From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding

0
🤔
Sign in to get full access
Overview
- Researchers have long been interested in understanding human actions and how they can be mapped between physical and semantic spaces.
- Existing datasets for action recognition are often incompatible due to differences in how actions are defined and categorized.
- The authors argue for a more principled approach to building a unified semantic space for actions that can better leverage diverse datasets.
Plain English Explanation
The paper addresses a longstanding challenge in the field of action understanding - how to unify the various datasets and definitions used by researchers to advance the state of the art. Today, different research teams build their own datasets, each with their own particular way of categorizing and labeling actions. This is like having a bunch of isolated "islands" of data that can't easily be combined.
The authors propose a solution to this problem. They start by designing a structured, hierarchical semantic space that can accommodate a wide range of human actions, based on a verb taxonomy. They then align the classes from previous datasets to this common semantic framework, effectively "bridging the gaps" between the isolated datasets. This lets them gather all the available (image, video, motion capture, etc.) data into a unified "Pangea" - a single, comprehensive database with a common labeling system.
Building on this, the authors develop a new model that can map from the raw physical data (like videos or motion capture) directly to this structured semantic space. By using this unified dataset and model, they are able to achieve significantly better performance, especially when it comes to transferring learning to new tasks and datasets.
Technical Explanation
The core innovation in this work is the design of a structured action semantic space based on a verb taxonomy hierarchy. This provides a principled way to organize and unify the diverse set of action classes found across existing datasets.
The authors align the classes from previous datasets to this common semantic framework, allowing them to gather all the available (image, video, skeleton, motion capture) data into a unified "Pangea" database. They then propose a novel model architecture that can map directly from the physical input modalities to this structured semantic space.
In extensive experiments, the authors show that their unified Pangea dataset and semantic mapping model outperform previous state-of-the-art approaches, especially when it comes to transfer learning to new tasks and datasets. This demonstrates the value of their principled approach to action representation and the benefits of being able to leverage diverse data sources in a cohesive way.
Critical Analysis
The authors make a compelling case for the need to move beyond the current piecemeal approach to action recognition datasets and instead work towards a more unified, principled semantic framework. By aligning diverse datasets to a common taxonomy, they are able to unlock new capabilities, particularly in transfer learning.
That said, the paper does not address some potential limitations of this approach. For example, the verb taxonomy hierarchy they use may not capture all the nuances and contextual factors that can influence how actions are perceived and categorized. Additionally, the process of mapping existing dataset classes to the semantic space likely involves some subjective judgment calls that could impact the resulting unification.
Further research would be needed to fully understand the strengths and weaknesses of this unified semantic approach, as well as how it compares to other attempts to bridge the gaps between action recognition datasets. Nonetheless, this work represents an important step forward in tackling a longstanding challenge in the field.
Conclusion
This paper proposes a novel approach to action understanding that aims to unify the fragmented landscape of action recognition datasets. By designing a structured semantic space based on verb taxonomy, and aligning existing datasets to this common framework, the authors are able to create a comprehensive "Pangea" database that can be leveraged by a new mapping model.
The results demonstrate the value of this principled approach, with significant performance gains, particularly in transfer learning scenarios. While there are some potential limitations to address, this work represents an important advance that could help drive the field of action understanding towards more generalizable and impactful solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Yong-Lu Li, Xiaoqian Wu, Xinpeng Liu, Zehao Wang, Yiming Dou, Yikun Ji, Junyi Zhang, Yixing Li, Jingru Tan, Xudong Lu, Cewu Lu
Action understanding has attracted long-term attention. It can be formed as the mapping from the physical space to the semantic space. Typically, researchers built datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Datasets are incompatible with each other like Isolated Islands due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that we need a more principled semantic space to concentrate the community efforts and use all datasets together to pursue generalizable action learning. To this end, we design a structured action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging isolated islands into a Pangea. Accordingly, we propose a novel model mapping from the physical space to semantic space to fully use Pangea. In extensive experiments, our new system shows significant superiority, especially in transfer learning. Our code and data will be made public at https://mvig-rhos.com/pangea.
Read more4/4/2024

0
Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Qilong Zhangli, Di Liu, Abhishek Aich, Dimitris Metaxas, Samuel Schulter
Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class person in one dataset and class face in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
Read more9/17/2024
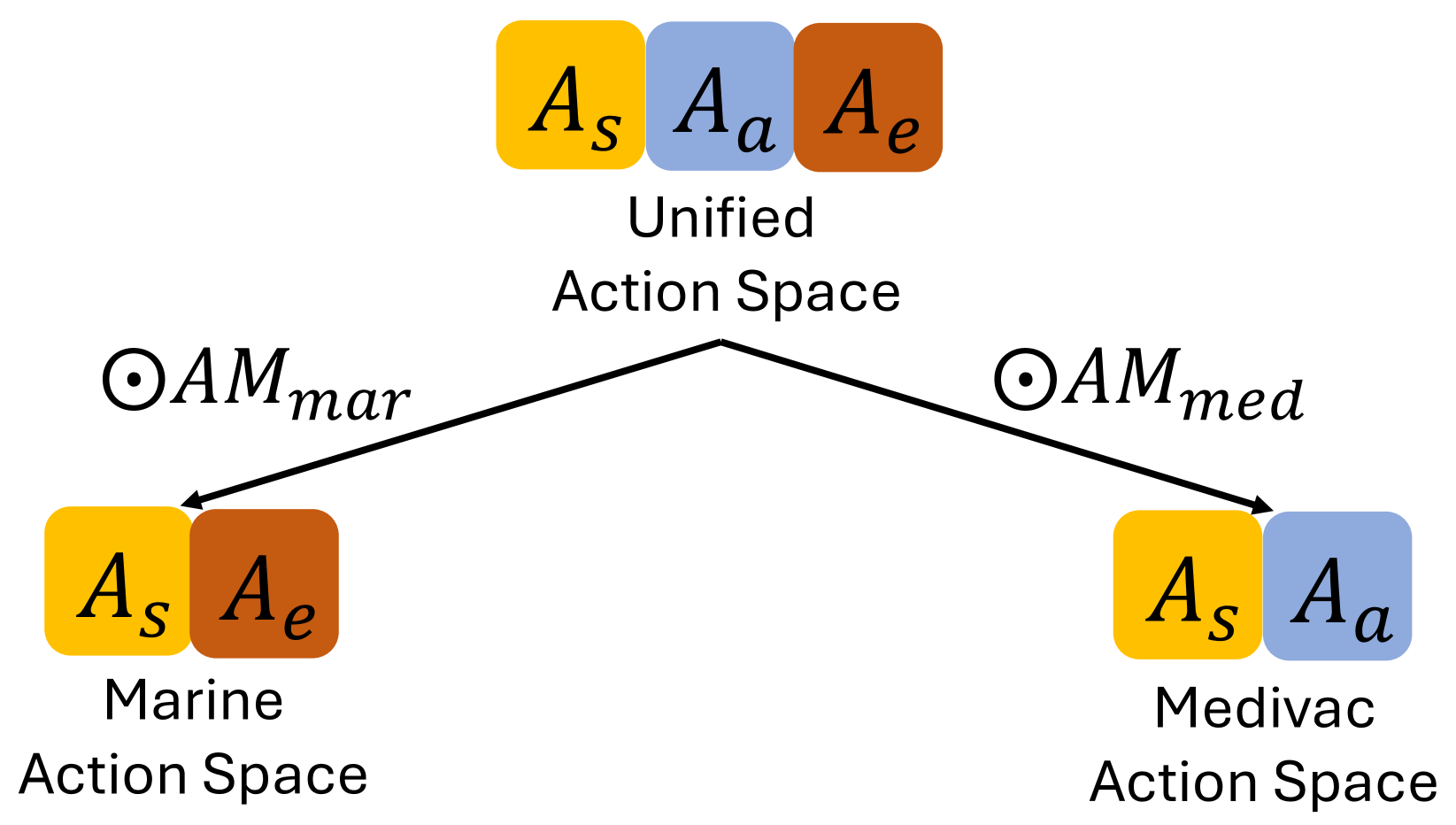
0
Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space
Xiaoyang Yu, Youfang Lin, Shuo Wang, Kai Lv, Sheng Han
In a multi-agent system (MAS), action semantics indicates the different influences of agents' actions toward other entities, and can be used to divide agents into groups in a physically heterogeneous MAS. Previous multi-agent reinforcement learning (MARL) algorithms apply global parameter-sharing across different types of heterogeneous agents without careful discrimination of different action semantics. This common implementation decreases the cooperation and coordination between agents in complex situations. However, fully independent agent parameters dramatically increase the computational cost and training difficulty. In order to benefit from the usage of different action semantics while also maintaining a proper parameter-sharing structure, we introduce the Unified Action Space (UAS) to fulfill the requirement. The UAS is the union set of all agent actions with different semantics. All agents first calculate their unified representation in the UAS, and then generate their heterogeneous action policies using different available-action-masks. To further improve the training of extra UAS parameters, we introduce a Cross-Group Inverse (CGI) loss to predict other groups' agent policies with the trajectory information. As a universal method for solving the physically heterogeneous MARL problem, we implement the UAS adding to both value-based and policy-based MARL algorithms, and propose two practical algorithms: U-QMIX and U-MAPPO. Experimental results in the SMAC environment prove the effectiveness of both U-QMIX and U-MAPPO compared with several state-of-the-art MARL methods.
Read more8/15/2024

0
Bridging the Gap between Human Motion and Action Semantics via Kinematic Phrases
Xinpeng Liu, Yong-Lu Li, Ailing Zeng, Zizheng Zhou, Yang You, Cewu Lu
Motion understanding aims to establish a reliable mapping between motion and action semantics, while it is a challenging many-to-many problem. An abstract action semantic (i.e., walk forwards) could be conveyed by perceptually diverse motions (walking with arms up or swinging). In contrast, a motion could carry different semantics w.r.t. its context and intention. This makes an elegant mapping between them difficult. Previous attempts adopted direct-mapping paradigms with limited reliability. Also, current automatic metrics fail to provide reliable assessments of the consistency between motions and action semantics. We identify the source of these problems as the significant gap between the two modalities. To alleviate this gap, we propose Kinematic Phrases (KP) that take the objective kinematic facts of human motion with proper abstraction, interpretability, and generality. Based on KP, we can unify a motion knowledge base and build a motion understanding system. Meanwhile, KP can be automatically converted from motions to text descriptions with no subjective bias, inspiring Kinematic Prompt Generation (KPG) as a novel white-box motion generation benchmark. In extensive experiments, our approach shows superiority over other methods. Our project is available at https://foruck.github.io/KP/.
Read more7/15/2024