Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space

0
Sign in to get full access
Overview
- The paper proposes a novel approach to improve global parameter-sharing in physically heterogeneous multi-agent reinforcement learning with a unified action space.
- The key idea is to utilize a centralized critic network that can learn to effectively share parameters across agents with different physical characteristics.
- The authors demonstrate the effectiveness of their method through experiments on a challenging multi-agent environment.
Plain English Explanation
The paper tackles the problem of multi-agent reinforcement learning in a setting where the agents have different physical characteristics, such as size, weight, or speed. This is a common scenario in real-world applications, such as a team of robots with varying capabilities working together to accomplish a task.
One of the main challenges in this setting is how to effectively share knowledge and parameters across the different agents. The authors propose a solution that involves using a centralized critic network to learn a unified representation of the agents' actions, which can then be used to guide the individual agents' policies.
This approach allows the agents to learn from each other's experiences, even though they have different physical characteristics. By using a shared critic network, the agents can leverage the collective knowledge of the group, rather than each agent having to learn everything from scratch.
The authors demonstrate the effectiveness of their method through experiments in a challenging multi-agent environment, where the agents need to coordinate their actions to achieve a common goal. The results show that the proposed approach outperforms alternative methods, particularly in scenarios where the agents have significant physical differences.
Technical Explanation
The key innovation in this paper is the use of a centralized critic network to facilitate global parameter-sharing in a multi-agent reinforcement learning setting with physically heterogeneous agents.
The authors propose a framework where each agent maintains its own policy network, but a single critic network is shared across all agents. The critic network is trained to learn a unified representation of the agents' actions, which can then be used to guide the individual agents' policies.
This approach leverages the collective experience of the group, allowing agents with different physical characteristics to learn from each other's experiences. By using a shared critic, the agents can develop a common understanding of the task and the optimal actions to take, even though their individual policies may differ.
The authors evaluate their method on a challenging multi-agent environment, where the agents need to coordinate their actions to achieve a common goal. They compare their approach to alternative methods, such as MESA, and demonstrate that their method outperforms the baselines, particularly in scenarios where the agents have significant physical differences.
Critical Analysis
One potential limitation of the proposed approach is that the centralized critic network may struggle to capture the nuances of each agent's physical characteristics, especially in more complex environments. While the shared representation can help the agents learn from each other, it may not be able to fully account for the unique challenges faced by each agent.
Additionally, the reliance on a centralized critic network introduces a potential bottleneck, as all agents need to communicate with the critic to receive guidance. This could limit the scalability of the approach, especially in large-scale multi-agent systems.
The authors do not explore the impact of the number of agents or the degree of heterogeneity on the performance of their method. It would be valuable to understand the limits of their approach and the conditions under which it is most effective.
Furthermore, the paper does not discuss the potential challenges of training the centralized critic network, such as the stability of the learning process or the sensitivity to hyperparameter choices. These practical considerations would be important to address for the successful deployment of the proposed method in real-world applications.
Conclusion
The paper presents a novel approach to improve global parameter-sharing in physically heterogeneous multi-agent reinforcement learning, using a centralized critic network to learn a unified representation of the agents' actions. The authors demonstrate the effectiveness of their method through experiments, showing that it outperforms alternative approaches in challenging multi-agent environments.
This work contributes to the broader field of multi-agent reinforcement learning, providing a promising solution to the challenge of learning in heterogeneous agent settings. The centralized critic network approach offers a way to leverage the collective knowledge of a group of agents, even when they have different physical capabilities, which could have significant implications for the development of more robust and adaptable multi-agent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space
Xiaoyang Yu, Youfang Lin, Shuo Wang, Kai Lv, Sheng Han
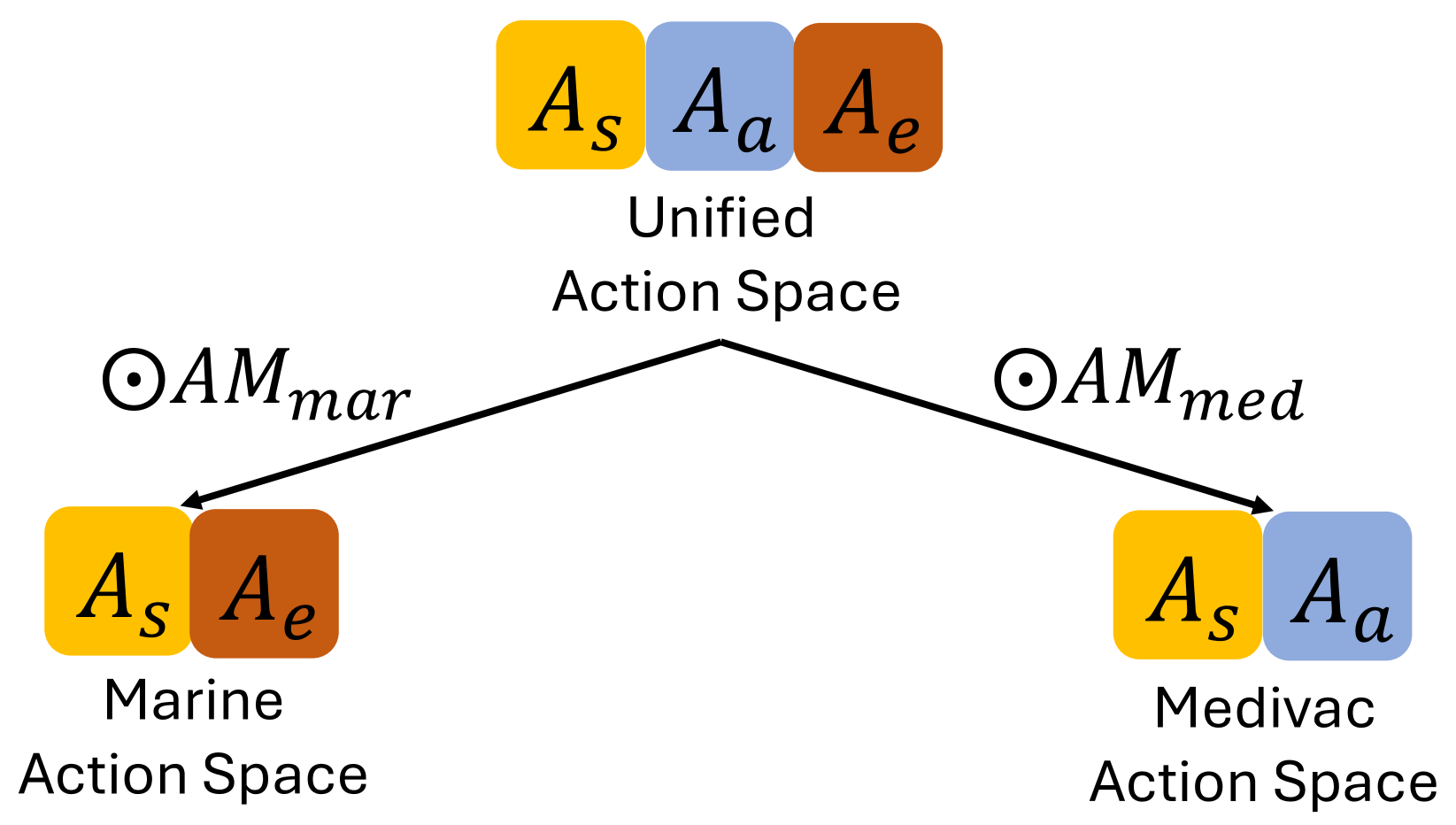
In a multi-agent system (MAS), action semantics indicates the different influences of agents' actions toward other entities, and can be used to divide agents into groups in a physically heterogeneous MAS. Previous multi-agent reinforcement learning (MARL) algorithms apply global parameter-sharing across different types of heterogeneous agents without careful discrimination of different action semantics. This common implementation decreases the cooperation and coordination between agents in complex situations. However, fully independent agent parameters dramatically increase the computational cost and training difficulty. In order to benefit from the usage of different action semantics while also maintaining a proper parameter-sharing structure, we introduce the Unified Action Space (UAS) to fulfill the requirement. The UAS is the union set of all agent actions with different semantics. All agents first calculate their unified representation in the UAS, and then generate their heterogeneous action policies using different available-action-masks. To further improve the training of extra UAS parameters, we introduce a Cross-Group Inverse (CGI) loss to predict other groups' agent policies with the trajectory information. As a universal method for solving the physically heterogeneous MARL problem, we implement the UAS adding to both value-based and policy-based MARL algorithms, and propose two practical algorithms: U-QMIX and U-MAPPO. Experimental results in the SMAC environment prove the effectiveness of both U-QMIX and U-MAPPO compared with several state-of-the-art MARL methods.
Read more8/15/2024
0
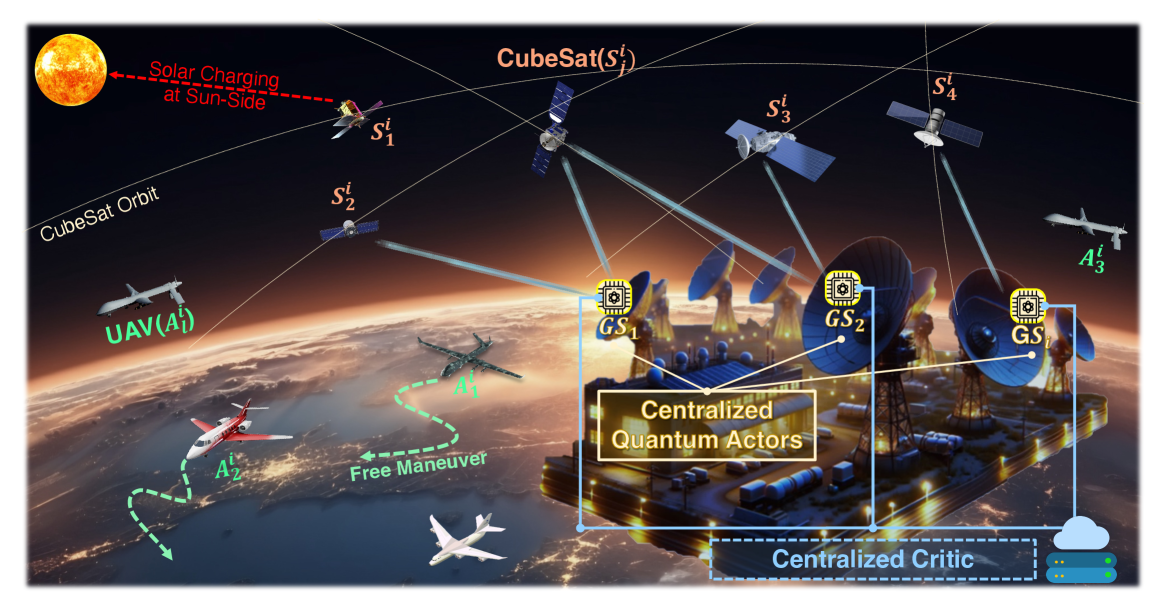
Quantum Multi-Agent Reinforcement Learning for Cooperative Mobile Access in Space-Air-Ground Integrated Networks
Gyu Seon Kim, Yeryeong Cho, Jaehyun Chung, Soohyun Park, Soyi Jung, Zhu Han, Joongheon Kim
Achieving global space-air-ground integrated network (SAGIN) access only with CubeSats presents significant challenges such as the access sustainability limitations in specific regions (e.g., polar regions) and the energy efficiency limitations in CubeSats. To tackle these problems, high-altitude long-endurance unmanned aerial vehicles (HALE-UAVs) can complement these CubeSat shortcomings for providing cooperatively global access sustainability and energy efficiency. However, as the number of CubeSats and HALE-UAVs, increases, the scheduling dimension of each ground station (GS) increases. As a result, each GS can fall into the curse of dimensionality, and this challenge becomes one major hurdle for efficient global access. Therefore, this paper provides a quantum multi-agent reinforcement Learning (QMARL)-based method for scheduling between GSs and CubeSats/HALE-UAVs in order to improve global access availability and energy efficiency. The main reason why the QMARL-based scheduler can be beneficial is that the algorithm facilitates a logarithmic-scale reduction in scheduling action dimensions, which is one critical feature as the number of CubeSats and HALE-UAVs expands. Additionally, individual GSs have different traffic demands depending on their locations and characteristics, thus it is essential to provide differentiated access services. The superiority of the proposed scheduler is validated through data-intensive experiments in realistic CubeSat/HALE-UAV settings.
Read more6/26/2024

0
Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Xudong Guo, Daming Shi, Junjie Yu, Wenhui Fan
The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
Read more4/8/2024
0
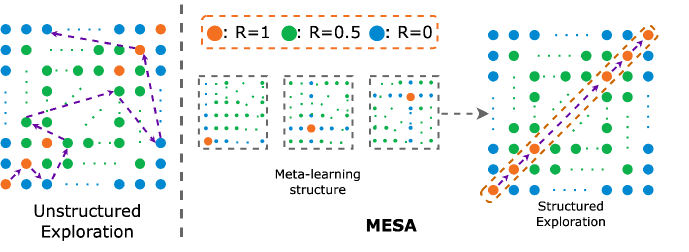
MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure
Zhicheng Zhang, Yancheng Liang, Yi Wu, Fei Fang
Multi-agent reinforcement learning (MARL) algorithms often struggle to find strategies close to Pareto optimal Nash Equilibrium, owing largely to the lack of efficient exploration. The problem is exacerbated in sparse-reward settings, caused by the larger variance exhibited in policy learning. This paper introduces MESA, a novel meta-exploration method for cooperative multi-agent learning. It learns to explore by first identifying the agents' high-rewarding joint state-action subspace from training tasks and then learning a set of diverse exploration policies to cover the subspace. These trained exploration policies can be integrated with any off-policy MARL algorithm for test-time tasks. We first showcase MESA's advantage in a multi-step matrix game. Furthermore, experiments show that with learned exploration policies, MESA achieves significantly better performance in sparse-reward tasks in several multi-agent particle environments and multi-agent MuJoCo environments, and exhibits the ability to generalize to more challenging tasks at test time.
Read more5/3/2024