Focal Depth Estimation: A Calibration-Free, Subject- and Daytime Invariant Approach

0
Sign in to get full access
Overview
- This paper presents a novel method for estimating focal depth, which is the distance between the camera and the object in focus, without the need for camera calibration or subject-specific training.
- The approach uses a deep learning model to directly estimate focal depth from monocular images, making it more practical for real-world applications compared to previous methods.
- Key features of the proposed technique include being calibration-free, subject-invariant, and robust to changes in lighting conditions throughout the day.
Plain English Explanation
The paper describes a new way to estimate the focal depth - the distance between a camera and the object that is in focus. Previous methods required calibrating the camera or training the system on data from specific people. However, this new approach uses a deep learning model that can directly estimate the focal depth just from the camera image, without any special setup or personalization.
This is useful because it makes the technology more practical and easy to use in real-world applications, like eye tracking or nighttime photography. The model is also robust to changes in lighting throughout the day, so it can work reliably in different environments. Overall, this represents an important advance in depth estimation from single images.
Technical Explanation
The core of the proposed approach is a deep neural network that takes a monocular image as input and directly outputs the estimated focal depth. This avoids the need for explicit camera calibration or subject-specific training data, which were required by previous methods.
The authors trained their model on a large and diverse dataset of images with associated ground truth focal depth information. They employed various data augmentation techniques to ensure the model would generalize well to new scenes and lighting conditions.
Experiments showed the model achieved state-of-the-art performance on standard focal depth estimation benchmarks, while also demonstrating robustness to variations in the time of day and individual differences between test subjects. The authors attribute this to the model's ability to learn depth cues that are invariant to these factors.
Critical Analysis
The paper makes a compelling case for the advantages of this calibration-free, subject-invariant approach to focal depth estimation. However, some potential limitations or areas for further research are worth noting:
- The dataset used for training, while large, may not capture the full diversity of real-world scenes and imaging conditions. Evaluating the model's performance on a broader range of environments would be valuable.
- While the method is robust to lighting changes, it's unclear how well it would handle more extreme conditions, such as very low-light or high-contrast scenes. Further testing in challenging scenarios could uncover limitations.
- The paper does not explore how this focal depth estimation technique could be integrated with or benefit other computer vision tasks, such as object detection or augmented reality applications. Investigating these potential synergies could strengthen the practical impact of this research.
Overall, the proposed method represents an important step forward in making focal depth estimation more accessible and practical for real-world use cases. Further research to address the areas mentioned above could help solidify the technique's advantages and broaden its applicability.
Conclusion
This paper presents a novel, calibration-free approach to estimating focal depth from monocular images using deep learning. By eliminating the need for camera calibration or subject-specific training, the method significantly improves the practicality and accessibility of this technology.
The key innovations include the ability to directly estimate focal depth without any special setup, as well as robustness to changes in lighting conditions and individual differences between users. These advancements could enable new applications in areas like eye tracking, augmented reality, and computational photography that rely on accurate depth information.
While the paper demonstrates impressive results, further research to expand the technique's capabilities and integration with other computer vision tasks could unlock even greater potential. Overall, this work represents an important step forward in making depth estimation more accessible and impactful in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Focal Depth Estimation: A Calibration-Free, Subject- and Daytime Invariant Approach
Benedikt W. Hosp, Bjorn Severitt, Rajat Agarwala, Evgenia Rusak, Yannick Sauer, Siegfried Wahl
In an era where personalized technology is increasingly intertwined with daily life, traditional eye-tracking systems and autofocal glasses face a significant challenge: the need for frequent, user-specific calibration, which impedes their practicality. This study introduces a groundbreaking calibration-free method for estimating focal depth, leveraging machine learning techniques to analyze eye movement features within short sequences. Our approach, distinguished by its innovative use of LSTM networks and domain-specific feature engineering, achieves a mean absolute error (MAE) of less than 10 cm, setting a new focal depth estimation accuracy standard. This advancement promises to enhance the usability of autofocal glasses and pave the way for their seamless integration into extended reality environments, marking a significant leap forward in personalized visual technology.
Read more8/9/2024
🔍
0
Fixation-based Self-calibration for Eye Tracking in VR Headsets
Ryusei Uramune, Sei Ikeda, Hiroki Ishizuka, Osamu Oshiro
This study proposes a novel self-calibration method for eye tracking in a virtual reality (VR) headset. The proposed method is based on the assumptions that the user's viewpoint can freely move and that the points of regard (PoRs) from different viewpoints are distributed within a small area on an object surface during visual fixation. In the method, fixations are first detected from the time-series data of uncalibrated gaze directions using an extension of the I-VDT (velocity and dispersion threshold identification) algorithm to a three-dimensional (3D) scene. Then, the calibration parameters are optimized by minimizing the sum of a dispersion metrics of the PoRs. The proposed method can potentially identify the optimal calibration parameters representing the user-dependent offset from the optical axis to the visual axis without explicit user calibration, image processing, or marker-substitute objects. For the gaze data of 18 participants walking in two VR environments with many occlusions, the proposed method achieved an accuracy of 2.1$^circ$, which was significantly lower than the average offset. Our method is the first self-calibration method with an average error lower than 3$^circ$ in 3D environments. Further, the accuracy of the proposed method can be improved by up to 1.2$^circ$ by refining the fixation detection or optimization algorithm.
Read more4/24/2024
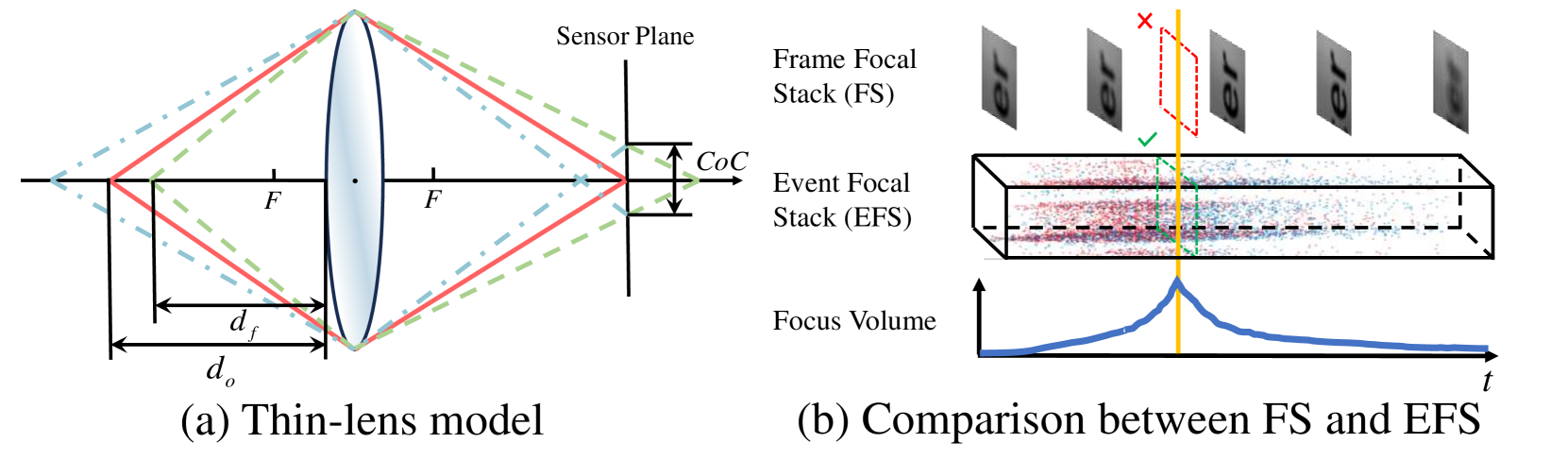
0
Learning Monocular Depth from Focus with Event Focal Stack
Chenxu Jiang, Mingyuan Lin, Chi Zhang, Zhenghai Wang, Lei Yu
Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.
Read more5/14/2024

0
Dusk Till Dawn: Self-supervised Nighttime Stereo Depth Estimation using Visual Foundation Models
Madhu Vankadari, Samuel Hodgson, Sangyun Shin, Kaichen Zhou Andrew Markham, Niki Trigoni
Self-supervised depth estimation algorithms rely heavily on frame-warping relationships, exhibiting substantial performance degradation when applied in challenging circumstances, such as low-visibility and nighttime scenarios with varying illumination conditions. Addressing this challenge, we introduce an algorithm designed to achieve accurate self-supervised stereo depth estimation focusing on nighttime conditions. Specifically, we use pretrained visual foundation models to extract generalised features across challenging scenes and present an efficient method for matching and integrating these features from stereo frames. Moreover, to prevent pixels violating photometric consistency assumption from negatively affecting the depth predictions, we propose a novel masking approach designed to filter out such pixels. Lastly, addressing weaknesses in the evaluation of current depth estimation algorithms, we present novel evaluation metrics. Our experiments, conducted on challenging datasets including Oxford RobotCar and Multi-Spectral Stereo, demonstrate the robust improvements realized by our approach. Code is available at: https://github.com/madhubabuv/dtd
Read more5/21/2024