FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network

0

Sign in to get full access
Overview
- This paper presents FPsPIN, an open-hardware research platform for processing data in network infrastructure using field-programmable gate arrays (FPGAs).
- FPsPIN aims to enable researchers to easily develop and deploy custom network processing functionalities on FPGA-based network devices.
- The platform provides a modular and extensible design that simplifies the integration of FPGA-based processing components into network equipment.
Plain English Explanation
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network is a research platform that allows engineers and scientists to easily create and test new ways of processing data as it travels through computer networks. The key idea is to use a type of computer chip called an FPGA, which can be programmed to perform specialized tasks very efficiently.
By providing a modular and flexible design, FPsPIN makes it simpler for researchers to integrate their custom FPGA-based processing components into network devices like routers and switches. This opens up new possibilities for improving network performance, security, and functionality, as researchers can experiment with novel ways of analyzing and manipulating data in the network infrastructure itself, rather than just at the endpoints.
Technical Explanation
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network is an open-source hardware platform that enables researchers to easily develop and deploy custom network processing functionalities using field-programmable gate arrays (FPGAs). The modular and extensible design of FPsPIN simplifies the integration of FPGA-based processing components into network equipment, such as routers and switches.
The platform consists of a custom FPGA board that can be easily connected to network devices through standard interfaces like Ethernet. Researchers can then develop their own FPGA-based processing modules and integrate them with the FPsPIN board to perform specialized data processing tasks directly within the network infrastructure. This approach, known as "processing in the network," can lead to performance improvements and new capabilities compared to traditional network architectures.
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network provides a flexible software framework and a set of reference hardware designs to help researchers quickly prototype and deploy their network processing solutions. The platform supports common network protocols and provides interfaces for integrating with existing network management and control systems.
Critical Analysis
The FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network platform addresses an important challenge in network research by enabling the exploration of novel in-network processing techniques. By providing an open-hardware platform, the authors aim to lower the barrier for researchers to experiment with FPGA-based network processing solutions.
One potential limitation of the platform is the specific hardware configuration, which may not be suitable for all types of network research. The authors acknowledge this and suggest that the modular design allows for customization and integration with other FPGA-based systems. Additionally, the performance and energy efficiency of the FPGA-based processing compared to traditional software-based approaches could be an area for further investigation.
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network also raises interesting questions about the security and privacy implications of in-network processing, as researchers may have the ability to analyze and manipulate data flows in new ways. Addressing these concerns would be an important consideration for the widespread adoption of such platforms.
Conclusion
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network provides a flexible and extensible platform for researchers to explore new ways of processing data within computer networks. By leveraging the performance and customizability of FPGAs, the platform enables the development of innovative network processing functionalities that could lead to improvements in areas such as network performance, security, and application-specific optimizations.
The open-hardware design of FPsPIN lowers the barrier for entry and encourages collaboration in the network research community, potentially accelerating the development of novel in-network processing techniques. As researchers continue to explore the capabilities and implications of this approach, FPsPIN could play a significant role in advancing the field of network infrastructure and the way data is handled within computer networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FPsPIN: An FPGA-based Open-Hardware Research Platform for Processing in the Network
Timo Schneider, Pengcheng Xu, Torsten Hoefler
In the era of post-Moore computing, network offload emerges as a solution to two challenges: the imperative for low-latency communication and the push towards hardware specialisation. Various methods have been employed to offload protocol- and data-processing onto network interface cards (NICs), from firmware modification to running full Linux on NICs for application execution. The sPIN project enables users to define handlers executed upon packet arrival. While simulations show sPIN's potential across diverse workloads, a full-system evaluation is lacking. This work presents FPsPIN, a full FPGA-based implementation of sPIN. FPsPIN is showcased through offloaded MPI datatype processing, achieving a 96% overlap ratio. FPsPIN provides an adaptable open-source research platform for researchers to conduct end-to-end experiments on smart NICs.
Read more5/28/2024

0
Advancements in Traffic Processing Using Programmable Hardware Flow Offload
Luca Deri, Alfredo Cardigliano, Francesco Fusco
The exponential growth of data traffic and the increasing complexity of networked applications demand effective solutions capable of passively inspecting and analysing the network traffic for monitoring and security purposes. Implementing network probes in software using general-purpose operating systems has been made possible by advances in packet-capture technologies, such as kernel-bypass frameworks, and by multi-queue adapters designed to distribute the network workload in multi-core processors. Modern SmartNICs, in addition, have introduced stateful mechanisms to associate actions to network flows such as forwarding packets or updating traffic statistics for an individual flow. In this paper, we describe our experience in exploiting those functionalities in a modern network probe and we perform a detailed study of the performance characteristics under different scenarios. Compared to pure CPU-based solutions, SmartNICs with flow-offload technologies provide substantial benefits when implementing forwarding applications. However, the main limitation of having to keep large flow tables in the host memory remains largely unsolved for realistic monitoring and security applications.
Read more7/24/2024
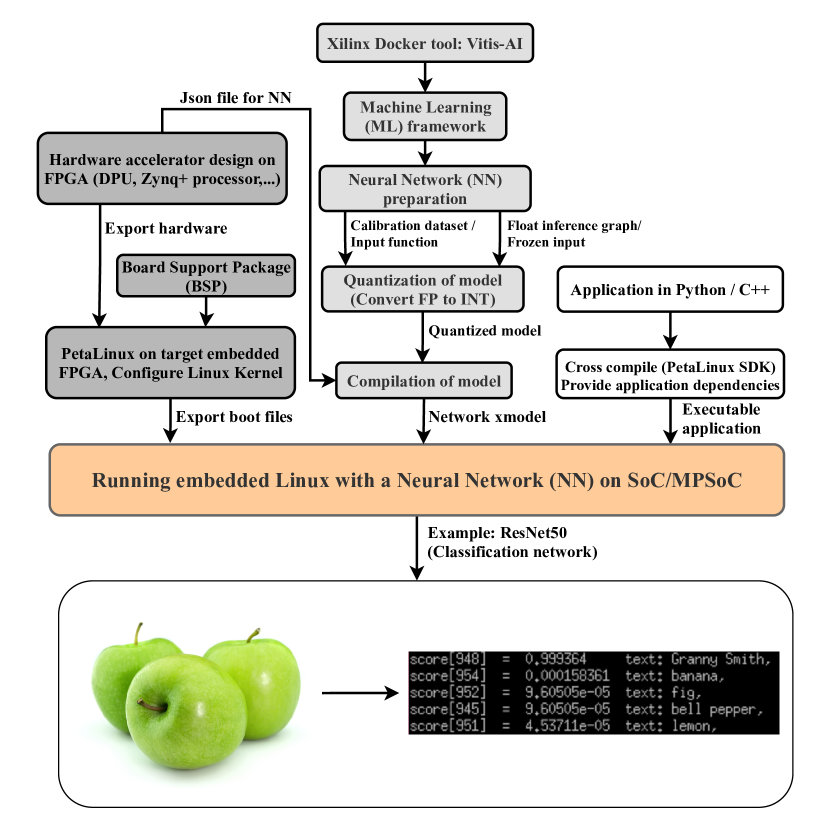
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024

0
Extracting TCPIP Headers at High Speed for the Anonymized Network Traffic Graph Challenge
Zhaoyang Han, Andrew Briasco-Stewart, Michael Zink, Miriam Leeser
Field Programmable Gate Arrays (FPGAs) play a significant role in computationally intensive network processing due to their flexibility and efficiency. Particularly with the high-level abstraction of the P4 network programming model, FPGA shows a powerful potential for packet processing. By supporting the P4 language with FPGA processing, network researchers can create customized FPGA-based network functions and execute network tasks on accelerators directly connected to the network. A feature of the P4 language is that it is stateless; however, the FPGA implementation in this research requires state information. This is accomplished using P4 externs to describe the stateful portions of the design and to implement them on the FPGA using High-Level Synthesis (HLS). This paper demonstrates using an FPGA-based SmartNIC to efficiently extract source-destination IP address information from network packets and construct anonymized network traffic matrices for further analysis. The implementation is the first example of the combination of using P4 and HLS in developing network functions on the latest AMD FPGAs. Our design achieves a processing rate of approximately 95 Gbps with the combined use of P4 and High-level Synthesis and is able to keep up with 100 Gbps traffic received directly from the network.
Read more9/12/2024