Human Latency Conversational Turns for Spoken Avatar Systems
2404.16053
0
0
🤔
Abstract
A problem with many current Large Language Model (LLM) driven spoken dialogues is the response time. Some efforts such as Groq address this issue by lightning fast processing of the LLM, but we know from the cognitive psychology literature that in human-to-human dialogue often responses occur prior to the speaker completing their utterance. No amount of delay for LLM processing is acceptable if we wish to maintain human dialogue latencies. In this paper, we discuss methods for understanding an utterance in close to real time and generating a response so that the system can comply with human-level conversational turn delays. This means that the information content of the final part of the speaker's utterance is lost to the LLM. Using the Google NaturalQuestions (NQ) database, our results show GPT-4 can effectively fill in missing context from a dropped word at the end of a question over 60% of the time. We also provide some examples of utterances and the impacts of this information loss on the quality of LLM response in the context of an avatar that is currently under development. These results indicate that a simple classifier could be used to determine whether a question is semantically complete, or requires a filler phrase to allow a response to be generated within human dialogue time constraints.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Current large language models (LLMs) used in spoken dialogues often have slow response times, which can negatively impact the conversational experience.
- The paper explores methods to understand utterances in near real-time and generate responses quickly, in order to maintain human-like dialogue latencies.
- The key challenge is that by processing the utterance quickly, the LLM may lose information from the final part of the speaker's statement.
Plain English Explanation
When people have a conversation, they typically respond to each other quickly, often before the other person has finished speaking. This is an important part of natural human dialogue. However, many current conversational AI systems based on large language models (LLMs) struggle to keep up with this pace.
The reason is that LLMs need time to process the full statement before generating a response. If the system tries to respond too quickly, it may miss important information from the end of the speaker's utterance. This can lead to less natural and coherent conversations, which is a problem for applications like voice-based user interfaces.
This research paper explores ways to have the LLM understand the key meaning of the utterance quickly, even if it misses the final details. The authors show that in many cases, the LLM can effectively "fill in the blanks" and generate a suitable response within the time constraints of human dialogue.
For example, if someone asks "What is the capital of [missing word]?", the LLM may be able to infer that the missing word is likely a country and provide an appropriate answer, even though it didn't hear the full question.
This suggests that a simple classifier could be used to detect when an utterance is semantically complete versus requiring additional context. This could allow conversational AI systems to respond more naturally and quickly, while still leveraging the power of large language models.
Technical Explanation
The key challenge addressed in this paper is the response time limitation of current LLM-based spoken dialogue systems. The authors note that in human-to-human conversation, responses often occur before the speaker has fully completed their utterance. However, LLMs require processing the full input before generating a response, which can introduce unacceptable delays.
To address this, the researchers investigate methods for understanding an utterance in close to real-time and generating a response quickly enough to maintain human-level conversational turn delays. This means the LLM may not have access to the full information content, as the final part of the speaker's utterance could be lost.
Using the Google NaturalQuestions (NQ) dataset, the authors show that GPT-4 can effectively "fill in" missing context from a dropped word at the end of a question over 60% of the time. This suggests that a simple classifier could be used to determine whether a question is semantically complete or requires additional context in order to generate a timely response.
The paper also provides examples of how this information loss can impact the quality of the LLM's response, in the context of an avatar system currently under development. These results indicate that balancing speed and information completeness is a key challenge in building natural conversational AI systems that can match human-like dialogue latencies.
Critical Analysis
The research presented in this paper offers a promising approach to addressing the response time limitations of current LLM-driven spoken dialogues. By exploring methods to understand utterances quickly and generate responses within human-level conversational turn delays, the authors are tackling an important usability challenge for conversational AI systems.
However, the paper does acknowledge the potential tradeoffs and limitations of this approach. Losing information from the final part of the speaker's utterance could negatively impact the quality and coherence of the system's responses in some cases. Further research would be needed to fully understand the impact on the user experience and develop robust techniques to mitigate these issues.
Additionally, the experiments were conducted using a specific dataset and model (GPT-4), so the generalizability of the findings to other LLMs and conversational domains remains to be explored. Evaluating the proposed approaches in more diverse, real-world settings would help validate their effectiveness and identify any additional challenges or edge cases.
Overall, this paper presents an interesting and pragmatic approach to balancing response time and information completeness in LLM-driven spoken dialogues. While more research is needed, the findings suggest that a combination of rapid utterance understanding and intelligent context-filling could help bring conversational AI systems closer to human-like interaction speeds and naturalness.
Conclusion
This research paper addresses a key challenge in current large language model (LLM) driven spoken dialogues: the response time. The authors explore methods to understand utterances in close to real-time and generate responses quickly, in order to maintain human-like conversational turn delays.
The core insight is that by processing the utterance rapidly, the LLM may lose information from the final part of the speaker's statement. However, the paper demonstrates that in many cases, the LLM can effectively "fill in the blanks" and provide a suitable response, even without the complete information.
These findings suggest that a simple classifier could be used to detect when an utterance is semantically complete versus requiring additional context. This could allow conversational AI systems to respond more naturally and quickly, while still leveraging the power of large language models.
While more research is needed to fully understand the tradeoffs and limitations of this approach, this paper offers a promising direction for improving the usability and performance of LLM-driven spoken dialogues, with potential applications in voice-based user interfaces and other conversational AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
0
0
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
4/1/2024
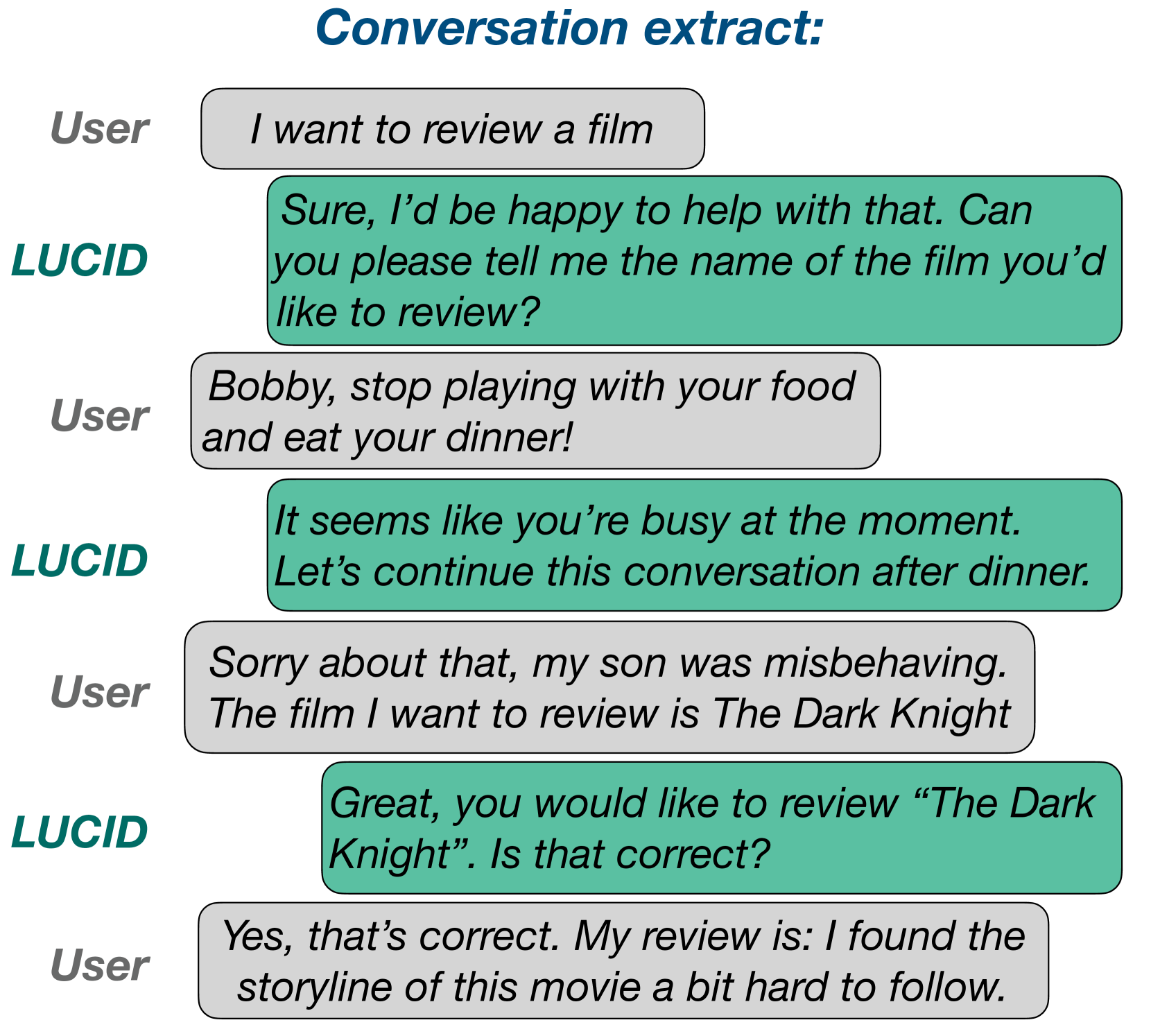
LUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Joe Stacey, Jianpeng Cheng, John Torr, Tristan Guigue, Joris Driesen, Alexandru Coca, Mark Gaynor, Anders Johannsen
0
0
Spurred by recent advances in Large Language Models (LLMs), virtual assistants are poised to take a leap forward in terms of their dialogue capabilities. Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 conversations across 100 intents to demonstrate its capabilities, with a human review finding consistently high quality labels in the generated data.
5/6/2024
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
0
0
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
4/29/2024

Large Language User Interfaces: Voice Interactive User Interfaces powered by LLMs
Syed Mekael Wasti, Ken Q. Pu, Ali Neshati
0
0
The evolution of Large Language Models (LLMs) has showcased remarkable capacities for logical reasoning and natural language comprehension. These capabilities can be leveraged in solutions that semantically and textually model complex problems. In this paper, we present our efforts toward constructing a framework that can serve as an intermediary between a user and their user interface (UI), enabling dynamic and real-time interactions. We employ a system that stands upon textual semantic mappings of UI components, in the form of annotations. These mappings are stored, parsed, and scaled in a custom data structure, supplementary to an agent-based prompting backend engine. Employing textual semantic mappings allows each component to not only explain its role to the engine but also provide expectations. By comprehending the needs of both the user and the components, our LLM engine can classify the most appropriate application, extract relevant parameters, and subsequently execute precise predictions of the user's expected actions. Such an integration evolves static user interfaces into highly dynamic and adaptable solutions, introducing a new frontier of intelligent and responsive user experiences.
4/17/2024