The formation of perceptual space in early phonetic acquisition: a cross-linguistic modeling approach

0
🏷️
Sign in to get full access
Overview
- This study investigates how learners organize perceptual space during early phonetic acquisition.
- It examines the shape of the learned hidden representation and its ability to categorize phonetic categories.
- It explores the impact of training models on context-free acoustic information, without involving contextual cues, on phonetic acquisition.
- The study uses a cross-linguistic modeling approach, training autoencoder models on English and Mandarin, and evaluating them in both native and non-native conditions.
Plain English Explanation
The paper looks at how people learn to recognize different speech sounds, especially in the early stages of language learning. It has two main goals: [1] to understand the structure of the brain's representations of speech sounds, and [2] to see how this learning happens using only the basic acoustic information in speech, without any additional context.
The researchers used a type of AI model called an autoencoder to learn representations of speech sounds from audio data in English and Mandarin. They trained these models on just the basic acoustic properties of the sounds, without any other cues like who was speaking or what words were being said. Then they tested how well the models could categorize speech sounds, both in the languages they were trained on and in unfamiliar languages.
The results suggest that this basic, context-free learning leads to representations of speech sounds that are similar between a person's native language and other languages they don't know. This matches what we see in infants, who start out with a universal ability to perceive speech sounds before becoming specialized in their native language. The findings provide insights into how our brains organize perceptual space during early language learning.
Technical Explanation
The study uses autoencoder models to examine the organization of perceptual space in early phonetic acquisition. Autoencoders are a type of unsupervised neural network that learns to encode input data into a compressed representation and then decode it back to the original input.
In this case, the autoencoders were trained on context-free acoustic information from English and Mandarin speech data, without any additional contextual cues. This mimics the early stage of language learning, where infants are exposed to the basic sounds of speech before learning the patterns and meanings of their native language.
The researchers evaluated the trained models in both native and non-native conditions, following experimental setups used in infant language perception studies. This allowed them to examine the shape of the learned hidden representations and the models' ability to categorize phonetic categories.
The results demonstrate that the unsupervised, bottom-up training on context-free acoustic information leads to comparable learned representations of perceptual space between native and non-native conditions for both English and Mandarin. This mirrors the early stage of universal listening in infants before they become specialized in their native language.
Critical Analysis
The paper provides valuable insights into the organization of perceptual space during early phonetic acquisition. However, it is important to note that the study is limited to the use of autoencoder models trained on context-free acoustic information. While this approach mimics the early stage of language learning, it does not capture the full complexity of real-world language acquisition, which involves additional contextual cues and social interaction.
Furthermore, the paper does not address the potential impact of individual differences or the influence of specific language environments on the formation and representation of phonetic categories. Additional research is needed to understand how these factors may shape the organization of perceptual space and the development of phonetic categories.
Conclusion
This study offers important insights into the organization of perceptual space during early phonetic acquisition. By using a cross-linguistic modeling approach and focusing on context-free acoustic information, the researchers have shed light on the initial, universal stage of speech sound learning observed in infants. These findings contribute to our understanding of how phonetic categories are formed and represented in the brain, with potential implications for language learning and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
The formation of perceptual space in early phonetic acquisition: a cross-linguistic modeling approach
Frank Lihui Tan, Youngah Do
This study investigates how learners organize perceptual space in early phonetic acquisition by advancing previous studies in two key aspects. Firstly, it examines the shape of the learned hidden representation as well as its ability to categorize phonetic categories. Secondly, it explores the impact of training models on context-free acoustic information, without involving contextual cues, on phonetic acquisition, closely mimicking the early language learning stage. Using a cross-linguistic modeling approach, autoencoder models are trained on English and Mandarin and evaluated in both native and non-native conditions, following experimental conditions used in infant language perception studies. The results demonstrate that unsupervised bottom-up training on context-free acoustic information leads to comparable learned representations of perceptual space between native and non-native conditions for both English and Mandarin, resembling the early stage of universal listening in infants. These findings provide insights into the organization of perceptual space during early phonetic acquisition and contribute to our understanding of the formation and representation of phonetic categories.
Read more7/29/2024

0
Perception of Phonological Assimilation by Neural Speech Recognition Models
Charlotte Pouw, Marianne de Heer Kloots, Afra Alishahi, Willem Zuidema
Human listeners effortlessly compensate for phonological changes during speech perception, often unconsciously inferring the intended sounds. For example, listeners infer the underlying /n/ when hearing an utterance such as clea[m] pan, where [m] arises from place assimilation to the following labial [p]. This article explores how the neural speech recognition model Wav2Vec2 perceives assimilated sounds, and identifies the linguistic knowledge that is implemented by the model to compensate for assimilation during Automatic Speech Recognition (ASR). Using psycholinguistic stimuli, we systematically analyze how various linguistic context cues influence compensation patterns in the model's output. Complementing these behavioral experiments, our probing experiments indicate that the model shifts its interpretation of assimilated sounds from their acoustic form to their underlying form in its final layers. Finally, our causal intervention experiments suggest that the model relies on minimal phonological context cues to accomplish this shift. These findings represent a step towards better understanding the similarities and differences in phonological processing between neural ASR models and humans.
Read more6/24/2024
0
A predictive learning model can simulate temporal dynamics and context effects found in neural representations of continuous speech
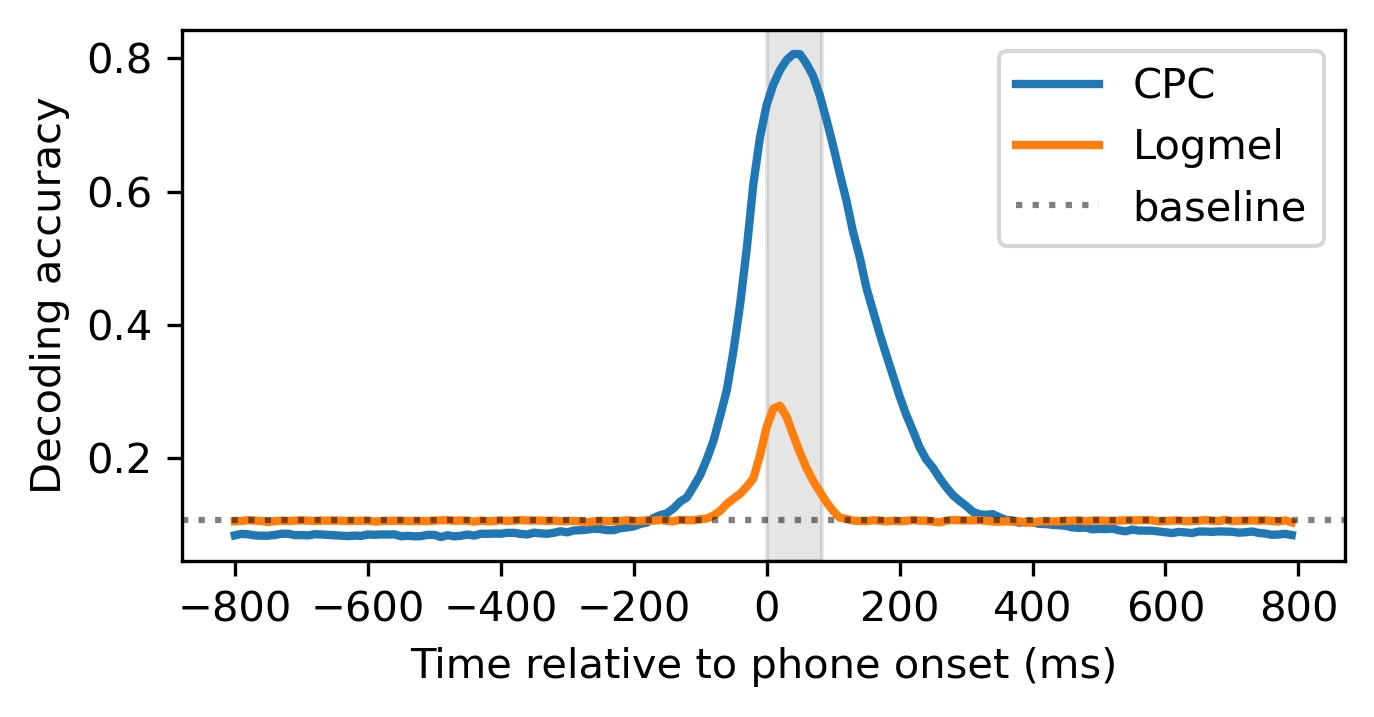
Oli Danyi Liu, Hao Tang, Naomi Feldman, Sharon Goldwater
Speech perception involves storing and integrating sequentially presented items. Recent work in cognitive neuroscience has identified temporal and contextual characteristics in humans' neural encoding of speech that may facilitate this temporal processing. In this study, we simulated similar analyses with representations extracted from a computational model that was trained on unlabelled speech with the learning objective of predicting upcoming acoustics. Our simulations revealed temporal dynamics similar to those in brain signals, implying that these properties can arise without linguistic knowledge. Another property shared between brains and the model is that the encoding patterns of phonemes support some degree of cross-context generalization. However, we found evidence that the effectiveness of these generalizations depends on the specific contexts, which suggests that this analysis alone is insufficient to support the presence of context-invariant encoding.
Read more5/15/2024
0
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
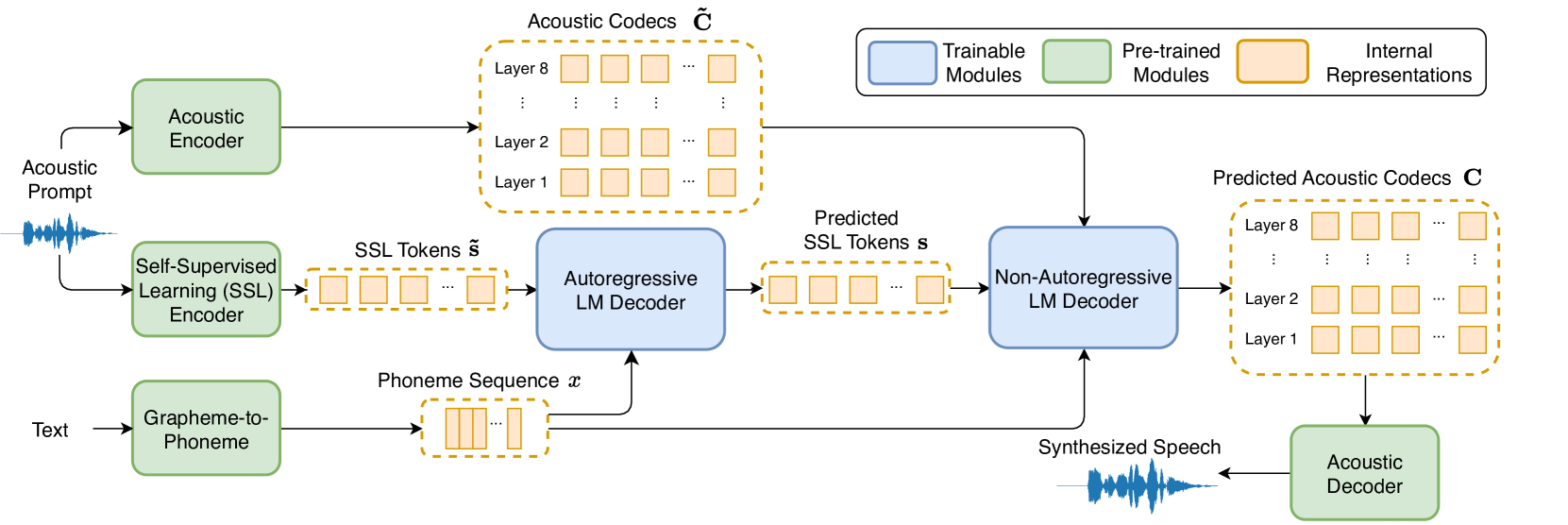
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024