Fusion-PSRO: Nash Policy Fusion for Policy Space Response Oracles
2405.21027
0
0
Abstract
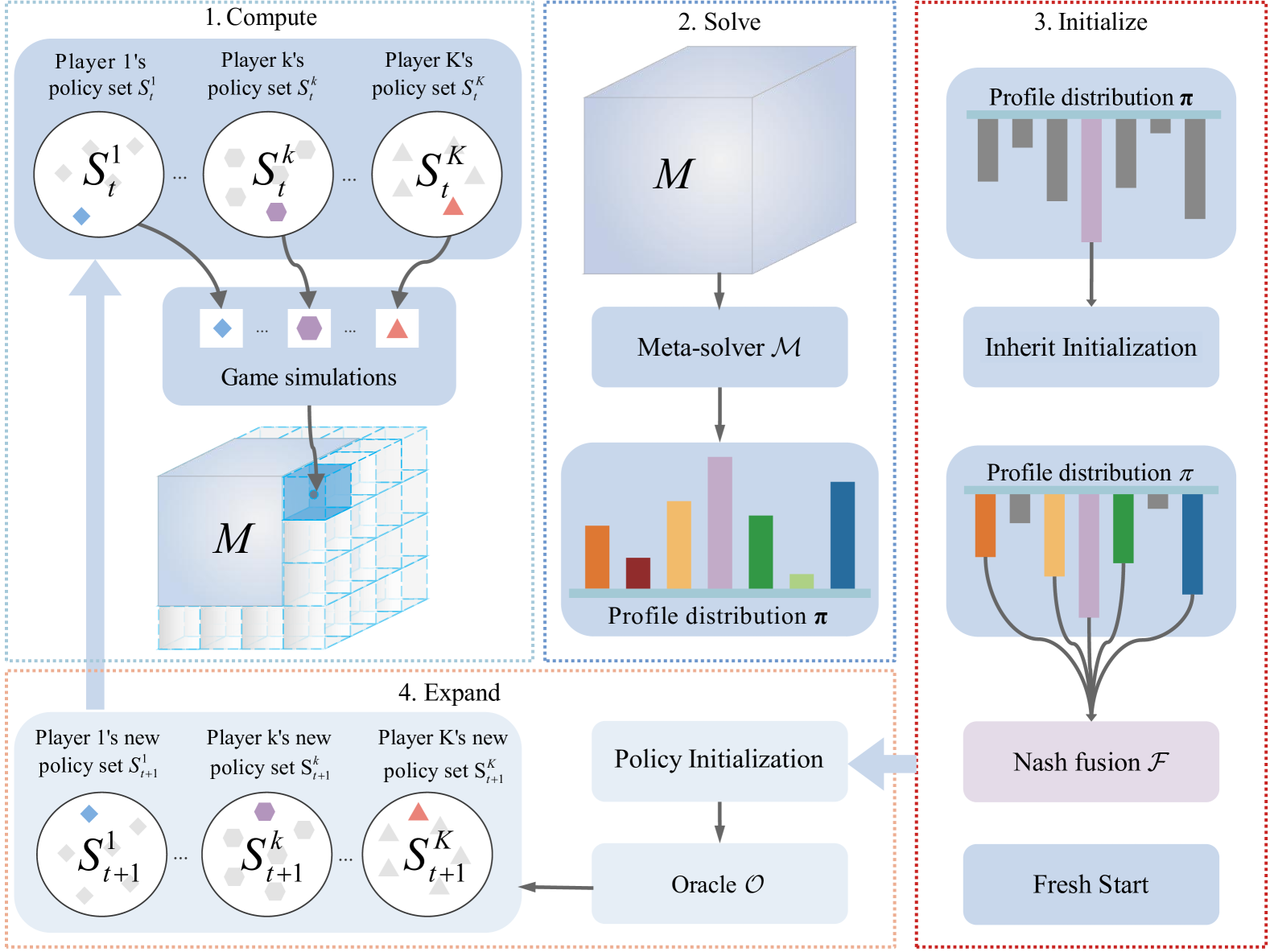
A popular approach for solving zero-sum games is to maintain populations of policies to approximate the Nash Equilibrium (NE). Previous studies have shown that Policy Space Response Oracle (PSRO) algorithm is an effective multi-agent reinforcement learning framework for solving such games. However, repeatedly training new policies from scratch to approximate Best Response (BR) to opponents' mixed policies at each iteration is both inefficient and costly. While some PSRO variants initialize a new policy by inheriting from past BR policies, this approach limits the exploration of new policies, especially against challenging opponents. To address this issue, we propose Fusion-PSRO, which employs policy fusion to initialize policies for better approximation to BR. By selecting high-quality base policies from meta-NE, policy fusion fuses the base policies into a new policy through model averaging. This approach allows the initialized policies to incorporate multiple expert policies, making it easier to handle difficult opponents compared to inheriting from past BR policies or initializing from scratch. Moreover, our method only modifies the policy initialization phase, allowing its application to nearly all PSRO variants without additional training overhead. Our experiments on non-transitive matrix games, Leduc Poker, and the more complex Liars Dice demonstrate that Fusion-PSRO enhances the performance of nearly all PSRO variants, achieving lower exploitability.
Create account to get full access
Overview
- This paper introduces Fusion-PSRO, a novel algorithm for training multi-agent systems using Policy Space Response Oracles (PSRO).
- Fusion-PSRO combines multiple PSRO policies into a single "fused" policy using a Nash equilibrium formulation, which aims to improve the performance and stability of multi-agent training.
- The paper demonstrates the effectiveness of Fusion-PSRO in several multi-agent environments, including matrix games and complex competitive games.
Plain English Explanation
In many real-world scenarios, such as business negotiations or strategic games, multiple intelligent agents need to interact and make decisions together. Policy Space Response Oracles (PSRO) is a powerful technique for training these multi-agent systems, but it can sometimes lead to instability or suboptimal performance.
The Fusion-PSRO algorithm proposed in this paper tries to address these issues. Instead of just using a single PSRO policy, Fusion-PSRO combines multiple PSRO policies into a single "fused" policy. It does this by finding a Nash equilibrium - a way of balancing the different policies to create an optimal overall strategy.
The researchers show that this Fusion-PSRO approach can lead to better performance and more stable training in a variety of multi-agent environments, from simple matrix games to more complex competitive games. By blending multiple PSRO policies together, the system can find a more robust and effective way of navigating the challenges of multi-agent decision-making.
Technical Explanation
The key innovation in this paper is the Fusion-PSRO algorithm, which builds on the Policy Space Response Oracles (PSRO) framework for multi-agent training.
Instead of training a single PSRO policy, Fusion-PSRO trains multiple PSRO policies and then combines them into a single "fused" policy. This fusion process is guided by a Nash equilibrium formulation, which seeks to find the optimal balance between the different PSRO policies.
Specifically, the authors formulate the fusion process as a matrix game, where each row represents a different PSRO policy and the columns represent possible actions. They then solve for the Nash equilibrium of this matrix game, which gives them the optimal way to combine the PSRO policies into a single fused policy.
The researchers evaluate Fusion-PSRO on a range of multi-agent environments, including matrix games and more complex competitive games. They show that the Fusion-PSRO approach outperforms standard PSRO training, leading to more stable and effective multi-agent policies.
Critical Analysis
The Fusion-PSRO algorithm presented in this paper offers a promising approach for improving the performance and stability of multi-agent training using PSRO. By combining multiple PSRO policies into a single fused policy, the method can help address some of the challenges inherent in PSRO, such as instability and suboptimal convergence.
However, the paper does not extensively explore the limitations and potential drawbacks of the Fusion-PSRO approach. For example, the method may be computationally more expensive than standard PSRO, as it requires solving a matrix game to find the Nash equilibrium. Additionally, the effectiveness of the approach may be sensitive to the specific multi-agent environment and the choice of PSRO policies to be fused.
Further research could investigate the scalability of Fusion-PSRO to larger and more complex multi-agent settings, as well as explore alternative policy fusion techniques that may be more computationally efficient or robust to the choice of constituent policies. Analyzing the theoretical properties of the Fusion-PSRO approach, such as its convergence guarantees and sensitivity to hyperparameters, could also provide valuable insights.
Conclusion
The Fusion-PSRO algorithm introduced in this paper represents an important step forward in the field of multi-agent training. By combining multiple PSRO policies into a single fused policy using a Nash equilibrium formulation, the method can improve the performance and stability of multi-agent systems.
The promising results demonstrated on a range of multi-agent environments suggest that Fusion-PSRO could have significant practical applications in areas such as business negotiations, strategic decision-making, and complex games. Further research to address the potential limitations and explore alternative policy fusion techniques could help unlock the full potential of this approach and contribute to the ongoing advancement of multi-agent AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Policy Space Response Oracles: A Survey
Ariyan Bighashdel, Yongzhao Wang, Stephen McAleer, Rahul Savani, Frans A. Oliehoek
0
0
Game theory provides a mathematical way to study the interaction between multiple decision makers. However, classical game-theoretic analysis is limited in scalability due to the large number of strategies, precluding direct application to more complex scenarios. This survey provides a comprehensive overview of a framework for large games, known as Policy Space Response Oracles (PSRO), which holds promise to improve scalability by focusing attention on sufficient subsets of strategies. We first motivate PSRO and provide historical context. We then focus on the strategy exploration problem for PSRO: the challenge of assembling effective subsets of strategies that still represent the original game well with minimum computational cost. We survey current research directions for enhancing the efficiency of PSRO, and explore the applications of PSRO across various domains. We conclude by discussing open questions and future research.
5/28/2024
🏋️
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Luke Marris, Paul Muller, Marc Lanctot, Karl Tuyls, Thore Graepel
0
0
Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
4/19/2024
🖼️
Best Response Shaping
Milad Aghajohari, Tim Cooijmans, Juan Agustin Duque, Shunichi Akatsuka, Aaron Courville
0
0
We investigate the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation. LOLA and POLA agents learn reciprocity-based cooperative policies by differentiation through a few look-ahead optimization steps of their opponent. However, there is a key limitation in these techniques. Because they consider a few optimization steps, a learning opponent that takes many steps to optimize its return may exploit them. In response, we introduce a novel approach, Best Response Shaping (BRS), which differentiates through an opponent approximating the best response, termed the detective. To condition the detective on the agent's policy for complex games we propose a state-aware differentiable conditioning mechanism, facilitated by a question answering (QA) method that extracts a representation of the agent based on its behaviour on specific environment states. To empirically validate our method, we showcase its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general sum games.
4/11/2024
Reflective Policy Optimization
Yaozhong Gan, Renye Yan, Zhe Wu, Junliang Xing
0
0
On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.
6/7/2024