From Bytes to Borsch: Fine-Tuning Gemma and Mistral for the Ukrainian Language Representation

0

Sign in to get full access
Overview
- This paper focuses on fine-tuning two large language models, Gemma and Mistral, for representing the Ukrainian language.
- The researchers explore the challenges of training language models on low-resource languages like Ukrainian, and how to effectively leverage cross-lingual knowledge to improve performance.
- The paper also covers data augmentation techniques to adapt language models to dialectal variations in Ukrainian.
- Additionally, the researchers benchmark the performance of Gemma and Mistral on various Ukrainian language tasks, providing insights into the capabilities and limitations of these models.
Plain English Explanation
In this paper, the researchers explore ways to improve the ability of large language models, like Gemma and Mistral, to understand and generate Ukrainian text. Ukrainian is considered a low-resource language, meaning there is less data available to train these models compared to more widely spoken languages.
The researchers describe techniques they used to "fine-tune" the pre-trained Gemma and Mistral models on Ukrainian data, helping them better understand the unique vocabulary, grammar, and phrasing of the language. They also looked at ways to leverage knowledge from other languages, like Russian, to improve the models' performance on Ukrainian tasks.
Another key aspect of the research is how the team handled the dialects and regional variations found within the Ukrainian language. They used data augmentation techniques to diversify the training data and help the models adapt to these linguistic differences.
Finally, the researchers evaluated the performance of the fine-tuned Gemma and Mistral models on a variety of Ukrainian language tasks, such as text classification and question answering. This allowed them to assess the strengths and limitations of these models when working with Ukrainian, providing valuable insights for future research and development in this area.
Technical Explanation
The researchers in this paper focused on fine-tuning two large language models, Gemma and Mistral, for better representation of the Ukrainian language. Ukrainian is considered a low-resource language, meaning there is limited training data available compared to more widely spoken languages.
To address this challenge, the team explored techniques to leverage cross-lingual knowledge, such as using data from related languages like Russian, to improve the models' understanding of Ukrainian. They also employed data augmentation methods, like back-translation and text editing, to diversify the training data and help the models adapt to dialectal variations within the Ukrainian language.
The researchers then evaluated the performance of the fine-tuned Gemma and Mistral models on a range of Ukrainian language tasks, including text classification, question answering, and natural language inference. This benchmarking process provided valuable insights into the capabilities and limitations of these models when working with Ukrainian text.
Critical Analysis
The researchers in this paper acknowledge the inherent challenges of working with low-resource languages like Ukrainian, and they make a concerted effort to address these challenges through various techniques. The use of cross-lingual knowledge and data augmentation is a promising approach, and the benchmarking of the fine-tuned models on diverse tasks gives a comprehensive view of their performance.
However, the paper does not delve deeply into the specific limitations or potential issues with the fine-tuning process or the models' performance. For example, it would be helpful to understand the extent to which the cross-lingual knowledge transfer was effective, or the specific types of dialectal variations that proved most challenging for the models.
Additionally, the researchers could have explored the potential societal implications of their work, such as how these models could be used to improve language accessibility or support the preservation of the Ukrainian language and culture. Engaging with these broader considerations could further strengthen the impact and relevance of the research.
Conclusion
This paper presents a comprehensive study on fine-tuning large language models, specifically Gemma and Mistral, for representing the Ukrainian language. The researchers demonstrate effective strategies for leveraging cross-lingual knowledge and data augmentation to address the challenges of working with low-resource languages.
The benchmarking results provide valuable insights into the capabilities and limitations of these models when working with Ukrainian text, which can inform future research and development efforts in this area. While the paper could benefit from a more in-depth critical analysis, the overall work represents a significant contribution to the field of natural language processing and the advancement of language technologies for under-represented languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Bytes to Borsch: Fine-Tuning Gemma and Mistral for the Ukrainian Language Representation
Artur Kiulian, Anton Polishko, Mykola Khandoga, Oryna Chubych, Jack Connor, Raghav Ravishankar, Adarsh Shirawalmath
In the rapidly advancing field of AI and NLP, generative large language models (LLMs) stand at the forefront of innovation, showcasing unparalleled abilities in text understanding and generation. However, the limited representation of low-resource languages like Ukrainian poses a notable challenge, restricting the reach and relevance of this technology. Our paper addresses this by fine-tuning the open-source Gemma and Mistral LLMs with Ukrainian datasets, aiming to improve their linguistic proficiency and benchmarking them against other existing models capable of processing Ukrainian language. This endeavor not only aims to mitigate language bias in technology but also promotes inclusivity in the digital realm. Our transparent and reproducible approach encourages further NLP research and development. Additionally, we present the Ukrainian Knowledge and Instruction Dataset (UKID) to aid future efforts in language model fine-tuning. Our research not only advances the field of NLP but also highlights the importance of linguistic diversity in AI, which is crucial for cultural preservation, education, and expanding AI's global utility. Ultimately, we advocate for a future where technology is inclusive, enabling AI to communicate effectively across all languages, especially those currently underrepresented.
Read more4/16/2024

0
GemmAr: Enhancing LLMs Through Arabic Instruction-Tuning
Hasna Chouikhi, Manel Aloui, Cyrine Ben Hammou, Ghaith Chaabane, Haithem Kchaou, Chehir Dhaouadi
Large language models (LLMs) have greatly impacted the natural language processing (NLP) field, particularly for the English language. These models have demonstrated capabilities in understanding and generating human-like text. The success of language models largely depends on the availability of high-quality instruction datasets, which consist of detailed task descriptions and corresponding responses that are essential for training the models to address a variety of prompts accurately. However, the availability and quality of these resources vary by language. While models perform well in English, they often need help with languages like Arabic, due to the lack of datasets for fine-tuning Arabic-specific tasks. To address this issue, we introduce InstAr-500k, a new Arabic instruction dataset created by generating and collecting content that covers several domains and instruction types. We assess this dataset by fine-tuning an open-source Gemma-7B model on several downstream tasks to improve its functionality. Based on multiple evaluations, our fine-tuned model achieves excellent performance on several Arabic NLP benchmarks. These outcomes emphasize the effectiveness of our dataset in elevating the capabilities of language models for Arabic. Our instruction dataset bridges the performance gap between English and Arabic language models by providing resources that amplify Arabic NLP development. Building on this foundation, we developed a model, GemmAr-7B-V1, specifically tuned to excel at a wide range of Arabic NLP tasks.
Read more7/10/2024
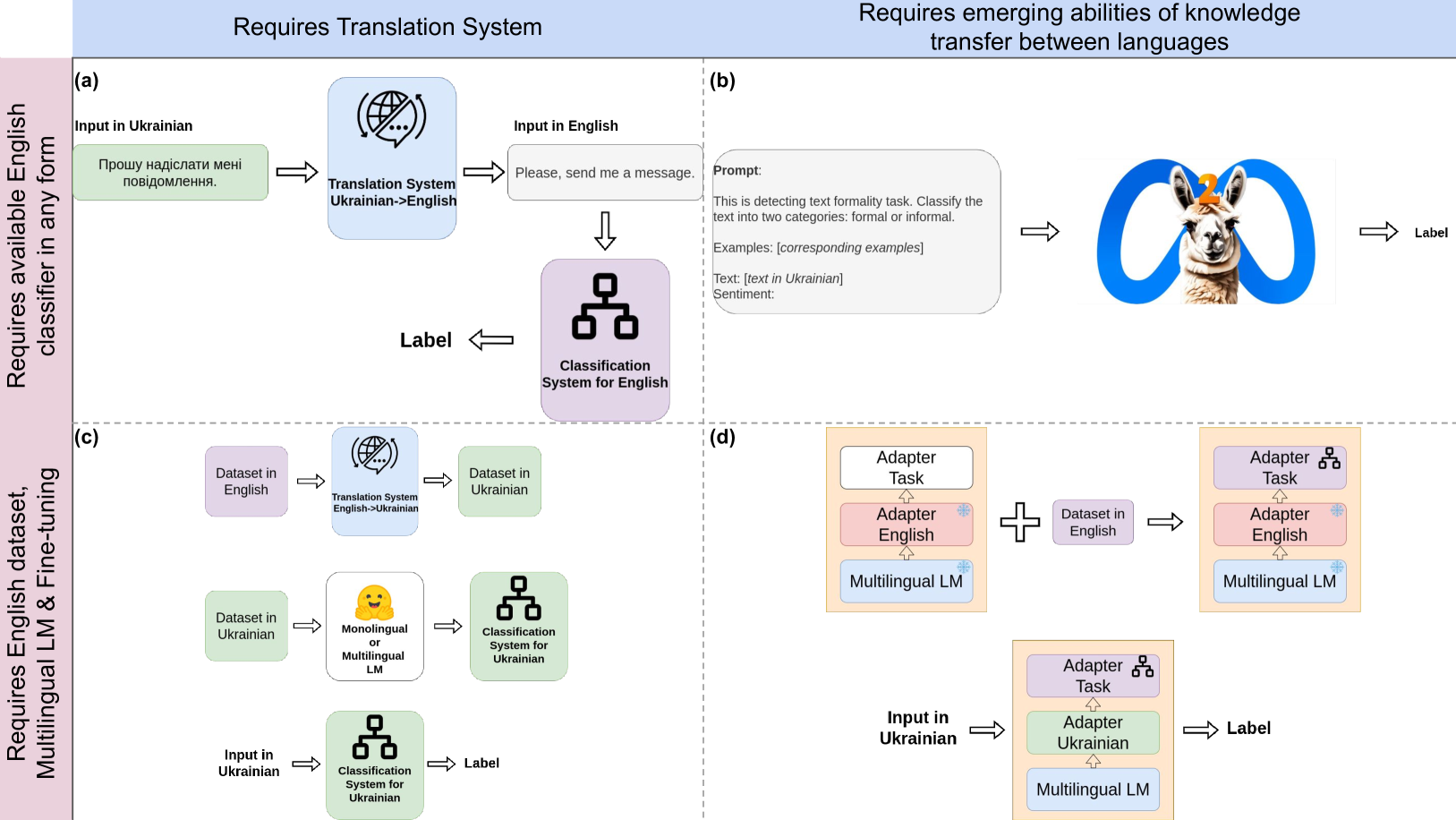
0
Ukrainian Texts Classification: Exploration of Cross-lingual Knowledge Transfer Approaches
Daryna Dementieva, Valeriia Khylenko, Georg Groh
Despite the extensive amount of labeled datasets in the NLP text classification field, the persistent imbalance in data availability across various languages remains evident. Ukrainian, in particular, stands as a language that still can benefit from the continued refinement of cross-lingual methodologies. Due to our knowledge, there is a tremendous lack of Ukrainian corpora for typical text classification tasks. In this work, we leverage the state-of-the-art advances in NLP, exploring cross-lingual knowledge transfer methods avoiding manual data curation: large multilingual encoders and translation systems, LLMs, and language adapters. We test the approaches on three text classification tasks -- toxicity classification, formality classification, and natural language inference -- providing the recipe for the optimal setups.
Read more4/3/2024
💬
0
UCCIX: Irish-eXcellence Large Language Model
Khanh-Tung Tran, Barry O'Sullivan, Hoang D. Nguyen
The development of Large Language Models (LLMs) has predominantly focused on high-resource languages, leaving extremely low-resource languages like Irish with limited representation. This work presents UCCIX, a pioneering effort on the development of an open-source Irish-based LLM. We propose a novel framework for continued pre-training of LLMs specifically adapted for extremely low-resource languages, requiring only a fraction of the textual data typically needed for training LLMs according to scaling laws. Our model, based on Llama 2-13B, outperforms much larger models on Irish language tasks with up to 12% performance improvement, showcasing the effectiveness and efficiency of our approach. We also contribute comprehensive Irish benchmarking datasets, including IrishQA, a question-answering dataset, and Irish version of MT-bench. These datasets enable rigorous evaluation and facilitate future research in Irish LLM systems. Our work aims to preserve and promote the Irish language, knowledge, and culture of Ireland in the digital era while providing a framework for adapting LLMs to other indigenous languages.
Read more5/24/2024