High-resolution open-vocabulary object 6D pose estimation

0

Sign in to get full access
Overview
- This paper presents a novel approach for high-resolution open-vocabulary object 6D pose estimation, which is the task of determining the 3D orientation and position of objects in an image.
- The proposed method leverages recent advances in vision-language models (VLMs) to enable the recognition and pose estimation of a wide range of objects, going beyond typical closed-set object categories.
- The paper also introduces a new benchmark dataset and evaluation protocol to better assess the performance of open-vocabulary 6D pose estimation models.
Plain English Explanation
High-resolution open-vocabulary object 6D pose estimation is a computer vision task that aims to determine the 3D orientation and position of objects in an image, even if the specific object is not part of a predefined set. This is an important capability for applications like robotics, augmented reality, and autonomous vehicles, where systems need to understand the precise spatial information of the objects in their environment.
The key innovation in this paper is the use of vision-language models (VLMs), which are AI models that can understand the relationship between visual information and language. By incorporating these VLMs, the researchers were able to develop a system that can recognize and estimate the 6D pose of a wide range of objects, even ones that aren't part of a predefined set.
To evaluate their approach, the researchers created a new benchmark dataset and testing protocol, called OmniPose. This allows for a more comprehensive assessment of how well open-vocabulary 6D pose estimation models perform in real-world scenarios.
Technical Explanation
The proposed method starts by using a VLM to extract visual and semantic features from the input image. These features are then used to predict the 6D pose of the objects in the scene, even if they are not part of a predefined set of object categories.
The key components of the architecture include:
- VLM-based Feature Extraction: A pre-trained VLM, such as CLIP, is used to extract visual and semantic features from the input image.
- Pose Prediction Module: The visual and semantic features are fed into a neural network that predicts the 6D pose (3D orientation and 3D position) of the objects in the scene.
- Open-Vocabulary Capability: By leveraging the language understanding capabilities of the VLM, the system can recognize and estimate the pose of a wide range of objects, not just a limited set of predefined categories.
The researchers evaluated their approach on the OmniPose benchmark, which includes a diverse set of object categories and real-world scenes. The results demonstrate the effectiveness of the VLM-based approach for high-resolution open-vocabulary 6D pose estimation.
Critical Analysis
The paper makes a strong contribution to the field of object 6D pose estimation by addressing the limitation of closed-set object categories and enabling open-vocabulary recognition and pose estimation. The use of VLMs is a promising approach, as it allows the system to leverage the rich semantic understanding capabilities of these models.
However, the paper does not discuss the computational complexity and inference time of the proposed method, which could be an important consideration for real-time applications. Additionally, the paper could have explored the robustness of the system to occlusions, clutter, and other challenging real-world conditions.
Further research could investigate ways to improve the head pose estimation capabilities of the system or explore the use of few-shot learning techniques to enable efficient adaptation to new object categories. Additionally, the integration of 3D annotation pipelines could further enhance the system's ability to handle a wide range of object types and scenes.
Conclusion
This paper presents a novel approach for high-resolution open-vocabulary object 6D pose estimation that leverages the capabilities of vision-language models. The proposed method demonstrates the ability to recognize and estimate the pose of a wide range of objects, going beyond the limitations of closed-set object categories. The introduction of the OmniPose benchmark dataset and evaluation protocol also provides a valuable resource for further advancements in this important computer vision task. While the paper highlights the potential of this approach, future work could explore ways to improve its efficiency, robustness, and broader applicability to real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
High-resolution open-vocabulary object 6D pose estimation
Jaime Corsetti, Davide Boscaini, Francesco Giuliari, Changjae Oh, Andrea Cavallaro, Fabio Poiesi
The generalisation to unseen objects in the 6D pose estimation task is very challenging. While Vision-Language Models (VLMs) enable using natural language descriptions to support 6D pose estimation of unseen objects, these solutions underperform compared to model-based methods. In this work we present Horyon, an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. We use the textual prompt to identify the unseen object in the scenes and then obtain high-resolution multi-scale features. These features are used to extract cross-scene matches for registration. We evaluate our model on a benchmark with a large variety of unseen objects across four datasets, namely REAL275, Toyota-Light, Linemod, and YCB-Video. Our method achieves state-of-the-art performance on all datasets, outperforming by 12.6 in Average Recall the previous best-performing approach.
Read more7/12/2024
🚀
0
Open-vocabulary object 6D pose estimation
Jaime Corsetti, Davide Boscaini, Changjae Oh, Andrea Cavallaro, Fabio Poiesi
We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g., CAD or video sequence) is required at inference, and (iii) the object is imaged from two RGBD viewpoints of different scenes. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from the scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 34 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. Code and dataset are available at https://jcorsetti.github.io/oryon.
Read more4/8/2024
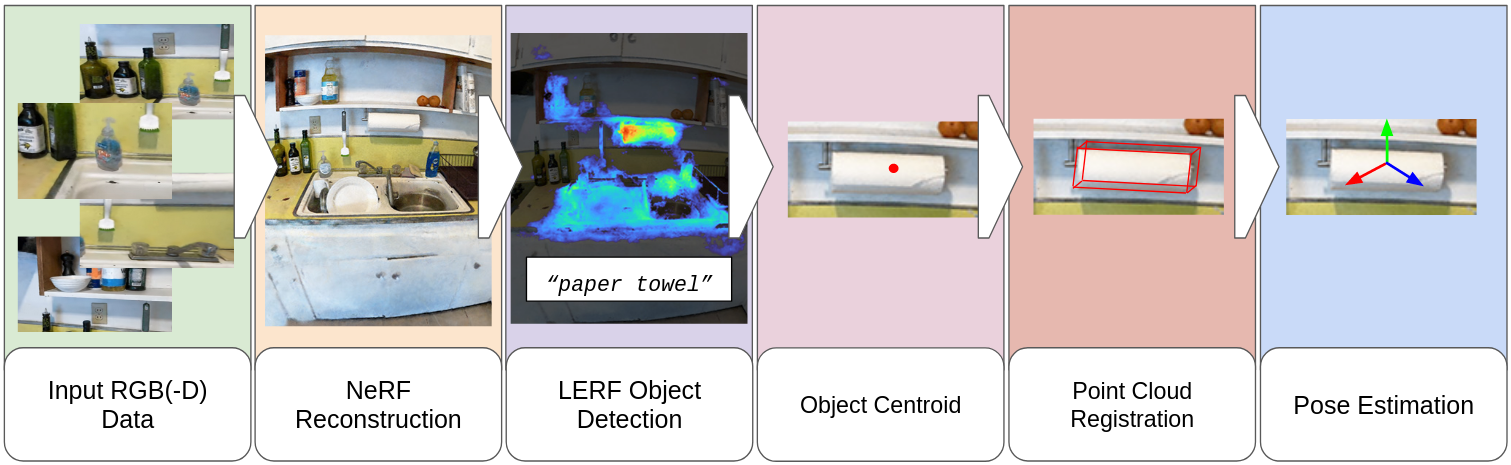
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024

0
BOP-D: Revisiting 6D Pose Estimation Benchmark for Better Evaluation under Visual Ambiguities
Boris Meden, Asma Brazi, Steve Bourgeois, Fabrice Mayran de Chamisso, Vincent Lepetit
Currently, 6D pose estimation methods are benchmarked on datasets that consider, for their ground truth annotations, visual ambiguities as only related to global object symmetries. However, as previously observed [26], visual ambiguities can also happen depending on the viewpoint or the presence of occluding objects, when disambiguating parts become hidden. The visual ambiguities are therefore actually different across images. We thus first propose an automatic method to re-annotate those datasets with a 6D pose distribution specific to each image, taking into account the visibility of the object surface in the image to correctly determine the visual ambiguities. Given this improved ground truth, we re-evaluate the state-of-the-art methods and show this greatly modify the ranking of these methods. Our annotations also allow us to benchmark recent methods able to estimate a pose distribution on real images for the first time. We will make our annotations for the T-LESS dataset and our code publicly available.
Read more9/2/2024