From Local to Global: A Graph RAG Approach to Query-Focused Summarization

0
👀
Sign in to get full access
Overview
- The paper introduces a new approach called Graph RAG (Retrieval-Augmented Generation) to improve question answering over large, private text corpora.
- Existing retrieval-augmented generation (RAG) systems struggle with "global" questions that require understanding the overall themes and content of a dataset, rather than just retrieving relevant information.
- Prior query-focused summarization (QFS) methods, on the other hand, cannot scale to the large quantities of text indexed by typical RAG systems.
- Graph RAG combines the strengths of these contrasting approaches to enable scalable, comprehensive question answering over private text collections.
Plain English Explanation
The paper describes a new way to help large language models (LLMs) like GPT-3 answer questions about private or previously unseen documents. Existing retrieval-augmented generation (RAG) systems can find relevant information to include in answers, but they struggle with "global" questions that ask about the overall themes and content of a whole dataset, rather than just specific details.
On the other hand, prior methods for generating summaries of a text corpus (query-focused summarization or QFS) can't handle the massive amounts of information that RAG systems typically index.
The new Graph RAG approach combines the strengths of these two approaches. It first builds a knowledge graph from the source documents, capturing the key entities and how they are related. It then generates summaries for groups of closely-related entities, called "communities." When answering a question, Graph RAG uses these pre-made community summaries to generate a preliminary response, and then summarizes all the partial responses into a final, comprehensive answer.
This allows Graph RAG to provide thorough, coherent answers to broad, "global" questions about an entire dataset, even when that dataset is very large (up to 1 million tokens). The authors show that this approach outperforms a basic RAG system at both comprehensiveness and diversity of the generated answers.
Technical Explanation
The key innovation in the Graph RAG approach is the two-stage process for building a text index and generating responses to user questions.
First, the system constructs an entity knowledge graph from the source documents. This captures the key entities (people, places, concepts, etc.) mentioned in the text, as well as the relationships between them. The system then pre-generates "community summaries" for groups of closely-related entities, essentially providing a high-level overview of the content and themes associated with each community.
When a user asks a question, the Graph RAG system uses these pre-made community summaries to generate a preliminary response. It does this by identifying the relevant communities based on the question, and then summarizing the information from those community summaries into a partial answer.
Finally, the system takes all of these partial responses and generates a comprehensive final answer by summarizing them together.
This two-stage approach allows Graph RAG to provide thorough, coherent answers to broad, "global" questions - something that standard RAG systems struggle with. By pre-computing the community summaries, Graph RAG can scale to handle very large text corpora, overcoming the limitations of prior query-focused summarization methods.
Critical Analysis
The authors acknowledge that their Graph RAG approach has some limitations. For example, the quality of the final answers is still dependent on the accuracy of the underlying entity knowledge graph and community summaries. If these are poorly constructed, the generated responses may be incomplete or inaccurate.
Additionally, the paper only evaluates Graph RAG on datasets up to 1 million tokens in size. It's unclear how well the approach would scale to even larger corpora that might be encountered in real-world applications.
That said, the core idea of combining the strengths of retrieval-augmented generation and query-focused summarization is compelling. With further research and refinement, Graph RAG could represent a significant advancement in the field of question answering over private text collections.
Conclusion
The Graph RAG approach introduced in this paper represents an interesting step forward in enabling large language models to comprehensively answer questions over large, private text corpora. By leveraging a two-stage process of building an entity knowledge graph and pre-generating community summaries, Graph RAG is able to overcome the limitations of both standard RAG systems and prior query-focused summarization methods.
While the approach has some potential limitations, the core idea of combining these complementary techniques is promising. Further research and development of Graph RAG could lead to significant improvements in the ability of AI systems to provide thorough, coherent answers to a wide range of questions about complex, real-world datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson
The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on global questions directed at an entire text corpus, such as What are the main themes in the dataset?, since this is inherently a query-focused summarization (QFS) task, rather than an explicit retrieval task. Prior QFS methods, meanwhile, fail to scale to the quantities of text indexed by typical RAG systems. To combine the strengths of these contrasting methods, we propose a Graph RAG approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text to be indexed. Our approach uses an LLM to build a graph-based text index in two stages: first to derive an entity knowledge graph from the source documents, then to pregenerate community summaries for all groups of closely-related entities. Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user. For a class of global sensemaking questions over datasets in the 1 million token range, we show that Graph RAG leads to substantial improvements over a naive RAG baseline for both the comprehensiveness and diversity of generated answers. An open-source, Python-based implementation of both global and local Graph RAG approaches is forthcoming at https://aka.ms/graphrag.
Read more4/26/2024

0
Graph Retrieval-Augmented Generation: A Survey
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, Siliang Tang
Recently, Retrieval-Augmented Generation (RAG) has achieved remarkable success in addressing the challenges of Large Language Models (LLMs) without necessitating retraining. By referencing an external knowledge base, RAG refines LLM outputs, effectively mitigating issues such as ``hallucination'', lack of domain-specific knowledge, and outdated information. However, the complex structure of relationships among different entities in databases presents challenges for RAG systems. In response, GraphRAG leverages structural information across entities to enable more precise and comprehensive retrieval, capturing relational knowledge and facilitating more accurate, context-aware responses. Given the novelty and potential of GraphRAG, a systematic review of current technologies is imperative. This paper provides the first comprehensive overview of GraphRAG methodologies. We formalize the GraphRAG workflow, encompassing Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation. We then outline the core technologies and training methods at each stage. Additionally, we examine downstream tasks, application domains, evaluation methodologies, and industrial use cases of GraphRAG. Finally, we explore future research directions to inspire further inquiries and advance progress in the field. In order to track recent progress in this field, we set up a repository at url{https://github.com/pengboci/GraphRAG-Survey}.
Read more9/11/2024
0
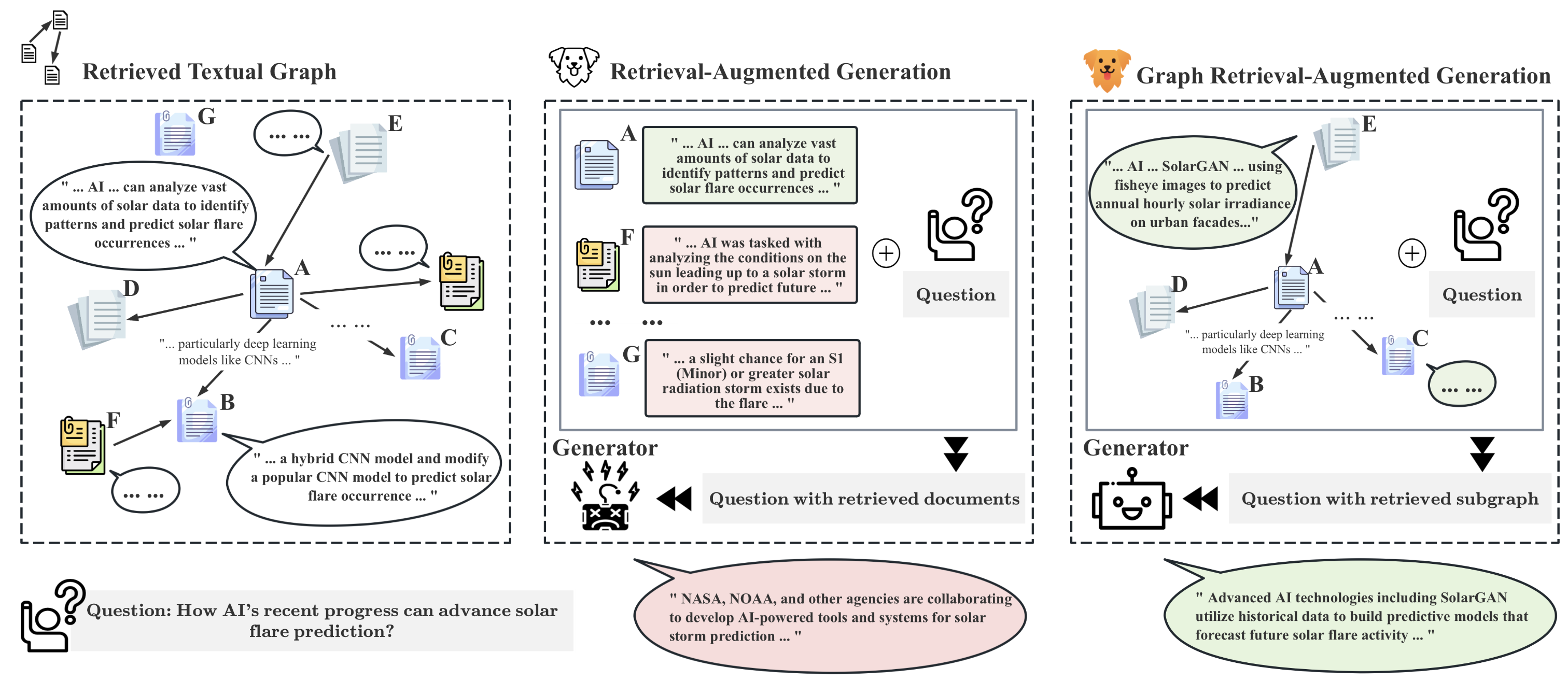
GRAG: Graph Retrieval-Augmented Generation
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, Liang Zhao
While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.
Read more5/28/2024

0
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
Bhaskarjit Sarmah, Benika Hall, Rohan Rao, Sunil Patel, Stefano Pasquali, Dhagash Mehta
Extraction and interpretation of intricate information from unstructured text data arising in financial applications, such as earnings call transcripts, present substantial challenges to large language models (LLMs) even using the current best practices to use Retrieval Augmented Generation (RAG) (referred to as VectorRAG techniques which utilize vector databases for information retrieval) due to challenges such as domain specific terminology and complex formats of the documents. We introduce a novel approach based on a combination, called HybridRAG, of the Knowledge Graphs (KGs) based RAG techniques (called GraphRAG) and VectorRAG techniques to enhance question-answer (Q&A) systems for information extraction from financial documents that is shown to be capable of generating accurate and contextually relevant answers. Using experiments on a set of financial earning call transcripts documents which come in the form of Q&A format, and hence provide a natural set of pairs of ground-truth Q&As, we show that HybridRAG which retrieves context from both vector database and KG outperforms both traditional VectorRAG and GraphRAG individually when evaluated at both the retrieval and generation stages in terms of retrieval accuracy and answer generation. The proposed technique has applications beyond the financial domain
Read more8/12/2024