel Sample Choosing Policy (SCP) to select the most worthy images for annotation, in the context of few-shot medical landmark detection. SCP consists of three parts: 1) Self-supervised training for building a pre-trained deep model to extract features from radiological images, 2) Key Point Proposal for localizing informative patches, and 3) Representative Score Estimation for searching the most representative samples or templates. The advantage of SCP is demonstrated by various experiments on three widely-used public datasets. For one-shot medical landmark detection, its use reduces the mean radial errors on Cephalometric and HandXray datasets by 14.2% (from 3.595mm to 3.083mm) and 35.5% (4.114mm to 2.653mm), respectively.
Read more4/30/2024

0
FaceLift: Semi-supervised 3D Facial Landmark Localization
David Ferman, Pablo Garrido, Gaurav Bharaj
3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Read more5/31/2024
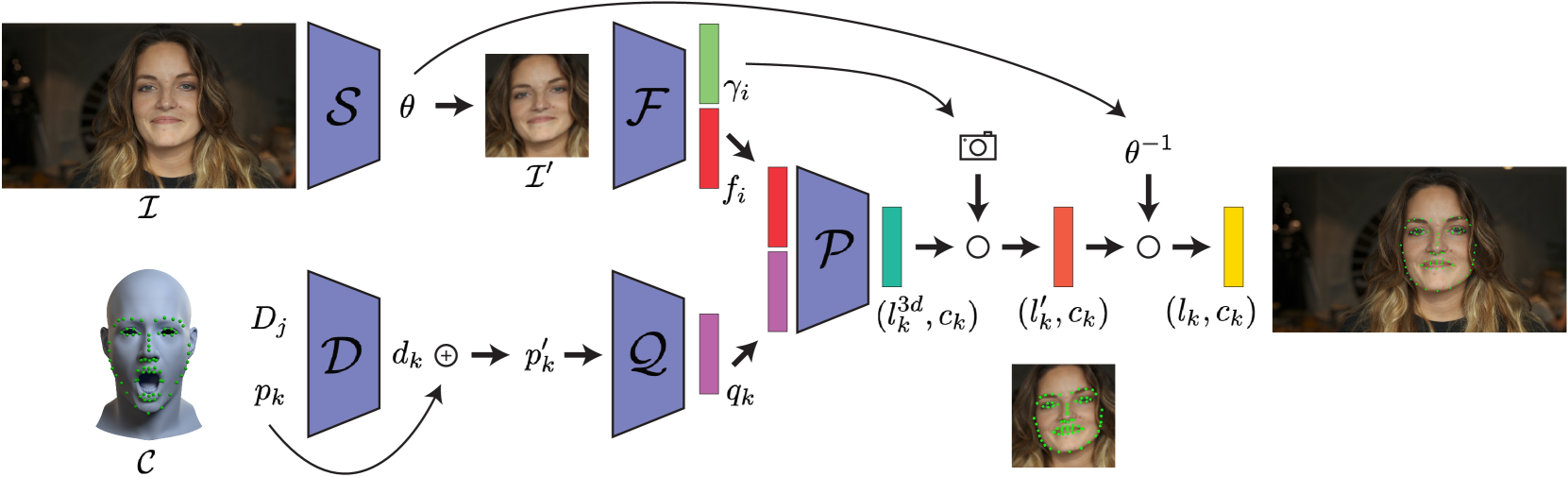
0
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Derek Bradley
In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
Read more5/31/2024