From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
2308.12032
0
0
🚀
Abstract
In the realm of Large Language Models (LLMs), the balance between instruction data quality and quantity is a focal point. Recognizing this, we introduce a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, effectively minimizing manual curation and potential cost for instruction tuning an LLM. Our key innovation, the Instruction-Following Difficulty (IFD) metric, emerges as a pivotal metric to identify discrepancies between a model's expected responses and its intrinsic generation capability. Through the application of IFD, cherry samples can be pinpointed, leading to a marked uptick in model training efficiency. Empirical validations on datasets like Alpaca and WizardLM underpin our findings; with a mere $10%$ of original data input, our strategy showcases improved results. This synthesis of self-guided cherry-picking and the IFD metric signifies a transformative leap in the instruction tuning of LLMs, promising both efficiency and resource-conscious advancements. Codes, data, and models are available: https://github.com/tianyi-lab/Cherry_LLM
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores a self-guided methodology for Large Language Models (LLMs) to autonomously identify and select high-quality instruction data samples, reducing manual curation costs
- Introduces the Instruction-Following Difficulty (IFD) metric to identify discrepancies between a model's expected responses and its generation capabilities
- Demonstrates improved training efficiency on datasets like Alpaca and WizardLM using only 10% of the original data
Plain English Explanation
This research paper tackles a crucial challenge in training large language models (LLMs) - finding the right balance between the quantity and quality of instruction data used for tuning. The researchers recognized that manually curating high-quality instruction data can be time-consuming and costly. To address this, they developed a self-guided methodology that allows LLMs to autonomously identify and select the most useful data samples, minimizing the need for manual curation.
The key innovation in this work is the Instruction-Following Difficulty (IFD) metric. This metric helps the model identify discrepancies between its expected responses and its actual generation capabilities. By applying the IFD metric, the model can pinpoint the most valuable "cherry" samples from the available datasets, leading to more efficient training.
The researchers validated their approach by testing it on datasets like Alpaca and WizardLM. Remarkably, they were able to achieve improved results using only 10% of the original data, demonstrating the power of their self-guided cherry-picking strategy.
This work represents a significant advancement in the field of instruction tuning for LLMs, promising both efficiency gains and more judicious use of computational resources. The combination of self-guided data selection and the IFD metric could pave the way for more streamlined and effective model training processes.
Technical Explanation
The researchers propose a self-guided methodology for Large Language Models (LLMs) to autonomously identify and select high-quality instruction data samples from open-source datasets. This approach aims to minimize the need for manual curation, which can be time-consuming and costly.
At the heart of their innovation is the Instruction-Following Difficulty (IFD) metric. This metric serves as a pivotal tool for the LLM to discern discrepancies between its expected responses and its intrinsic generation capabilities. By applying the IFD metric, the model can effectively pinpoint the most valuable "cherry" samples from the available datasets, leading to a marked improvement in training efficiency.
The researchers evaluated their methodology on datasets such as Alpaca and WizardLM. Their findings demonstrate that by using only 10% of the original data, they were able to achieve improved results compared to the full dataset. This highlights the power of their self-guided cherry-picking strategy, which enables more efficient and resource-conscious instruction tuning for LLMs.
Critical Analysis
The researchers' approach presents several promising avenues for further research and refinement. While the Instruction-Following Difficulty (IFD) metric shows promise in identifying valuable instruction data samples, it would be valuable to explore how the metric's performance can be further optimized. Additionally, investigating the generalizability of this approach across a broader range of datasets and LLM architectures could provide valuable insights.
Another area worthy of exploration is the potential impact of this self-guided methodology on the diversity and representativeness of the selected instruction data. Ensuring that the cherry-picked samples maintain a balanced and inclusive representation of perspectives and experiences would be crucial to avoid biases or limitations in the trained models.
Furthermore, the researchers could delve deeper into the cognitive and behavioral implications of allowing LLMs to autonomously curate their own instruction data. Understanding how this self-guided approach affects the models' learning trajectories, knowledge acquisition, and decision-making processes could yield important insights for the field of artificial intelligence.
Conclusion
This research paper introduces a novel self-guided methodology for Large Language Models (LLMs) to autonomously identify and select high-quality instruction data samples, reducing the need for manual curation and the associated costs. The key innovation, the Instruction-Following Difficulty (IFD) metric, empowers LLMs to discern discrepancies between their expected responses and their generation capabilities, enabling them to pinpoint the most valuable "cherry" samples.
The empirical validations on datasets like Alpaca and WizardLM demonstrate the effectiveness of this approach, with significant improvements in training efficiency using only 10% of the original data.
This research represents a transformative leap in the instruction tuning of LLMs, promising both efficiency gains and more judicious use of computational resources. The self-guided cherry-picking strategy coupled with the IFD metric could pave the way for more streamlined and effective model training processes, ultimately driving advancements in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, Dongyeop Kang
0
0
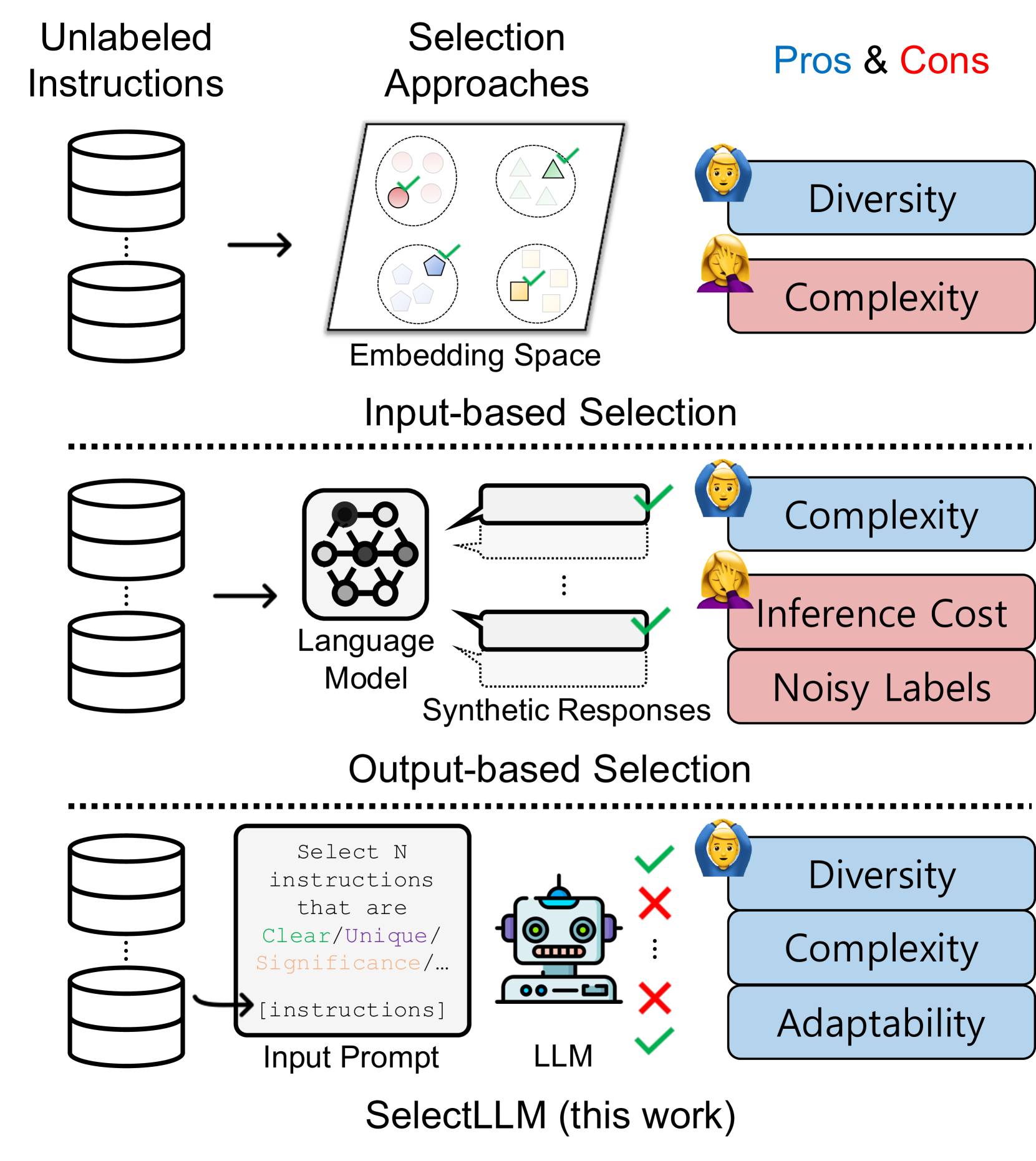
Instruction tuning benefits from large and diverse datasets, however creating such datasets involves a high cost of human labeling. While synthetic datasets generated by large language models (LLMs) have partly solved this issue, they often contain low-quality data. One effective solution is selectively annotating unlabelled instructions, especially given the relative ease of acquiring unlabeled instructions or texts from various sources. However, how to select unlabelled instructions is not well-explored, especially in the context of LLMs. Further, traditional data selection methods, relying on input embedding space density, tend to underestimate instruction sample complexity, whereas those based on model prediction uncertainty often struggle with synthetic label quality. Therefore, we introduce SelectLLM, an alternative framework that leverages the capabilities of LLMs to more effectively select unlabeled instructions. SelectLLM consists of two key steps: Coreset-based clustering of unlabelled instructions for diversity and then prompting a LLM to identify the most beneficial instructions within each cluster. Our experiments demonstrate that SelectLLM matches or outperforms other state-of-the-art methods in instruction tuning benchmarks. It exhibits remarkable consistency across human and synthetic datasets, along with better cross-dataset generalization, as evidenced by a 10% performance improvement on the Cleaned Alpaca test set when trained on Dolly data. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
4/19/2024
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
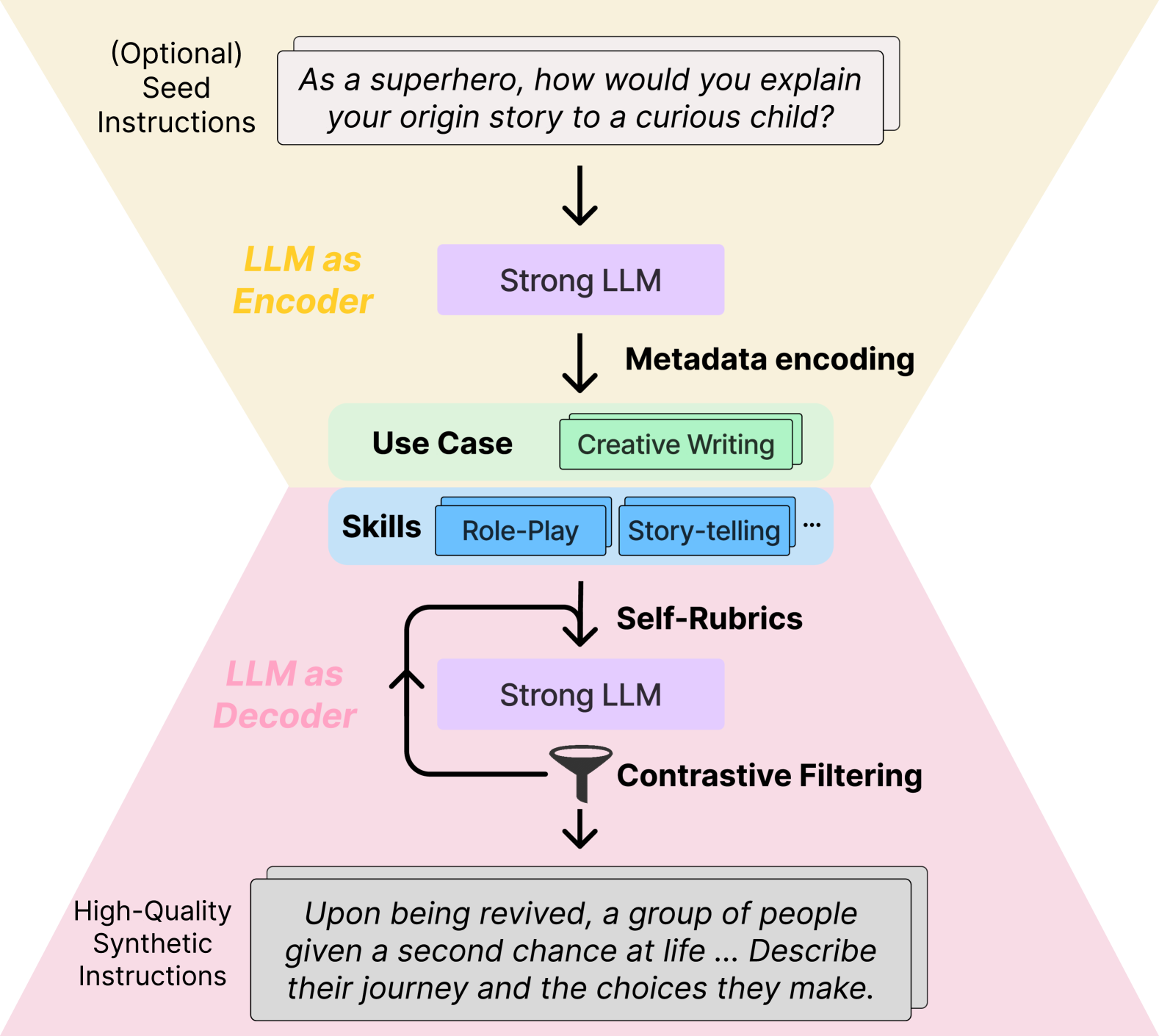
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
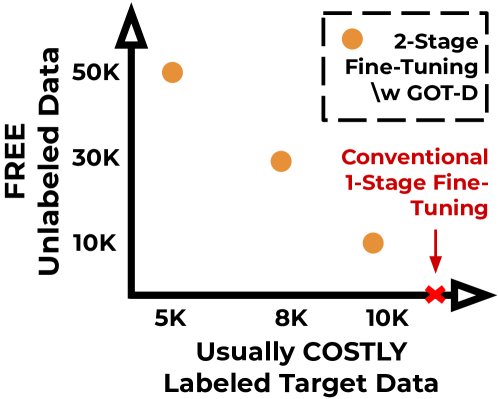
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024
What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, Junxian He
0
0
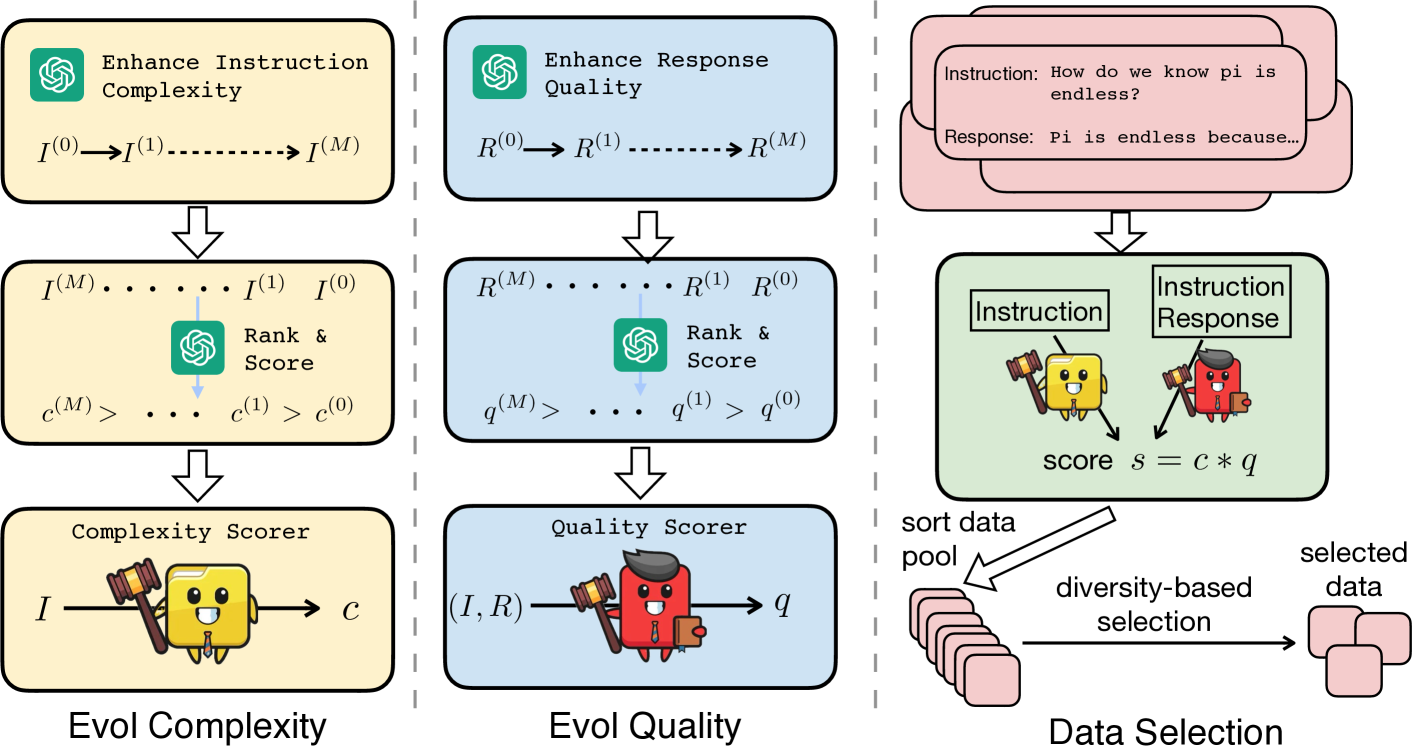
Instruction tuning is a standard technique employed to align large language models to end tasks and user preferences after the initial pretraining phase. Recent research indicates the critical role of data engineering in instruction tuning -- when appropriately selected, only limited data is necessary to achieve superior performance. However, we still lack a principled understanding of what makes good instruction tuning data for alignment, and how we should select data automatically and effectively. In this work, we delve deeply into automatic data selection strategies for alignment. We start with controlled studies to measure data across three dimensions: complexity, quality, and diversity, along which we examine existing methods and introduce novel techniques for enhanced data measurement. Subsequently, we propose a simple strategy to select data samples based on the measurement. We present deita (short for Data-Efficient Instruction Tuning for Alignment), a series of models fine-tuned from LLaMA and Mistral models using data samples automatically selected with our proposed approach. Empirically, deita performs better or on par with the state-of-the-art open-source alignment models with only 6K SFT training data samples -- over 10x less than the data used in the baselines. When further trained with direct preference optimization (DPO), deita-Mistral-7B + DPO trained with 6K SFT and 10K DPO samples achieve 7.55 MT-Bench and 90.06% AlpacaEval scores. We anticipate this work to provide tools on automatic data selection, facilitating data-efficient alignment. We release our models as well as the selected datasets for future researches to effectively align models more efficiently.
4/17/2024