LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
2404.05961
5
58
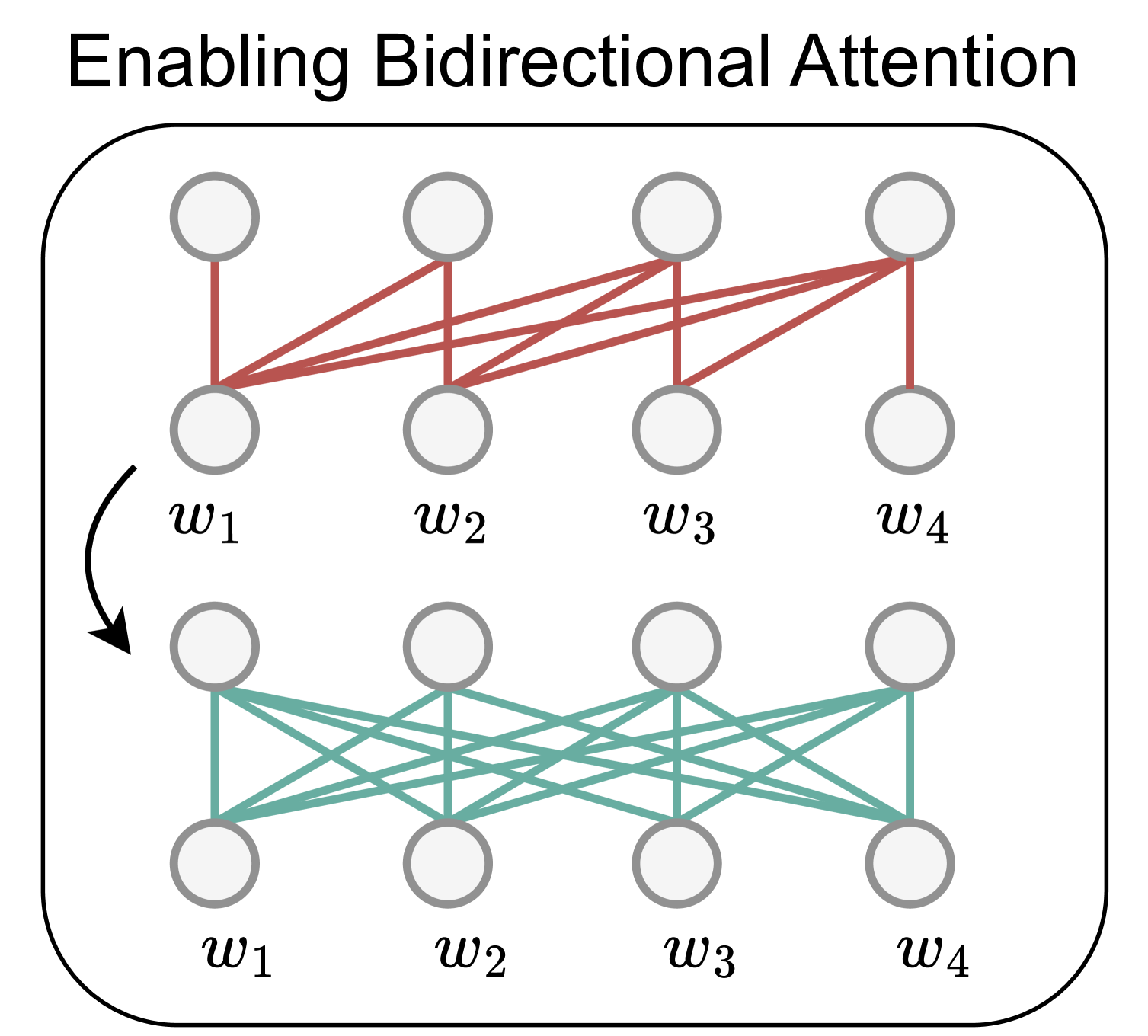
Abstract
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents LLM2Vec, a method for extracting powerful text encoding capabilities from large language models (LLMs) like GPT-3 and BERT.
- The researchers show that LLMs can be used as high-performance text encoders without any additional training, simply by leveraging their inherent representational power.
- LLM2Vec outperforms various specialized text encoding methods across a range of downstream tasks, demonstrating the untapped potential of LLMs as versatile text encoding tools.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT are trained on massive amounts of text data to learn the patterns and structure of language. These models have become incredibly powerful at tasks like generating human-like text, translating between languages, and answering questions.
However, the researchers behind this paper discovered that LLMs have another superpower - they can also act as highly effective text encoders. Text encoding is the process of converting text into a numerical representation that can be used by machine learning models for various tasks, like document retrieval or tabular data prediction.
The researchers developed a simple technique called LLM2Vec that allows you to extract these powerful text encoding capabilities from LLMs without any additional training. By just feeding text into an LLM and taking the hidden layer activations, you can get a high-performance text encoding that outperforms specialized text encoding methods on a variety of tasks.
This is an exciting discovery because it means we can leverage the incredible language understanding abilities of LLMs, which have been trained on vast amounts of data, to get state-of-the-art text encodings for free. This could be a game-changer for many natural language processing applications that rely on effective text encoding, like summarization, question answering, and document classification.
Technical Explanation
The key insight behind LLM2Vec is that the hidden layer activations of LLMs like GPT-3 and BERT already contain rich, high-dimensional representations of the input text. By simply extracting these activations and using them as text encodings, the researchers found that they could outperform specialized text encoding methods like word2vec and BERT embeddings on a range of downstream tasks.
To implement LLM2Vec, the researchers followed three simple steps:
- Select an LLM: They experimented with GPT-3 and BERT, but the technique should work with any large, pre-trained language model.
- Feed text into the LLM: For each input text, they pass it through the LLM and extract the hidden layer activations.
- Use the activations as the text encoding: The extracted activations serve as a high-dimensional numerical representation of the input text, which can then be used as features for downstream machine learning models.
The researchers evaluated LLM2Vec on a variety of text encoding benchmarks, including text classification, semantic similarity, and information retrieval tasks. They found that LLM2Vec outperformed specialized text encoding methods like word2vec and BERT embeddings, demonstrating the untapped potential of LLMs as powerful and versatile text encoding tools.
Critical Analysis
The LLM2Vec approach is a clever and simple way to leverage the impressive language understanding capabilities of large language models. By using the hidden layer activations as text encodings, the researchers have shown that LLMs can be repurposed as highly effective text encoders without any additional training.
One potential limitation of the study is that it primarily focuses on evaluating LLM2Vec on standard text encoding benchmarks. While this demonstrates the technique's strong performance on these tasks, it would be interesting to see how LLM2Vec fares on more real-world, domain-specific applications, such as retrieving relevant documents for a given query or predicting tabular data based on textual features.
Additionally, the researchers did not explore the potential limitations or failure modes of LLM2Vec. For example, it would be valuable to understand how the technique might perform on specialized, domain-specific text corpora, or on tasks that require more fine-grained semantic understanding beyond what the pre-trained LLMs may have learned.
Overall, the LLM2Vec approach is a promising development that could significantly impact a wide range of natural language processing applications by providing a high-performance text encoding method that leverages the power of large language models.
Conclusion
This paper presents a simple yet powerful technique called LLM2Vec that allows researchers and practitioners to extract versatile text encoding capabilities from large language models like GPT-3 and BERT. By using the hidden layer activations of these models as text encodings, LLM2Vec outperforms specialized text encoding methods on a variety of benchmarks, demonstrating the untapped potential of LLMs as powerful text encoding tools.
The LLM2Vec approach is an exciting development that could have far-reaching implications for natural language processing applications, from document retrieval to tabular data prediction and beyond. By leveraging the impressive language understanding abilities of LLMs, researchers can now access high-performance text encodings without the need for additional training, potentially unlocking new possibilities in text-based machine learning and other areas of natural language processing.
Related Papers

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024
🚀
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
0
0
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
4/19/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
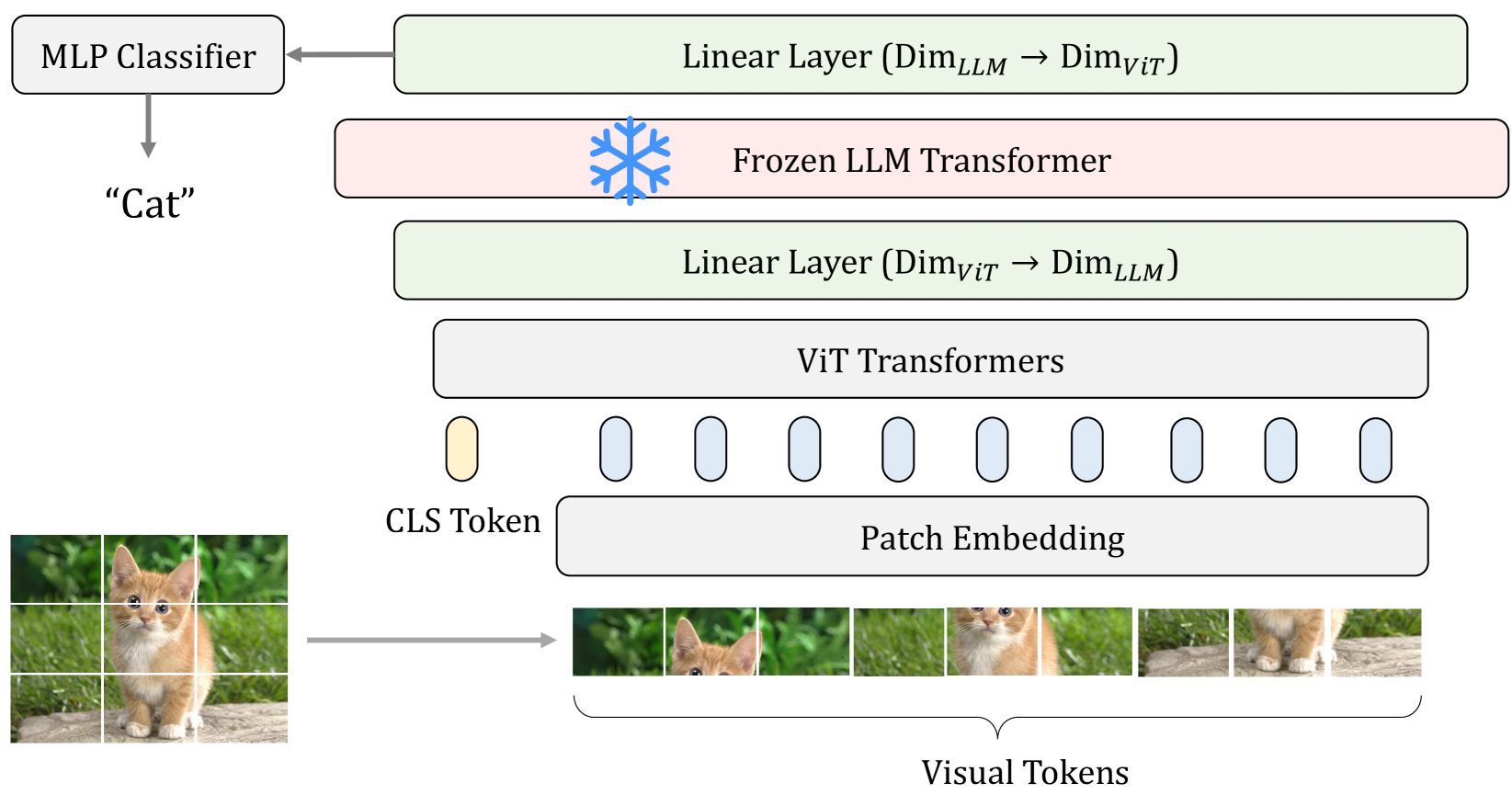
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Ziqi Pang, Ziyang Xie, Yunze Man, Yu-Xiong Wang
0
0
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
5/7/2024