Policy Space Response Oracles: A Survey
2403.02227
0
0

Abstract
Game theory provides a mathematical way to study the interaction between multiple decision makers. However, classical game-theoretic analysis is limited in scalability due to the large number of strategies, precluding direct application to more complex scenarios. This survey provides a comprehensive overview of a framework for large games, known as Policy Space Response Oracles (PSRO), which holds promise to improve scalability by focusing attention on sufficient subsets of strategies. We first motivate PSRO and provide historical context. We then focus on the strategy exploration problem for PSRO: the challenge of assembling effective subsets of strategies that still represent the original game well with minimum computational cost. We survey current research directions for enhancing the efficiency of PSRO, and explore the applications of PSRO across various domains. We conclude by discussing open questions and future research.
Create account to get full access
Overview
- This paper provides a comprehensive survey of Policy Space Response Oracles (PSRO), a framework for training multi-agent systems in complex, non-zero-sum environments.
- PSRO is a powerful approach that has been applied to a wide range of domains, from game-playing to robot coordination.
- The paper covers the core PSRO algorithm, as well as various extensions and applications that have been developed by researchers.
Plain English Explanation
Policy Space Response Oracles (PSRO) is a framework for training artificial intelligence (AI) systems to work together in complex, real-world environments. Instead of having each AI agent try to "win" against the others, PSRO encourages the agents to find strategies that work well together, even in situations where there may not be a clear "winner."
At a high level, PSRO works by having the AI agents continuously learn from and adapt to each other's strategies. Each agent builds a "library" of different policies (or ways of behaving) that it can choose from, and then selects the best policy to use based on the other agents' current strategies. Over time, this process leads the agents to converge on a set of policies that work well together, rather than trying to "beat" each other.
This is particularly useful in situations where there isn't a clear "right" answer, but rather a need to find a good compromise or balance between different objectives. For example, in a related paper, the authors used PSRO to train AI agents to manage a smart home's energy usage, balancing the needs of the residents with the constraints of the power grid.
By allowing the agents to explore a wide range of possible strategies and adapt to each other's behavior, PSRO can help find solutions that work well in complex, real-world environments, rather than just trying to optimize for a single, predetermined goal.
Technical Explanation
The core of the PSRO framework is the idea of a "Policy Space Response Oracle" (PSRO), which is a machine learning model that can predict how an agent will respond to a given strategy or policy. By training these oracles, the PSRO algorithm can iteratively optimize the agents' policies, converging on a set of strategies that work well together.
Specifically, the PSRO algorithm works as follows:
- Each agent starts with a "library" of possible policies that it can choose from.
- The agents play a series of games against each other, and each agent trains a PSRO oracle to predict how the other agents will respond to its policies.
- Using the PSRO oracles, each agent selects the policy from its library that performs best against the other agents' current strategies, as predicted by the oracles.
- The process then repeats, with the agents updating their policies and oracles based on the previous round of play.
Over time, this process leads the agents to converge on a set of policies that form a Pareto-optimal solution, where no agent can unilaterally improve its performance without negatively impacting the others.
PSRO has been applied to a wide range of multi-agent domains, from game-playing to robot coordination. Researchers have also developed various extensions to the core PSRO algorithm, such as Proximal Policy Optimization-based approaches, to further improve its performance and robustness.
Critical Analysis
The PSRO framework is a powerful tool for training multi-agent systems, but it does have some limitations and potential drawbacks that should be considered:
- Computational complexity: Training the PSRO oracles and iteratively optimizing the agents' policies can be computationally intensive, especially as the number of agents and possible strategies grows.
- Scalability: While PSRO has been applied to a wide range of domains, the performance and convergence properties of the algorithm may degrade as the complexity of the environment increases.
- Interpretability: The "black box" nature of the PSRO oracles and the iterative policy optimization process can make it difficult to understand and explain the reasoning behind the agents' final strategies.
- Potential for unintended consequences: In complex, real-world environments, the agents' learned strategies may have unexpected or unintended effects that need to be carefully monitored and addressed.
Researchers are actively working to address these challenges and expand the capabilities of the PSRO framework. For example, some have explored ways to improve the computational efficiency of the algorithm, while others have focused on enhancing the interpretability and safety of the agents' learned behaviors.
Conclusion
The Policy Space Response Oracles (PSRO) framework is a powerful and versatile approach for training multi-agent systems in complex, non-zero-sum environments. By allowing the agents to continuously learn from and adapt to each other's strategies, PSRO can help find solutions that balance the needs and objectives of all parties involved, rather than simply trying to "win" at all costs.
While PSRO does have some limitations and challenges that need to be addressed, the framework has already been applied to a wide range of domains, from game-playing to robot coordination, with promising results. As researchers continue to refine and expand the capabilities of PSRO, it has the potential to play an increasingly important role in the development of AI systems that can effectively navigate the complexities of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
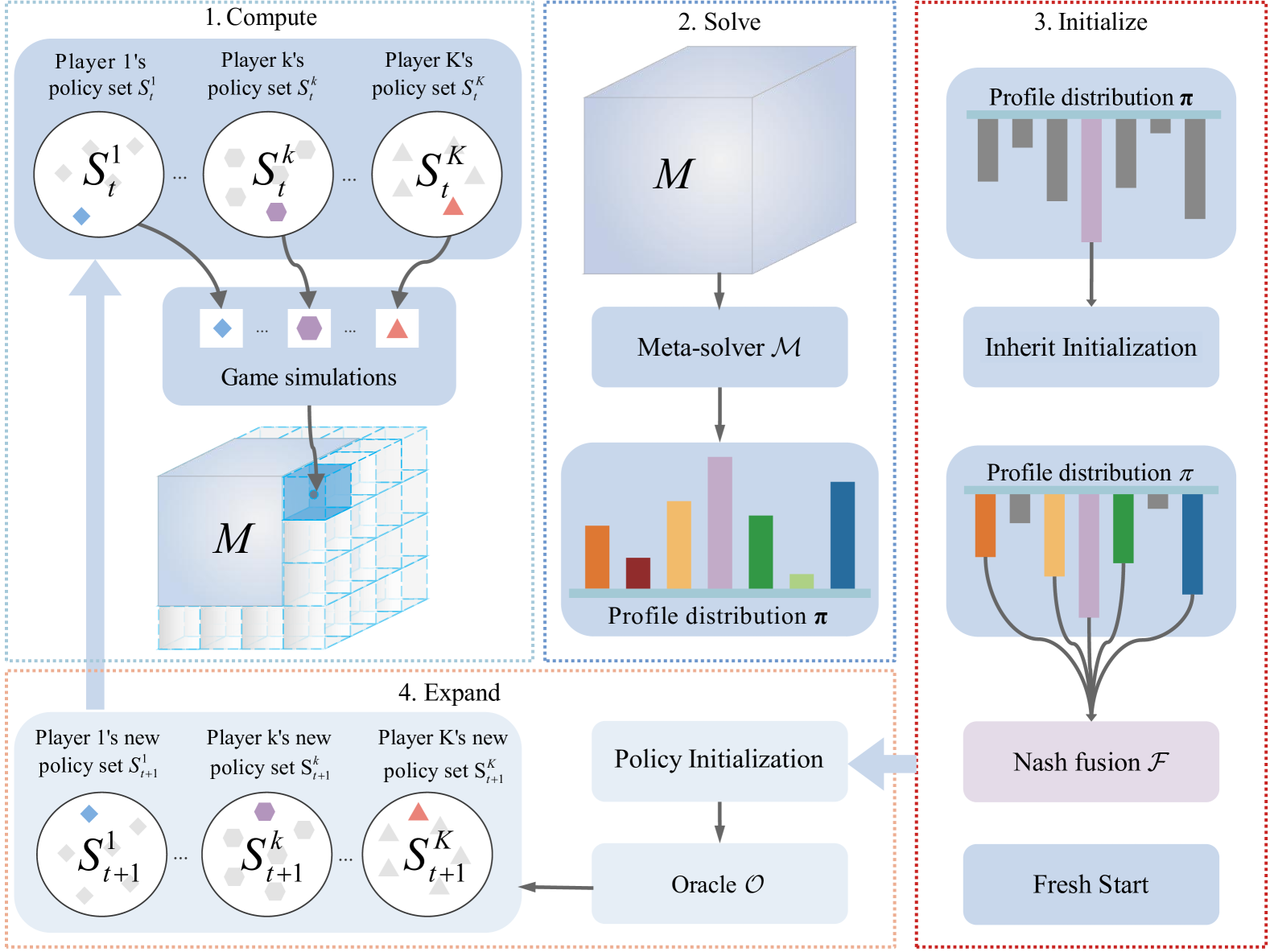
Fusion-PSRO: Nash Policy Fusion for Policy Space Response Oracles
Jiesong Lian
0
0
A popular approach for solving zero-sum games is to maintain populations of policies to approximate the Nash Equilibrium (NE). Previous studies have shown that Policy Space Response Oracle (PSRO) algorithm is an effective multi-agent reinforcement learning framework for solving such games. However, repeatedly training new policies from scratch to approximate Best Response (BR) to opponents' mixed policies at each iteration is both inefficient and costly. While some PSRO variants initialize a new policy by inheriting from past BR policies, this approach limits the exploration of new policies, especially against challenging opponents. To address this issue, we propose Fusion-PSRO, which employs policy fusion to initialize policies for better approximation to BR. By selecting high-quality base policies from meta-NE, policy fusion fuses the base policies into a new policy through model averaging. This approach allows the initialized policies to incorporate multiple expert policies, making it easier to handle difficult opponents compared to inheriting from past BR policies or initializing from scratch. Moreover, our method only modifies the policy initialization phase, allowing its application to nearly all PSRO variants without additional training overhead. Our experiments on non-transitive matrix games, Leduc Poker, and the more complex Liars Dice demonstrate that Fusion-PSRO enhances the performance of nearly all PSRO variants, achieving lower exploitability.
6/24/2024
🏋️
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Luke Marris, Paul Muller, Marc Lanctot, Karl Tuyls, Thore Graepel
0
0
Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
4/19/2024
🎯
ApproxED: Approximate exploitability descent via learned best responses
Carlos Martin, Tuomas Sandholm
0
0
There has been substantial progress on finding game-theoretic equilibria. Most of that work has focused on games with finite, discrete action spaces. However, many games involving space, time, money, and other fine-grained quantities have continuous action spaces (or are best modeled as having such). We study the problem of finding an approximate Nash equilibrium of games with continuous action sets. The standard measure of closeness to Nash equilibrium is exploitability, which measures how much players can benefit from unilaterally changing their strategy. We propose two new methods that minimize an approximation of exploitability with respect to the strategy profile. The first method uses a learned best-response function, which takes the current strategy profile as input and outputs candidate best responses for each player. The strategy profile and best-response functions are trained simultaneously, with the former trying to minimize exploitability while the latter tries to maximize it. The second method maintains an ensemble of candidate best responses for each player. In each iteration, the best-performing elements of each ensemble are used to update the current strategy profile. The strategy profile and ensembles are simultaneously trained to minimize and maximize the approximate exploitability, respectively. We evaluate our methods on various continuous games and GAN training, showing that they outperform prior methods.
6/14/2024

Searching for Programmatic Policies in Semantic Spaces
Rubens O. Moraes, Levi H. S. Lelis
0
0
Syntax-guided synthesis is commonly used to generate programs encoding policies. In this approach, the set of programs, that can be written in a domain-specific language defines the search space, and an algorithm searches within this space for programs that encode strong policies. In this paper, we propose an alternative method for synthesizing programmatic policies, where we search within an approximation of the language's semantic space. We hypothesized that searching in semantic spaces is more sample-efficient compared to syntax-based spaces. Our rationale is that the search is more efficient if the algorithm evaluates different agent behaviors as it searches through the space, a feature often missing in syntax-based spaces. This is because small changes in the syntax of a program often do not result in different agent behaviors. We define semantic spaces by learning a library of programs that present different agent behaviors. Then, we approximate the semantic space by defining a neighborhood function for local search algorithms, where we replace parts of the current candidate program with programs from the library. We evaluated our hypothesis in a real-time strategy game called MicroRTS. Empirical results support our hypothesis that searching in semantic spaces can be more sample-efficient than searching in syntax-based spaces.
6/14/2024