Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation

0
🛸
Sign in to get full access
Overview
- The paper traces the rapid progress in text-to-video generation over the past seven years, from animating MNIST numbers to simulating the physical world with Sora.
- While often seen as a simple extension of text-to-image generation, text-to-video models are built upon carefully engineered components.
- The paper systematically discusses these key elements, including vision, language, and temporal processing, and how they contribute to achieving a "world model".
- The authors review 97 influential research papers on video synthesis using text conditions, and identify areas for further improvement, such as datasets, evaluation metrics, efficient architectures, and human-controlled generation.
- The study concludes that text-to-video generation is still in its infancy, requiring cross-disciplinary research to advance towards artificial general intelligence (AGI).
Plain English Explanation
The paper describes the remarkable progress made in generating videos from text over the past seven years. What used to start with simple animations of MNIST numbers has now evolved into more complex simulations of the physical world, like the Sora system.
While this may seem like a straightforward extension of the earlier text-to-image generation models, the researchers explain that the underlying technologies are much more intricate. The key components include vision, language, and temporal processing, all of which work together to create a "world model" that can generate realistic videos.
The authors conducted an in-depth review of 97 influential research papers in this field, using a systematic approach called PRISMA. They found that there are still many challenges to overcome, such as improving the datasets, evaluation metrics, architectural efficiency, and enabling more human control over the generation process.
Ultimately, the paper suggests that the study of text-to-video generation is still in its early stages. To make significant progress towards the goal of artificial general intelligence (AGI), the researchers call for a collaborative effort across various disciplines. This comprehensive survey highlights the need for more in-depth studies in this area.
Technical Explanation
The paper provides a systematic review of the key elements that underpin text-to-video generation models. These include the core building blocks of vision, language, and temporal processing, as well as supporting features that contribute to the creation of a "world model".
The authors employed the PRISMA framework to curate a set of 97 impactful research articles from renowned scientific databases. These papers primarily focused on video synthesis using text-based conditions. Through a detailed exploration of these manuscripts, the researchers found that text-to-video generation involves more complex technologies than simply extending text-to-image generation models.
The paper also delves into the limitations of the Sora system, a state-of-the-art text-to-video generation model. It identifies several areas that require further investigation, such as dataset quality, evaluation metrics, efficient architectures, and the need for more human control over the generation process.
Critical Analysis
The paper provides a comprehensive overview of the current state of text-to-video generation research, but it also acknowledges the significant challenges that remain. The authors rightly point out the need for more in-depth studies in various enabling aspects, such as dataset quality, evaluation metrics, and efficient architectures.
One potential limitation of the research is the reliance on the PRISMA framework, which may have excluded certain relevant papers that did not fit the inclusion criteria. Additionally, the paper does not delve deeply into the specific technical details of the various text-to-video generation models, which could be of interest to more technically-inclined readers.
The discussion on the limitations of the Sora system is particularly insightful, as it highlights the need for more robust and versatile text-to-video generation models that can better simulate the physical world. The authors' call for a cross-disciplinary effort to advance this field is well-justified, as it will likely require expertise from various domains, including computer vision, natural language processing, and physics simulation.
Overall, the paper provides a valuable contribution to the field of text-to-video generation, serving as a useful reference for researchers and practitioners alike. Its critical analysis and identification of future research directions can help guide the development of more sophisticated and capable text-to-video generation systems.
Conclusion
The paper presents a comprehensive overview of the rapid progress in text-to-video generation over the past seven years, from simple MNIST number animations to complex physical world simulations like Sora. While often seen as a straightforward extension of text-to-image generation, the authors demonstrate that text-to-video models involve more intricate and carefully engineered components, including vision, language, and temporal processing.
Through a systematic review of 97 influential research papers, the authors identify key areas that require further investigation, such as dataset quality, evaluation metrics, efficient architectures, and the need for more human control over the generation process. The paper concludes that the study of text-to-video generation is still in its infancy, and calls for a collaborative effort from the cross-discipline research community to drive its advancement towards the ultimate goal of artificial general intelligence (AGI).
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Joseph Cho, Fachrina Dewi Puspitasari, Sheng Zheng, Jingyao Zheng, Lik-Hang Lee, Tae-Ho Kim, Choong Seon Hong, Chaoning Zhang
The evolution of video generation from text, starting with animating MNIST numbers to simulating the physical world with Sora, has progressed at a breakneck speed over the past seven years. While often seen as a superficial expansion of the predecessor text-to-image generation model, text-to-video generation models are developed upon carefully engineered constituents. Here, we systematically discuss these elements consisting of but not limited to core building blocks (vision, language, and temporal) and supporting features from the perspective of their contributions to achieving a world model. We employ the PRISMA framework to curate 97 impactful research articles from renowned scientific databases primarily studying video synthesis using text conditions. Upon minute exploration of these manuscripts, we observe that text-to-video generation involves more intricate technologies beyond the plain extension of text-to-image generation. Our additional review into the shortcomings of Sora-generated videos pinpoints the call for more in-depth studies in various enabling aspects of video generation such as dataset, evaluation metric, efficient architecture, and human-controlled generation. Finally, we conclude that the study of the text-to-video generation may still be in its infancy, requiring contribution from the cross-discipline research community towards its advancement as the first step to realize artificial general intelligence (AGI).
Read more6/10/2024

0
From Sora What We Can See: A Survey of Text-to-Video Generation
Rui Sun, Yumin Zhang, Tejal Shah, Jiahao Sun, Shuoying Zhang, Wenqi Li, Haoran Duan, Bo Wei, Rajiv Ranjan
With impressive achievements made, artificial intelligence is on the path forward to artificial general intelligence. Sora, developed by OpenAI, which is capable of minute-level world-simulative abilities can be considered as a milestone on this developmental path. However, despite its notable successes, Sora still encounters various obstacles that need to be resolved. In this survey, we embark from the perspective of disassembling Sora in text-to-video generation, and conducting a comprehensive review of literature, trying to answer the question, textit{From Sora What We Can See}. Specifically, after basic preliminaries regarding the general algorithms are introduced, the literature is categorized from three mutually perpendicular dimensions: evolutionary generators, excellent pursuit, and realistic panorama. Subsequently, the widely used datasets and metrics are organized in detail. Last but more importantly, we identify several challenges and open problems in this domain and propose potential future directions for research and development.
Read more5/20/2024
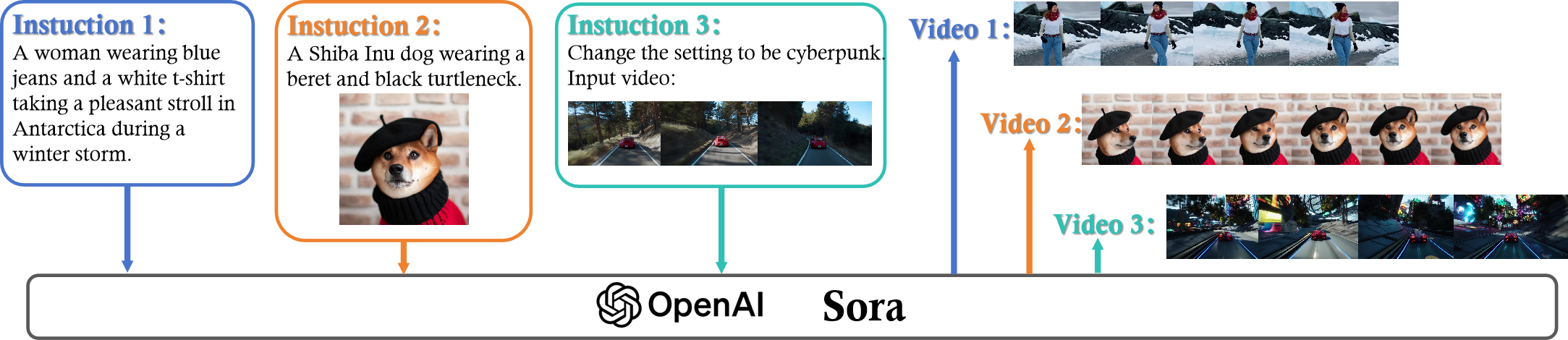
23
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this world simulator. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
Read more4/19/2024
🤷
0
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
Read more5/7/2024