Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel deep learning approach for referring image segmentation, which involves identifying and segmenting an object in an image based on a referring expression (a description of the object).
- The approach combines language reconstruction and iterative calibration to improve the performance of referring image segmentation.
- The authors conduct extensive experiments on multiple benchmark datasets and demonstrate the effectiveness of their method compared to state-of-the-art techniques.
Plain English Explanation
The paper presents a new deep learning model for a task called "referring image segmentation." In this task, the goal is to identify and outline a specific object in an image based on a textual description of that object, like "the red car in the center of the image."
The key innovation of this work is the use of two main techniques:
-
Language Reconstruction: The model is trained to not only segment the object, but also to reconstruct the original text description. This helps the model better understand the relationship between the image and the language.
-
Iterative Calibration: The model goes through multiple rounds of refinement, adjusting its understanding of the image and language based on feedback. This iterative process allows the model to gradually improve its segmentation performance.
The authors demonstrate that combining these techniques leads to state-of-the-art results on standard benchmarks for referring image segmentation. This suggests that integrating language understanding and iterative refinement can be a powerful approach for this task.
The paper provides a technical explanation of the model architecture and training process, as well as detailed results and comparisons to other methods. Overall, this work advances the field of referring image segmentation by introducing a novel deep learning approach that leverages both language reconstruction and iterative calibration.
Technical Explanation
The proposed method, called DILS (Deep Integrated Language for Segmentation), consists of two key components:
-
Language Reconstruction: The model is trained to not only segment the target object, but also to reconstruct the original referring expression. This cross-modal conditioning helps the model better align the visual and textual information, improving its ability to locate the correct object.
-
Iterative Calibration: The model goes through multiple rounds of refinement, where the language and visual representations are iteratively updated based on feedback from the previous iteration. This iterative calibration process allows the model to gradually improve its segmentation performance.
The DILS architecture consists of a vision encoder, a language encoder, and a segmentation decoder. The vision encoder processes the input image, and the language encoder processes the referring expression. The outputs of these two encoders are then combined and fed into the segmentation decoder, which produces the final object segmentation mask.
During training, the model is optimized for both the segmentation task and the language reconstruction task. The iterative calibration process involves updating the language and visual representations based on the segmentation output from the previous iteration.
The authors evaluate DILS on several benchmark datasets for referring image segmentation, including RefCOCO, RefCOCO+, and RefCOCOg. They show that DILS outperforms state-of-the-art methods, demonstrating the effectiveness of the unified multi-modal diagnostic framework that combines language reconstruction and iterative calibration.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed DILS method, including comparisons to a wide range of existing approaches. The authors acknowledge several limitations and potential areas for future work, such as improving the efficiency of the iterative calibration process and exploring extensions to other vision-language tasks.
One potential concern is the computational complexity of the iterative calibration process, which may limit the practical deployment of the method in real-world applications. The authors could have provided more discussion on strategies to address this, such as techniques to accelerate the calibration or ways to make the process more efficient.
Additionally, the paper could have delved deeper into the specific failure cases or edge cases where the DILS method struggles. Understanding the limitations and weaknesses of the approach would help guide future research in this area.
Overall, the paper makes a valuable contribution to the field of referring image segmentation by introducing a novel deep learning framework that integrates language reconstruction and iterative calibration. The strong empirical results demonstrate the potential of this approach, and the paper provides a solid foundation for further research and development in this area.
Conclusion
This paper presents a novel deep learning method called DILS (Deep Integrated Language for Segmentation) for the task of referring image segmentation. The key innovations are the use of language reconstruction and iterative calibration, which help the model better align the visual and textual information and gradually improve its segmentation performance.
The authors conduct extensive experiments on multiple benchmark datasets and show that DILS outperforms state-of-the-art techniques. This work advances the field of referring image segmentation by introducing a novel deep learning framework that integrates language reconstruction and iterative calibration, leading to improved performance on this challenging task.
The paper provides a strong technical foundation and opens up new research directions in the intersection of computer vision and natural language processing, with potential applications in areas such as cross-modal diagnostic frameworks and vision-aware language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Jing Liu
Referring image segmentation aims to segment an object referred to by natural language expression from an image. The primary challenge lies in the efficient propagation of fine-grained semantic information from textual features to visual features. Many recent works utilize a Transformer to address this challenge. However, conventional transformer decoders can distort linguistic information with deeper layers, leading to suboptimal results. In this paper, we introduce CRFormer, a model that iteratively calibrates multi-modal features in the transformer decoder. We start by generating language queries using vision features, emphasizing different aspects of the input language. Then, we propose a novel Calibration Decoder (CDec) wherein the multi-modal features can iteratively calibrated by the input language features. In the Calibration Decoder, we use the output of each decoder layer and the original language features to generate new queries for continuous calibration, which gradually updates the language features. Based on CDec, we introduce a Language Reconstruction Module and a reconstruction loss. This module leverages queries from the final layer of the decoder to reconstruct the input language and compute the reconstruction loss. This can further prevent the language information from being lost or distorted. Our experiments consistently show the superior performance of our approach across RefCOCO, RefCOCO+, and G-Ref datasets compared to state-of-the-art methods.
Read more4/15/2024
0
Fuse & Calibrate: A bi-directional Vision-Language Guided Framework for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Shichen Lu, Jing Liu
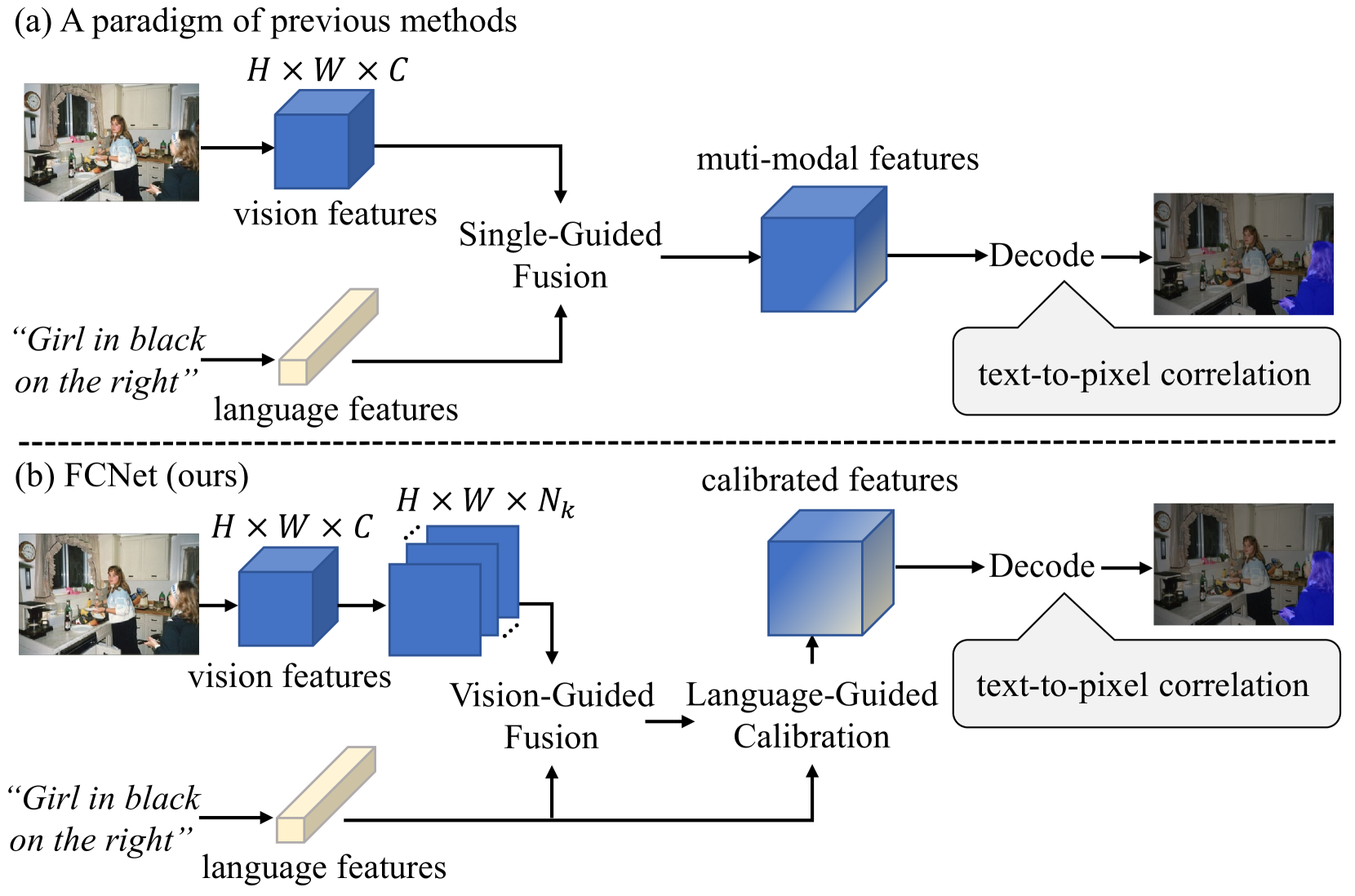
Referring Image Segmentation (RIS) aims to segment an object described in natural language from an image, with the main challenge being a text-to-pixel correlation. Previous methods typically rely on single-modality features, such as vision or language features, to guide the multi-modal fusion process. However, this approach limits the interaction between vision and language, leading to a lack of fine-grained correlation between the language description and pixel-level details during the decoding process. In this paper, we introduce FCNet, a framework that employs a bi-directional guided fusion approach where both vision and language play guiding roles. Specifically, we use a vision-guided approach to conduct initial multi-modal fusion, obtaining multi-modal features that focus on key vision information. We then propose a language-guided calibration module to further calibrate these multi-modal features, ensuring they understand the context of the input sentence. This bi-directional vision-language guided approach produces higher-quality multi-modal features sent to the decoder, facilitating adaptive propagation of fine-grained semantic information from textual features to visual features. Experiments on RefCOCO, RefCOCO+, and G-Ref datasets with various backbones consistently show our approach outperforming state-of-the-art methods.
Read more5/21/2024
0
Cross-aware Early Fusion with Stage-divided Vision and Language Transformer Encoders for Referring Image Segmentation
Yubin Cho, Hyunwoo Yu, Suk-ju Kang
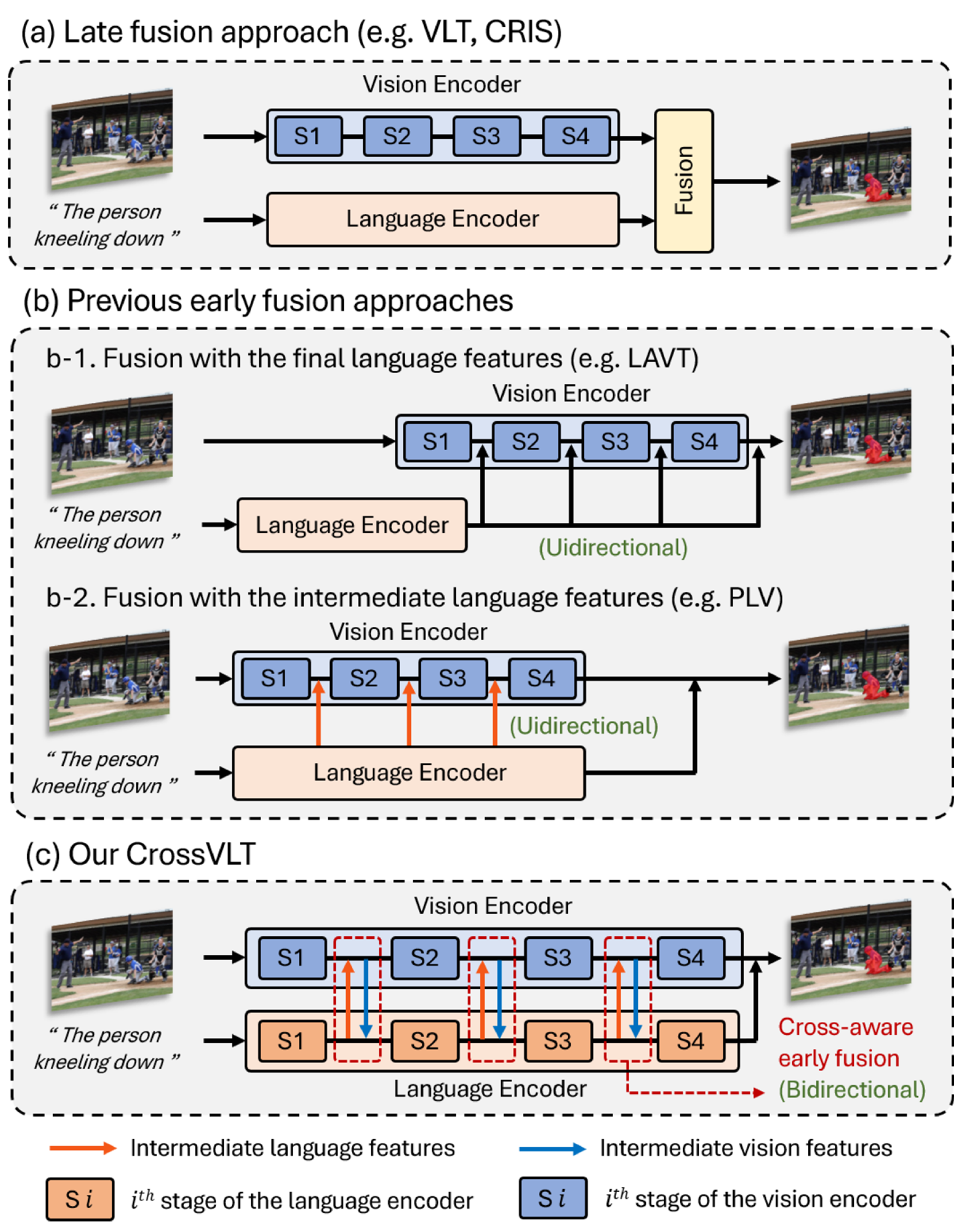
Referring segmentation aims to segment a target object related to a natural language expression. Key challenges of this task are understanding the meaning of complex and ambiguous language expressions and determining the relevant regions in the image with multiple objects by referring to the expression. Recent models have focused on the early fusion with the language features at the intermediate stage of the vision encoder, but these approaches have a limitation that the language features cannot refer to the visual information. To address this issue, this paper proposes a novel architecture, Cross-aware early fusion with stage-divided Vision and Language Transformer encoders (CrossVLT), which allows both language and vision encoders to perform the early fusion for improving the ability of the cross-modal context modeling. Unlike previous methods, our method enables the vision and language features to refer to each other's information at each stage to mutually enhance the robustness of both encoders. Furthermore, unlike the conventional scheme that relies solely on the high-level features for the cross-modal alignment, we introduce a feature-based alignment scheme that enables the low-level to high-level features of the vision and language encoders to engage in the cross-modal alignment. By aligning the intermediate cross-modal features in all encoder stages, this scheme leads to effective cross-modal fusion. In this way, the proposed approach is simple but effective for referring image segmentation, and it outperforms the previous state-of-the-art methods on three public benchmarks.
Read more8/15/2024
0
RefMask3D: Language-Guided Transformer for 3D Referring Segmentation
Shuting He, Henghui Ding
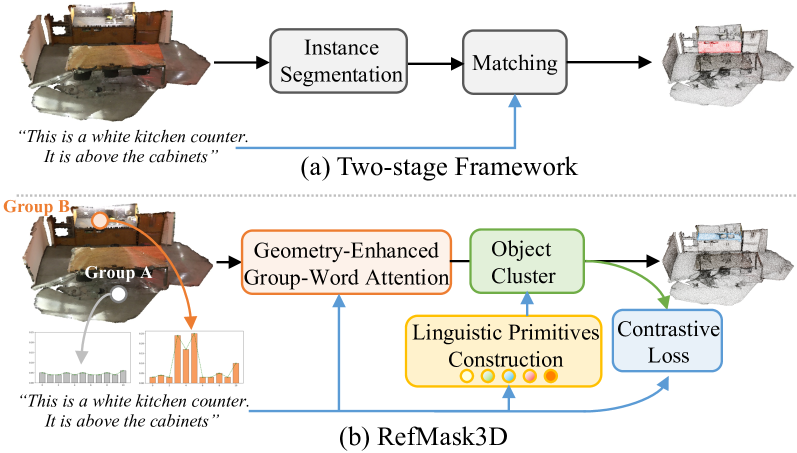
3D referring segmentation is an emerging and challenging vision-language task that aims to segment the object described by a natural language expression in a point cloud scene. The key challenge behind this task is vision-language feature fusion and alignment. In this work, we propose RefMask3D to explore the comprehensive multi-modal feature interaction and understanding. First, we propose a Geometry-Enhanced Group-Word Attention to integrate language with geometrically coherent sub-clouds through cross-modal group-word attention, which effectively addresses the challenges posed by the sparse and irregular nature of point clouds. Then, we introduce a Linguistic Primitives Construction to produce semantic primitives representing distinct semantic attributes, which greatly enhance the vision-language understanding at the decoding stage. Furthermore, we introduce an Object Cluster Module that analyzes the interrelationships among linguistic primitives to consolidate their insights and pinpoint common characteristics, helping to capture holistic information and enhance the precision of target identification. The proposed RefMask3D achieves new state-of-the-art performance on 3D referring segmentation, 3D visual grounding, and also 2D referring image segmentation. Especially, RefMask3D outperforms previous state-of-the-art method by a large margin of 3.16% mIoU} on the challenging ScanRefer dataset. Code is available at https://github.com/heshuting555/RefMask3D.
Read more7/26/2024