From Sora What We Can See: A Survey of Text-to-Video Generation

0

Sign in to get full access
Overview
- Discusses a survey of text-to-video generation models, exploring the latest advancements and challenges in this rapidly evolving field.
- Covers the background, technology, limitations, and future opportunities of text-to-video generation systems.
- Examines the comprehensiveness and capabilities of these models in simulating the real world.
- Provides an overview of the state of the art in text-to-3D content generation and the current challenges in the field.
- Explores the detection of hallucination and the general challenges in this area.
- Discusses the current state of generative AI visualization and the future directions for the field.
Plain English Explanation
This blog post summarizes the key findings from a research paper that explores the current state of text-to-video generation models. These models are designed to take text-based descriptions and generate corresponding video content. The paper provides an overview of the background and technology behind these models, as well as the limitations and future opportunities in this rapidly evolving field.
The research also examines the comprehensiveness of these models in simulating the real world, and how well they can translate text into accurate 3D content. The paper also discusses the challenges in detecting when these models are generating content that doesn't accurately reflect the input text, known as "hallucination."
Additionally, the blog post covers the current state of generative AI visualization, which is the process of creating visual representations of the inner workings and outputs of these complex models. The post explores the future directions for this field and the potential implications for both researchers and the general public.
Technical Explanation
The research paper provides a comprehensive survey of the latest advancements in text-to-video generation models. These models use deep learning techniques, such as diffusion transformer models, to translate text-based descriptions into corresponding video content.
The paper examines the background and core technology powering these models, as well as the current limitations and future opportunities for improvement. It also explores the comprehensiveness of these models in simulating the real world and how well they can translate text into accurate 3D content.
The researchers also investigate the challenge of detecting hallucination in these models, where the generated content does not accurately reflect the input text. Finally, the paper provides an overview of the current state of generative AI visualization and the future directions for this field.
Critical Analysis
The research paper provides a thorough and insightful survey of the current state of text-to-video generation models. However, the authors acknowledge several limitations and areas for further research. For example, they note that the complexity of these models can make it challenging to fully understand their inner workings and the factors that influence their outputs.
Additionally, the paper highlights the ongoing challenge of detecting hallucination in these models, where the generated content does not accurately reflect the input text. While the researchers have proposed approaches to address this issue, more work is needed to develop robust and reliable hallucination detection methods.
Another potential concern is the ethical implications of these text-to-video generation models, particularly in terms of the potential for misuse or the spread of disinformation. The paper does not delve deeply into these societal implications, which would be an important area for future research and discussion.
Conclusion
The research paper provides a comprehensive overview of the current state of text-to-video generation models, exploring the background, technology, limitations, and future opportunities in this rapidly evolving field. The findings highlight the significant progress made in this area, as well as the ongoing challenges that researchers and developers must address.
As these models continue to advance, it will be crucial to carefully consider the ethical implications and to develop robust mechanisms for ensuring the accuracy and reliability of the generated content. By continuing to push the boundaries of text-to-video generation, researchers can unlock new possibilities for creative expression, education, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Sora What We Can See: A Survey of Text-to-Video Generation
Rui Sun, Yumin Zhang, Tejal Shah, Jiahao Sun, Shuoying Zhang, Wenqi Li, Haoran Duan, Bo Wei, Rajiv Ranjan
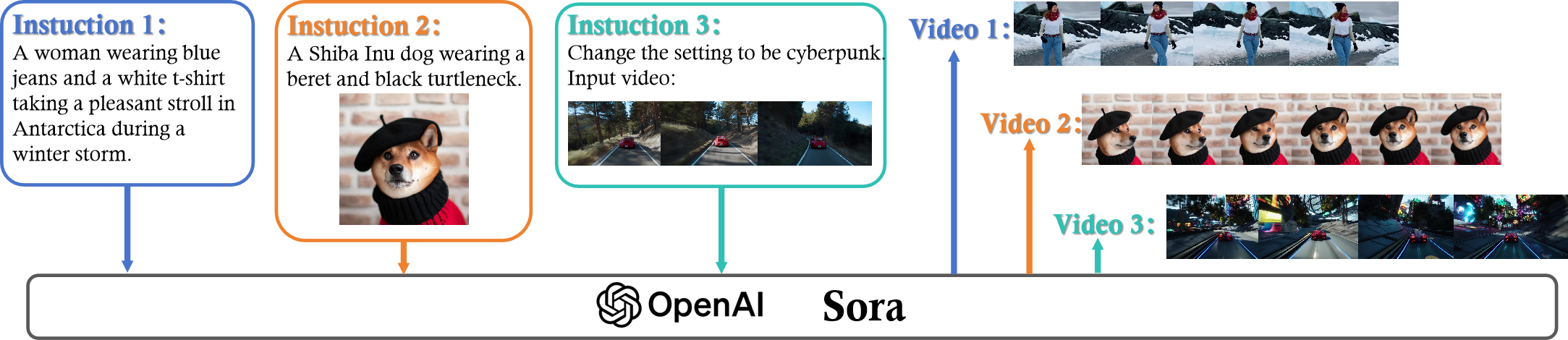
With impressive achievements made, artificial intelligence is on the path forward to artificial general intelligence. Sora, developed by OpenAI, which is capable of minute-level world-simulative abilities can be considered as a milestone on this developmental path. However, despite its notable successes, Sora still encounters various obstacles that need to be resolved. In this survey, we embark from the perspective of disassembling Sora in text-to-video generation, and conducting a comprehensive review of literature, trying to answer the question, textit{From Sora What We Can See}. Specifically, after basic preliminaries regarding the general algorithms are introduced, the literature is categorized from three mutually perpendicular dimensions: evolutionary generators, excellent pursuit, and realistic panorama. Subsequently, the widely used datasets and metrics are organized in detail. Last but more importantly, we identify several challenges and open problems in this domain and propose potential future directions for research and development.
Read more5/20/2024
🛸
0
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Joseph Cho, Fachrina Dewi Puspitasari, Sheng Zheng, Jingyao Zheng, Lik-Hang Lee, Tae-Ho Kim, Choong Seon Hong, Chaoning Zhang
The evolution of video generation from text, starting with animating MNIST numbers to simulating the physical world with Sora, has progressed at a breakneck speed over the past seven years. While often seen as a superficial expansion of the predecessor text-to-image generation model, text-to-video generation models are developed upon carefully engineered constituents. Here, we systematically discuss these elements consisting of but not limited to core building blocks (vision, language, and temporal) and supporting features from the perspective of their contributions to achieving a world model. We employ the PRISMA framework to curate 97 impactful research articles from renowned scientific databases primarily studying video synthesis using text conditions. Upon minute exploration of these manuscripts, we observe that text-to-video generation involves more intricate technologies beyond the plain extension of text-to-image generation. Our additional review into the shortcomings of Sora-generated videos pinpoints the call for more in-depth studies in various enabling aspects of video generation such as dataset, evaluation metric, efficient architecture, and human-controlled generation. Finally, we conclude that the study of the text-to-video generation may still be in its infancy, requiring contribution from the cross-discipline research community towards its advancement as the first step to realize artificial general intelligence (AGI).
Read more6/10/2024
23
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this world simulator. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
Read more4/19/2024
🤖
0
Sora is Incredible and Scary: Emerging Governance Challenges of Text-to-Video Generative AI Models
Kyrie Zhixuan Zhou, Abhinav Choudhry, Ece Gumusel, Madelyn Rose Sanfilippo
Text-to-video generative AI models such as Sora OpenAI have the potential to disrupt multiple industries. In this paper, we report a qualitative social media analysis aiming to uncover people's perceived impact of and concerns about Sora's integration. We collected and analyzed comments (N=292) under popular posts about Sora-generated videos, comparison between Sora videos and Midjourney images, and artists' complaints about copyright infringement by Generative AI. We found that people were most concerned about Sora's impact on content creation-related industries. Emerging governance challenges included the for-profit nature of OpenAI, the blurred boundaries between real and fake content, human autonomy, data privacy, copyright issues, and environmental impact. Potential regulatory solutions proposed by people included law-enforced labeling of AI content and AI literacy education for the public. Based on the findings, we discuss the importance of gauging people's tech perceptions early and propose policy recommendations to regulate Sora before its public release.
Read more6/19/2024