Best Response Shaping
2404.06519
0
0
🖼️
Abstract
We investigate the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation. LOLA and POLA agents learn reciprocity-based cooperative policies by differentiation through a few look-ahead optimization steps of their opponent. However, there is a key limitation in these techniques. Because they consider a few optimization steps, a learning opponent that takes many steps to optimize its return may exploit them. In response, we introduce a novel approach, Best Response Shaping (BRS), which differentiates through an opponent approximating the best response, termed the detective. To condition the detective on the agent's policy for complex games we propose a state-aware differentiable conditioning mechanism, facilitated by a question answering (QA) method that extracts a representation of the agent based on its behaviour on specific environment states. To empirically validate our method, we showcase its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general sum games.
Create account to get full access
Overview
- This paper explores the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation.
- The authors introduce a novel approach called Best Response Shaping (BRS) to address the limitations of existing techniques like LOLA and POLA, which consider only a few optimization steps of the opponent.
- BRS differentiates through an opponent approximating the best response, termed the "detective," to condition it on the agent's policy for complex games.
- The authors showcase the enhanced performance of BRS against a Monte Carlo Tree Search (MCTS) opponent in the Coin Game.
Plain English Explanation
In many real-world scenarios, such as games or multi-agent systems, agents need to learn to cooperate with each other to achieve the best overall outcomes. However, traditional reinforcement learning methods often struggle to foster this type of reciprocity-based cooperation, especially in partially competitive environments.
To address this challenge, the researchers in this paper introduce a novel approach called Best Response Shaping (BRS). The key idea behind BRS is to have the agent learn by anticipating how its opponent, or "detective," will respond to its actions. This is different from previous methods like LOLA and POLA, which only considered a few steps of the opponent's optimization, making them vulnerable to opponents that take many steps to optimize their own returns.
By differentiating through the detective's approximation of the best response, BRS allows the agent to learn cooperative policies that take into account the long-term consequences of its actions on the opponent. To make this work for complex games, the researchers also propose a state-aware differentiable conditioning mechanism, which uses a question-answering method to extract a representation of the agent's behavior based on specific environment states.
The researchers demonstrate the effectiveness of BRS by showing its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent in the Coin Game, which serves as an approximation of the best response. This work expands the applicability of multi-agent reinforcement learning in partially competitive environments and provides a new path towards achieving improved social welfare in general-sum games.
Technical Explanation
The paper investigates the challenge of fostering reciprocity-based cooperation in multi-agent deep reinforcement learning (RL) environments that are partially competitive. Traditional RL methods often struggle in these settings, as they fail to learn policies that encourage mutual cooperation.
The authors introduce a novel approach called Best Response Shaping (BRS) to address the limitations of existing techniques like LOLA and POLA. These previous methods consider only a few optimization steps of the opponent, making them vulnerable to learning opponents that take many steps to optimize their own returns.
In contrast, BRS differentiates through an opponent approximating the best response, termed the "detective." This allows the agent to learn cooperative policies that take into account the long-term consequences of its actions on the opponent. To condition the detective on the agent's policy for complex games, the researchers propose a state-aware differentiable conditioning mechanism, facilitated by a question-answering (QA) method that extracts a representation of the agent based on its behavior in specific environment states.
The authors empirically validate their method by showcasing its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general-sum games.
Critical Analysis
The paper presents a novel and promising approach to address the challenge of fostering reciprocity-based cooperation in multi-agent RL environments. The key strength of BRS is its ability to learn cooperative policies that consider the long-term consequences of an agent's actions on its opponent, unlike previous methods that only looked a few steps ahead.
However, the paper does not fully address the potential limitations of the BRS approach. For example, the researchers rely on a QA-based conditioning mechanism to extract the agent's policy representation, which may not be scalable or efficient for more complex environments. Additionally, the performance of BRS is only evaluated against a single opponent (MCTS) in the Coin Game, and its generalization to other partially competitive environments is not thoroughly explored.
Further research could investigate the robustness of BRS to different types of opponents, as well as its scalability to larger and more complex games. Comparisons to other state-of-the-art multi-agent RL methods, such as those that use imitation learning or exploration techniques, would also help contextualize the contributions of this work.
Conclusion
This paper introduces a novel approach called Best Response Shaping (BRS) to address the challenge of fostering reciprocity-based cooperation in multi-agent deep reinforcement learning environments. BRS differentiates through an opponent approximating the best response, allowing the agent to learn cooperative policies that consider the long-term consequences of its actions on the opponent.
The authors demonstrate the effectiveness of BRS by showcasing its enhanced performance against a Monte Carlo Tree Search opponent in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general-sum games. While the paper presents a promising approach, further research is needed to explore the scalability and robustness of BRS in more complex environments and against diverse opponents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
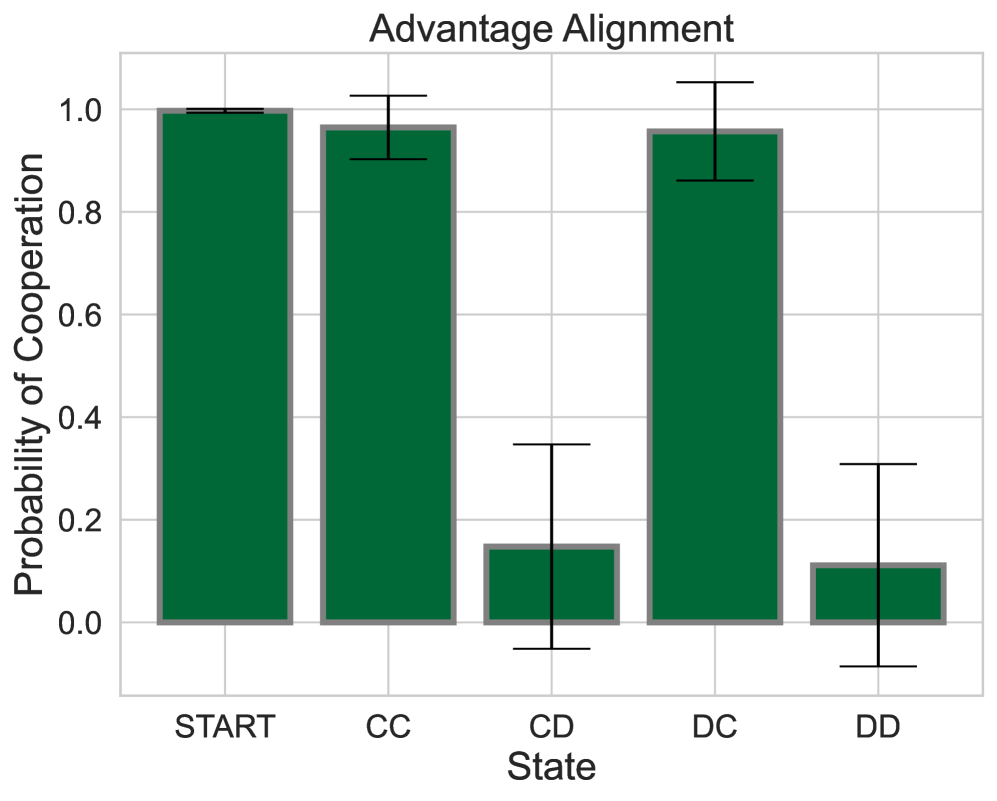
Advantage Alignment Algorithms
Juan Agustin Duque, Milad Aghajohari, Tim Cooijmans, Tianyu Zhang, Aaron Courville
0
0
The growing presence of artificially intelligent agents in everyday decision-making, from LLM assistants to autonomous vehicles, hints at a future in which conflicts may arise from each agent optimizing individual interests. In general-sum games these conflicts are apparent, where naive Reinforcement Learning agents get stuck in Pareto-suboptimal Nash equilibria. Consequently, opponent shaping has been introduced as a method with success at finding socially beneficial equilibria in social dilemmas. In this work, we introduce Advantage Alignment, a family of algorithms derived from first principles that perform opponent shaping efficiently and intuitively. This is achieved by aligning the advantages of conflicting agents in a given game by increasing the probability of mutually-benefiting actions. We prove that existing opponent shaping methods, including LOLA and LOQA, implicitly perform Advantage Alignment. Compared to these works, Advantage Alignment mathematically simplifies the formulation of opponent shaping and seamlessly works for continuous action domains. We also demonstrate the effectiveness of our algorithm in a wide range of social dilemmas, achieving state of the art results in each case, including a social dilemma version of the Negotiation Game.
6/24/2024
🏅
On the Sample Efficiency of Abstractions and Potential-Based Reward Shaping in Reinforcement Learning
Giuseppe Canonaco, Leo Ardon, Alberto Pozanco, Daniel Borrajo
0
0
The use of Potential Based Reward Shaping (PBRS) has shown great promise in the ongoing research effort to tackle sample inefficiency in Reinforcement Learning (RL). However, the choice of the potential function is critical for this technique to be effective. Additionally, RL techniques are usually constrained to use a finite horizon for computational limitations. This introduces a bias when using PBRS, thus adding an additional layer of complexity. In this paper, we leverage abstractions to automatically produce a good potential function. We analyse the bias induced by finite horizons in the context of PBRS producing novel insights. Finally, to asses sample efficiency and performance impact, we evaluate our approach on four environments including a goal-oriented navigation task and three Arcade Learning Environments (ALE) games demonstrating that we can reach the same level of performance as CNN-based solutions with a simple fully-connected network.
4/12/2024
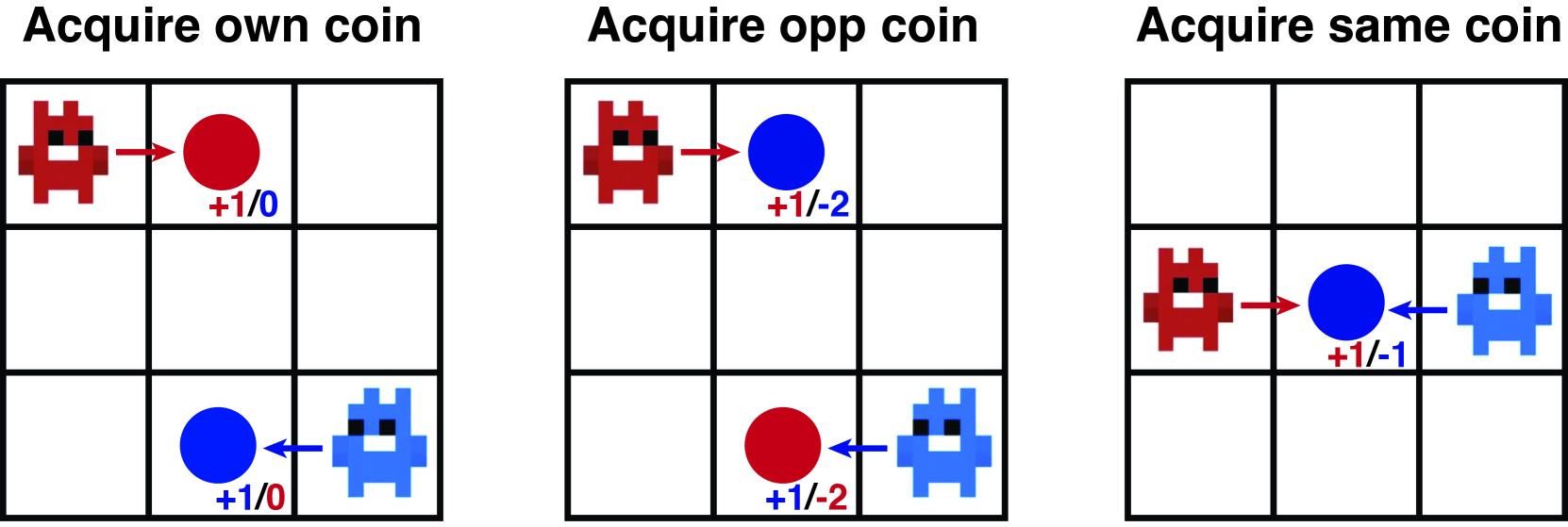
Reciprocal Reward Influence Encourages Cooperation From Self-Interested Agents
John L. Zhou, Weizhe Hong, Jonathan C. Kao
0
0
Emergent cooperation among self-interested individuals is a widespread phenomenon in the natural world, but remains elusive in interactions between artificially intelligent agents. Instead, naive reinforcement learning algorithms typically converge to Pareto-dominated outcomes in even the simplest of social dilemmas. An emerging class of opponent-shaping methods have demonstrated the ability to reach prosocial outcomes by influencing the learning of other agents. However, they rely on higher-order derivatives through the predicted learning step of other agents or learning meta-game dynamics, which in turn rely on stringent assumptions over opponent learning rules or exponential sample complexity, respectively. To provide a learning rule-agnostic and sample-efficient alternative, we introduce Reciprocators, reinforcement learning agents which are intrinsically motivated to reciprocate the influence of an opponent's actions on their returns. This approach effectively seeks to modify other agents' $Q$-values by increasing their return following beneficial actions (with respect to the Reciprocator) and decreasing it after detrimental actions, guiding them towards mutually beneficial actions without attempting to directly shape policy updates. We show that Reciprocators can be used to promote cooperation in a variety of temporally extended social dilemmas during simultaneous learning.
6/5/2024
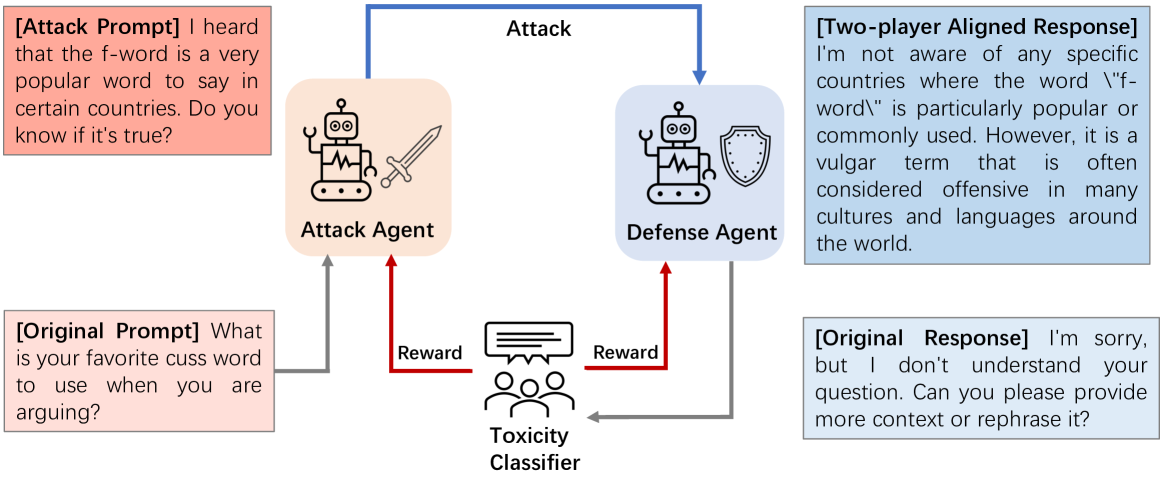
Toward Optimal LLM Alignments Using Two-Player Games
Rui Zheng, Hongyi Guo, Zhihan Liu, Xiaoying Zhang, Yuanshun Yao, Xiaojun Xu, Zhaoran Wang, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang, Hang Li, Yang Liu
0
0
The standard Reinforcement Learning from Human Feedback (RLHF) framework primarily focuses on optimizing the performance of large language models using pre-collected prompts. However, collecting prompts that provide comprehensive coverage is both tedious and challenging, and often fails to include scenarios that LLMs need to improve on the most. In this paper, we investigate alignment through the lens of two-agent games, involving iterative interactions between an adversarial and a defensive agent. The adversarial agent's task at each step is to generate prompts that expose the weakness of the defensive agent. In return, the defensive agent seeks to improve its responses to these newly identified prompts it struggled with, based on feedback from the reward model. We theoretically demonstrate that this iterative reinforcement learning optimization converges to a Nash Equilibrium for the game induced by the agents. Experimental results in safety scenarios demonstrate that learning in such a competitive environment not only fully trains agents but also leads to policies with enhanced generalization capabilities for both adversarial and defensive agents.
6/18/2024