Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation

0
Sign in to get full access
Overview
- Presents a novel framework called "Fuse & Calibrate" for referring image segmentation, a task that involves identifying and segmenting an object in an image based on a textual description.
- The framework leverages both vision and language models in a bi-directional manner to improve performance on this challenging task.
- Introduces several key innovations, including a fusion module to effectively combine visual and textual representations, and a calibration module to refine the segmentation results.
Plain English Explanation
The paper describes a new approach for referring image segmentation, which is the task of identifying and outlining a specific object in an image based on a textual description of that object. This is a challenging problem that requires understanding both the visual information in the image and the semantic content of the text.
The proposed "Fuse & Calibrate" framework tackles this problem by using both computer vision and natural language processing models in a two-way interaction. First, it fuses the visual and textual representations to create a combined understanding of the target object. Then, it calibrates the segmentation result, refining the final output to better match the textual description.
The key innovations include a fusion module that effectively combines the visual and language information, and a calibration module that iteratively adjusts the segmentation to improve its alignment with the text. This bi-directional approach allows the framework to leverage the strengths of both modalities to achieve better performance on referring image segmentation tasks.
Technical Explanation
The Fuse & Calibrate framework consists of three main components:
-
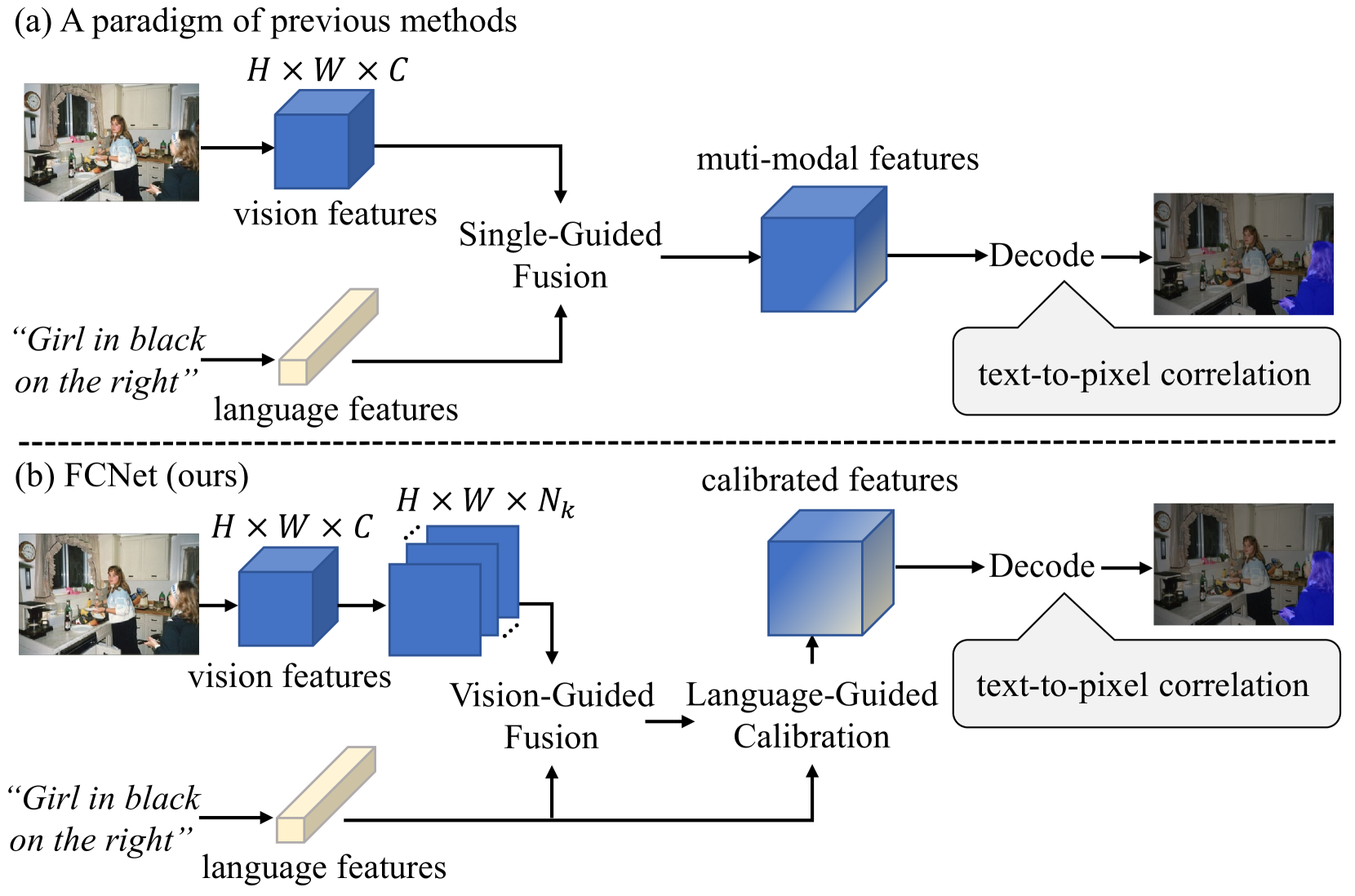
Vision-Language Fusion Module: This module takes the visual features extracted from the image and the textual features from the referring expression, and combines them into a unified representation. It uses attention mechanisms to dynamically weight the importance of different visual and textual elements, allowing the model to focus on the most relevant information for the task.
-
Segmentation Module: This is a convolutional neural network that generates a segmentation mask based on the fused vision-language representation. It is trained to output a pixel-level prediction of the target object's location and extent.
-
Calibration Module: This component iteratively refines the segmentation mask to better align with the textual description. It uses a bilateral attention mechanism to update the segmentation based on both visual and language cues, further improving the referring image segmentation performance.
The authors evaluate their framework on several benchmark datasets for referring image segmentation, including RefCOCO, RefCOCO+, and RefCOCOg. The results demonstrate that the "Fuse & Calibrate" approach outperforms previous state-of-the-art methods, highlighting the benefits of the bi-directional vision-language interaction.
Critical Analysis
The paper presents a well-designed and thorough approach to the challenging task of referring image segmentation. The authors have identified key limitations in existing methods and addressed them through the novel "Fuse & Calibrate" framework. The fusion and calibration modules in particular seem to be effective at leveraging both visual and textual information to improve segmentation accuracy.
However, the paper does not extensively discuss the computational cost or runtime efficiency of the proposed framework. As referring image segmentation is often required in real-time applications, the model's inference speed could be an important practical consideration. Additionally, the authors acknowledge that their approach may struggle with highly complex scenes or ambiguous referring expressions, which suggests there is still room for improvement in this domain.
Further research could explore ways to make the framework more robust to these challenging cases, perhaps by incorporating additional contextual cues or developing more sophisticated reasoning mechanisms. Exploring the generalization of the approach to other vision-language tasks could also be a fruitful direction for future work.
Conclusion
The "Fuse & Calibrate" framework represents a significant advancement in the field of referring image segmentation. By seamlessly combining visual and language models in a bi-directional manner, the authors have demonstrated how to effectively leverage multimodal information to achieve state-of-the-art performance on this task.
The innovations in fusion and calibration modules, as well as the strong empirical results, suggest that this framework could have a substantial impact on applications that require understanding the semantic relationship between images and text, such as image captioning, visual question answering, and image-based retrieval. As the field of vision-language AI continues to evolve, the "Fuse & Calibrate" approach provides a promising direction for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Shichen Lu, Jing Liu
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
Read more5/21/2024
0
Cross-aware Early Fusion with Stage-divided Vision and Language Transformer Encoders for Referring Image Segmentation
Yubin Cho, Hyunwoo Yu, Suk-ju Kang
Referring segmentation aims to segment a target object related to a natural language expression. Key challenges of this task are understanding the meaning of complex and ambiguous language expressions and determining the relevant regions in the image with multiple objects by referring to the expression. Recent models have focused on the early fusion with the language features at the intermediate stage of the vision encoder, but these approaches have a limitation that the language features cannot refer to the visual information. To address this issue, this paper proposes a novel architecture, Cross-aware early fusion with stage-divided Vision and Language Transformer encoders (CrossVLT), which allows both language and vision encoders to perform the early fusion for improving the ability of the cross-modal context modeling. Unlike previous methods, our method enables the vision and language features to refer to each other's information at each stage to mutually enhance the robustness of both encoders. Furthermore, unlike the conventional scheme that relies solely on the high-level features for the cross-modal alignment, we introduce a feature-based alignment scheme that enables the low-level to high-level features of the vision and language encoders to engage in the cross-modal alignment. By aligning the intermediate cross-modal features in all encoder stages, this scheme leads to effective cross-modal fusion. In this way, the proposed approach is simple but effective for referring image segmentation, and it outperforms the previous state-of-the-art methods on three public benchmarks.
Read more8/15/2024

0
Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Jing Liu
Referring image segmentation aims to segment an object referred to by natural language expression from an image. The primary challenge lies in the efficient propagation of fine-grained semantic information from textual features to visual features. Many recent works utilize a Transformer to address this challenge. However, conventional transformer decoders can distort linguistic information with deeper layers, leading to suboptimal results. In this paper, we introduce CRFormer, a model that iteratively calibrates multi-modal features in the transformer decoder. We start by generating language queries using vision features, emphasizing different aspects of the input language. Then, we propose a novel Calibration Decoder (CDec) wherein the multi-modal features can iteratively calibrated by the input language features. In the Calibration Decoder, we use the output of each decoder layer and the original language features to generate new queries for continuous calibration, which gradually updates the language features. Based on CDec, we introduce a Language Reconstruction Module and a reconstruction loss. This module leverages queries from the final layer of the decoder to reconstruct the input language and compute the reconstruction loss. This can further prevent the language information from being lost or distorted. Our experiments consistently show the superior performance of our approach across RefCOCO, RefCOCO+, and G-Ref datasets compared to state-of-the-art methods.
Read more4/15/2024

0
A Semantic-Aware and Multi-Guided Network for Infrared-Visible Image Fusion
Xiaoli Zhang, Liying Wang, Libo Zhao, Xiongfei Li, Siwei Ma
Multi-modality image fusion aims at fusing specific-modality and shared-modality information from two source images. To tackle the problem of insufficient feature extraction and lack of semantic awareness for complex scenes, this paper focuses on how to model correlation-driven decomposing features and reason high-level graph representation by efficiently extracting complementary features and multi-guided feature aggregation. We propose a three-branch encoder-decoder architecture along with corresponding fusion layers as the fusion strategy. The transformer with Multi-Dconv Transposed Attention and Local-enhanced Feed Forward network is used to extract shallow features after the depthwise convolution. In the three parallel branches encoder, Cross Attention and Invertible Block (CAI) enables to extract local features and preserve high-frequency texture details. Base feature extraction module (BFE) with residual connections can capture long-range dependency and enhance shared-modality expression capabilities. Graph Reasoning Module (GR) is introduced to reason high-level cross-modality relations and extract low-level details features as CAI's specific-modality complementary information simultaneously. Experiments demonstrate that our method has obtained competitive results compared with state-of-the-art methods in visible/infrared image fusion and medical image fusion tasks. Moreover, we surpass other fusion methods in terms of subsequent tasks, averagely scoring 9.78% [email protected] higher in object detection and 6.46% mIoU higher in semantic segmentation.
Read more7/9/2024