Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
2402.17177
33
1
Abstract
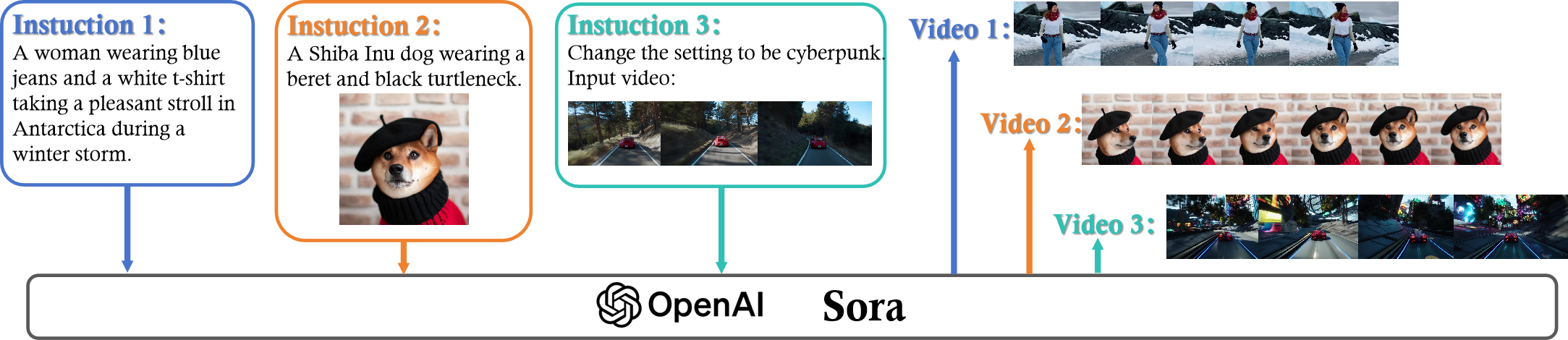
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this world simulator. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper provides a comprehensive review of large vision models, examining their background, technology, limitations, and opportunities.
- It explores the history and development of these models, the key architectural and training advances that have enabled their capabilities, the challenges and constraints they face, and the potential future directions for this rapidly evolving field.
Plain English Explanation
The paper discusses large vision models, which are a type of artificial intelligence that can process and understand visual information, such as images and videos. These models have become increasingly powerful and prevalent in recent years, with applications ranging from object recognition to image generation.
The paper traces the historical development of large vision models, starting from the early days of computer vision and the emergence of deep learning techniques. It then delves into the technical details of how these models work, explaining the key architectural innovations and training approaches that have enabled their impressive performance. This includes the use of transformer architectures and large-scale pretraining on vast datasets.
While large vision models have achieved remarkable results, the paper also discusses their limitations and challenges. These include the need for large and diverse training data, the difficulty of ensuring fairness and robustness, and the computational resources required to train and deploy these models. The paper also explores potential future directions, such as the integration of vision and language understanding, the development of more efficient and energy-efficient models, and the ethical considerations surrounding the deployment of these powerful AI systems.
Technical Explanation
The paper provides a comprehensive review of the background, technology, limitations, and opportunities of large vision models. It begins by tracing the historical development of this field, starting from the early days of computer vision and the emergence of deep learning techniques.
The paper then delves into the technical details of how large vision models work. It explains the key architectural innovations, such as the use of transformer architectures, that have enabled these models to achieve unprecedented levels of performance in a wide range of visual tasks. The paper also discusses the importance of large-scale pretraining on diverse datasets, which has been a critical factor in the success of these models.
While large vision models have achieved remarkable results, the paper also explores their limitations and challenges. These include the need for large and diverse training data, the difficulty of ensuring fairness and robustness, and the significant computational resources required to train and deploy these models. The paper also examines potential future directions, such as the integration of vision and language understanding, the development of more efficient and energy-efficient models, and the ethical considerations surrounding the deployment of these powerful AI systems.
Critical Analysis
The paper provides a balanced and comprehensive review of large vision models, acknowledging both their impressive capabilities and the challenges they face. One potential limitation of the research is that it does not delve deeply into the specific architectural details or training techniques used in these models, which may limit the technical depth for some readers.
Additionally, the paper could have explored the potential societal impacts of large vision models in more depth, particularly around issues of bias, privacy, and the displacement of human labor. While the paper touches on ethical considerations, a more thorough examination of these issues could have provided valuable insights for researchers and policymakers.
Nevertheless, the paper serves as a valuable resource for those interested in understanding the state of the art in large vision models, their potential future directions, and the critical considerations that must be addressed as this technology continues to evolve.
Conclusion
The paper provides a comprehensive review of large vision models, tracing their historical development, exploring their technical underpinnings, and examining their limitations and opportunities. The research highlights the remarkable progress that has been made in this field, driven by key architectural and training innovations, as well as the significant challenges that remain.
As large vision models become increasingly prevalent and influential, the insights and considerations raised in this paper will be crucial for researchers, developers, and policymakers to navigate the complex landscape of this rapidly evolving technology. The paper serves as a valuable resource for those seeking to understand the current state of the art and the future potential of large vision models.
Related Papers
🤷
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
0
0
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
5/7/2024
🔎
Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
Zhixuan Chu, Lei Zhang, Yichen Sun, Siqiao Xue, Zhibo Wang, Zhan Qin, Kui Ren
0
0
The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.
5/8/2024
🌿
Factors Influencing User Willingness To Use SORA
Gustave Florentin Nkoulou Mvondo, Ben Niu
0
0
Sora promises to redefine the way visual content is created. Despite its numerous forecasted benefits, the drivers of user willingness to use the text-to-video (T2V) model are unknown. This study extends the extended unified theory of acceptance and use of technology (UTAUT2) with perceived realism and novelty value. Using a purposive sampling method, we collected data from 940 respondents in the US and analyzed the sample using covariance-based structural equation modeling and fuzzy set qualitative comparative analysis (fsQCA). The findings reveal that all hypothesized relationships are supported, with perceived realism emerging as the most influential driver, followed by novelty value. Moreover, fsQCA identifies five configurations leading to high and low willingness to use, and the model demonstrates high predictive validity, contributing to theory advancement. Our study provides valuable insights for developers and marketers, offering guidance for strategic decisions to promote the widespread adoption of T2V models.
5/8/2024
🤖
From ChatGPT, DALL-E 3 to Sora: How has Generative AI Changed Digital Humanities Research and Services?
Jiangfeng Liu, Ziyi Wang, Jing Xie, Lei Pei
0
0
Generative large-scale language models create the fifth paradigm of scientific research, organically combine data science and computational intelligence, transform the research paradigm of natural language processing and multimodal information processing, promote the new trend of AI-enabled social science research, and provide new ideas for digital humanities research and application. This article profoundly explores the application of large-scale language models in digital humanities research, revealing their significant potential in ancient book protection, intelligent processing, and academic innovation. The article first outlines the importance of ancient book resources and the necessity of digital preservation, followed by a detailed introduction to developing large-scale language models, such as ChatGPT, and their applications in document management, content understanding, and cross-cultural research. Through specific cases, the article demonstrates how AI can assist in the organization, classification, and content generation of ancient books. Then, it explores the prospects of AI applications in artistic innovation and cultural heritage preservation. Finally, the article explores the challenges and opportunities in the interaction of technology, information, and society in the digital humanities triggered by AI technologies.
4/30/2024