Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
2405.04180
0
0

Abstract
The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents the Sora Detector, a unified system for detecting hallucinations in large text-to-video models.
- Hallucinations refer to the generation of content that is not grounded in the input, which is a critical issue for these models.
- The Sora Detector aims to provide a comprehensive solution for identifying and mitigating hallucinations across different domains.
Plain English Explanation
The Sora Detector is a tool designed to help detect and address a problem called "hallucination" in large language models that can generate text, images, and videos. Hallucination occurs when these models produce content that is not actually based on the original input, but rather something the model has made up on its own. This can be a significant issue, as it means the model's outputs may not be reliable or trustworthy.
The Sora Detector provides a unified approach to detecting hallucinations across different types of model outputs, such as text, images, and videos. By identifying when a model is hallucinating, the Sora Detector can help developers and users understand the limitations of these models and take steps to mitigate the problem. This is an important step in ensuring that large language models are used responsibly and in a way that benefits society.
Technical Explanation
The paper introduces the Sora Detector, a system designed to detect hallucinations in large text-to-video models. Hallucination refers to the generation of content that is not grounded in the input, which is a critical issue for these models.
The Sora Detector takes a unified approach, using a combination of techniques to identify hallucinations across different modalities, including text, images, and videos. This includes leveraging semantic reconstruction to compare the model's outputs to the input and detect discrepancies.
The paper also explores the use of diversity-aware active learning to improve the Sora Detector's performance, by selectively gathering additional training data to address specific types of hallucinations.
Critical Analysis
The Sora Detector represents a significant step forward in addressing the challenge of hallucinations in large text-to-video models. By providing a unified approach to detection, the system can help developers and users better understand the limitations of these models and take steps to mitigate the issue.
However, the paper does acknowledge that the Sora Detector has some limitations. For example, the system may struggle to detect more subtle or context-dependent hallucinations, and further research may be needed to refine the techniques used. Additionally, the paper does not explore the potential ethical implications of hallucination detection, such as how it might be used to monitor or censor model outputs.
Overall, the Sora Detector represents an important contribution to the field of large language model development and deployment. By providing a comprehensive approach to hallucination detection, the system can help ensure that these models are used responsibly and in a way that benefits society.
Conclusion
The Sora Detector is a powerful tool for detecting hallucinations in large text-to-video models. By taking a unified approach and leveraging a range of techniques, the system can help developers and users better understand the limitations of these models and take steps to mitigate the issue.
While the Sora Detector has some limitations, it represents a significant step forward in the ongoing effort to ensure that large language models are used responsibly and in a way that benefits society. As these models continue to grow in capabilities and influence, tools like the Sora Detector will be increasingly important for ensuring their safe and ethical deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
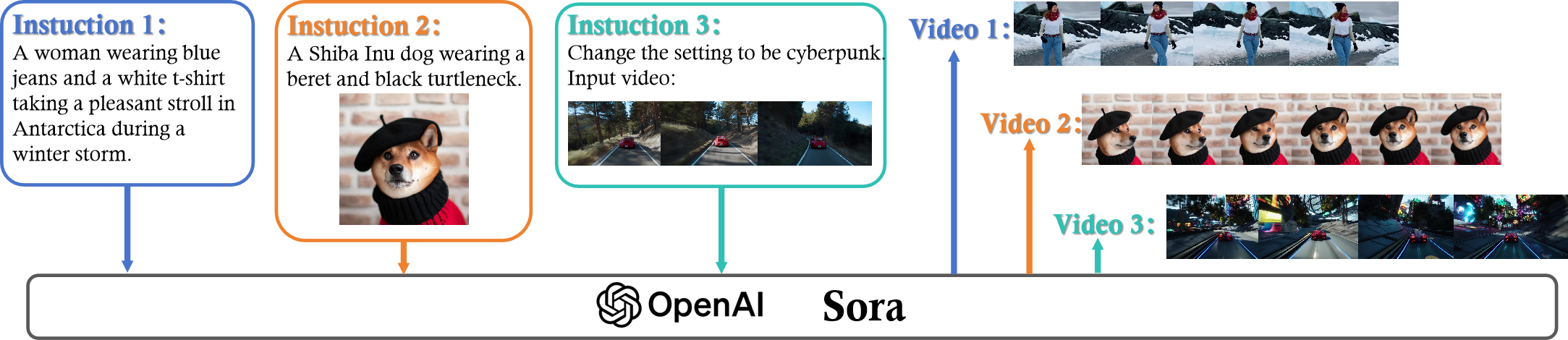
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
0
0
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this world simulator. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
4/19/2024

Unveiling Hallucination in Text, Image, Video, and Audio Foundation Models: A Comprehensive Review
Pranab Sahoo, Prabhash Meharia, Akash Ghosh, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The rapid advancement of foundation models (FMs) across language, image, audio, and video domains has shown remarkable capabilities in diverse tasks. However, the proliferation of FMs brings forth a critical challenge: the potential to generate hallucinated outputs, particularly in high-stakes applications. The tendency of foundation models to produce hallucinated content arguably represents the biggest hindrance to their widespread adoption in real-world scenarios, especially in domains where reliability and accuracy are paramount. This survey paper presents a comprehensive overview of recent developments that aim to identify and mitigate the problem of hallucination in FMs, spanning text, image, video, and audio modalities. By synthesizing recent advancements in detecting and mitigating hallucination across various modalities, the paper aims to provide valuable insights for researchers, developers, and practitioners. Essentially, it establishes a clear framework encompassing definition, taxonomy, and detection strategies for addressing hallucination in multimodal foundation models, laying the foundation for future research in this pivotal area.
5/17/2024
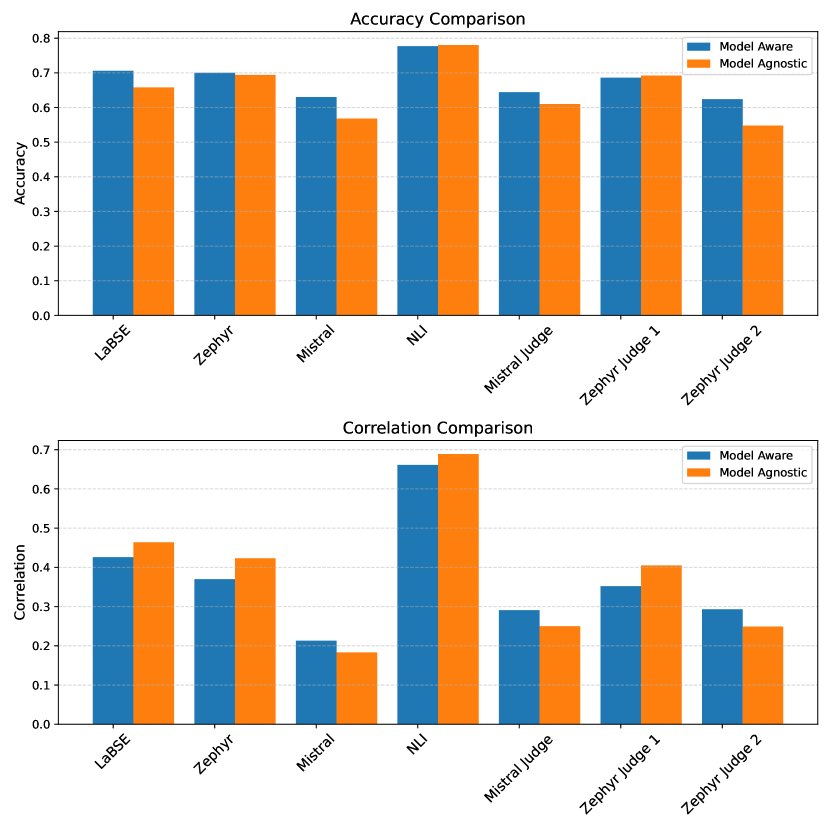
SLPL SHROOM at SemEval-2024 Task 06: A comprehensive study on models ability to detect hallucination
Pouya Fallah, Soroush Gooran, Mohammad Jafarinasab, Pouya Sadeghi, Reza Farnia, Amirreza Tarabkhah, Zainab Sadat Taghavi, Hossein Sameti
0
0
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
4/10/2024
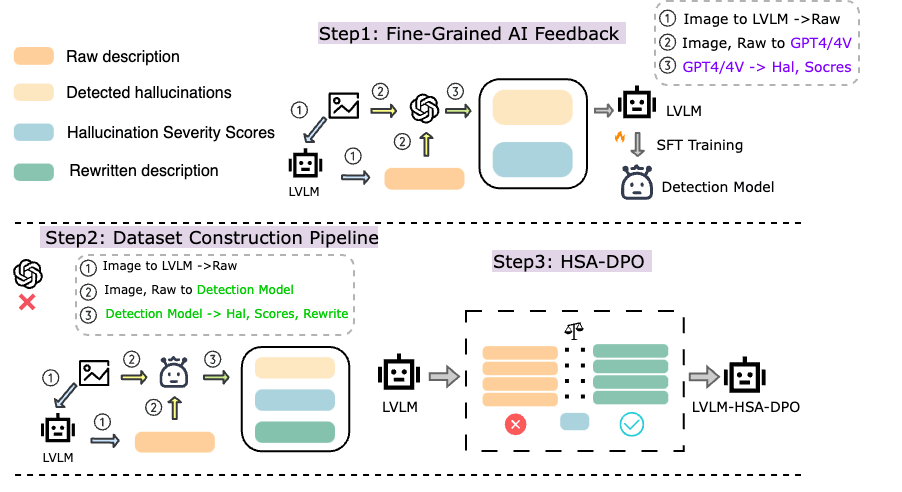
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024