Gaussian Flow Bridges for Audio Domain Transfer with Unpaired Data

0

Sign in to get full access
Overview
- This paper introduces Gaussian Flow Bridges (GFB), a novel technique for transferring audio data between different domains without requiring paired samples.
- GFB leverages diffusion models to learn a distribution mapping between unpaired audio samples, enabling effective domain adaptation.
- The method is evaluated on several audio transfer tasks, demonstrating improvements over existing approaches.
Plain English Explanation
Transferring audio data between different domains, such as converting speech to singing or converting one musical style to another, is a challenging problem. Traditional methods often require paired samples - for example, recordings of the same audio content in both the source and target domains. However, obtaining such paired data can be difficult and time-consuming.
The researchers behind this paper have developed a new technique called Gaussian Flow Bridges (GFB) that can perform audio domain transfer without requiring paired data. GFB uses a type of machine learning model called a diffusion model to learn the relationship between the source and target audio domains. Diffusion models work by gradually adding noise to data, then learning to reverse the process and recover the original data.
By applying this diffusion process to audio data from different domains, GFB can learn how to map between the domains, even when the samples are unpaired. This allows for more flexible and practical audio domain transfer, as the method doesn't depend on having perfectly matched source and target recordings.
The researchers evaluated GFB on several audio transfer tasks, such as converting speech to singing and converting musical styles. They found that GFB outperformed existing approaches that require paired data, demonstrating the power of this new technique for audio domain adaptation.
Technical Explanation
The core idea behind GFB is to leverage diffusion models to learn a distribution mapping between unpaired audio samples from different domains. Diffusion models work by gradually adding noise to data, then learning to reverse the process and recover the original data.
By applying this diffusion process to audio data from different domains, GFB can learn how to map between the domains, even when the samples are unpaired. This is achieved by training a pair of diffusion models - one for the source domain and one for the target domain - and then learning a "bridge" that connects the two diffusion processes.
The architecture of GFB consists of several key components:
- Diffusion models for the source and target audio domains
- A "bridging" module that maps between the two diffusion processes
- A discriminator network that helps align the source and target distributions
During training, the diffusion models learn to generate realistic audio in their respective domains, while the bridging module learns to translate between the two diffusion processes. The discriminator network provides additional guidance to ensure that the translated audio samples match the target domain distribution.
The researchers also explored ways to make the GFB model more versatile, such as by incorporating a mixture of noise levels and using a transformer-based architecture.
Critical Analysis
The main limitation of GFB is that it still relies on having some amount of unlabeled data from both the source and target domains. While this is less restrictive than requiring perfectly paired data, it may still be challenging to obtain in some real-world scenarios.
Additionally, the paper does not address the potential for privacy or security issues when transferring sensitive audio data between domains. It would be important to consider these concerns in any practical deployment of the technology.
Overall, GFB represents an interesting and promising approach to audio domain transfer, but further research is needed to address its limitations and potential risks.
Conclusion
The Gaussian Flow Bridges (GFB) technique introduced in this paper offers a novel way to perform audio domain transfer without requiring paired data. By leveraging diffusion models and a bridging mechanism, GFB can effectively map between source and target audio domains, enabling more flexible and practical applications of audio domain adaptation.
The results demonstrated in the paper suggest that GFB outperforms existing methods that rely on paired data, making it a valuable tool for a wide range of audio processing tasks. As the research continues to evolve, it will be important to address the remaining challenges and considerations to ensure the safe and responsible deployment of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gaussian Flow Bridges for Audio Domain Transfer with Unpaired Data
Eloi Moliner, Sebastian Braun, Hannes Gamper
Audio domain transfer is the process of modifying audio signals to match characteristics of a different domain, while retaining the original content. This paper investigates the potential of Gaussian Flow Bridges, an emerging approach in generative modeling, for this problem. The presented framework addresses the transport problem across different distributions of audio signals through the implementation of a series of two deterministic probability flows. The proposed framework facilitates manipulation of the target distribution properties through a continuous control variable, which defines a certain aspect of the target domain. Notably, this approach does not rely on paired examples for training. To address identified challenges on maintaining the speech content consistent, we recommend a training strategy that incorporates chunk-based minibatch Optimal Transport couplings of data samples and noise. Comparing our unsupervised method with established baselines, we find competitive performance in tasks of reverberation and distortion manipulation. Despite encoutering limitations, the intriguing results obtained in this study underscore potential for further exploration.
Read more5/31/2024
🤷
0
Latent Diffusion Bridges for Unsupervised Musical Audio Timbre Transfer
Michele Mancusi, Yurii Halychanskyi, Kin Wai Cheuk, Chieh-Hsin Lai, Stefan Uhlich, Junghyun Koo, Marco A. Mart'inez-Ram'irez, Wei-Hsiang Liao, Giorgio Fabbro, Yuhki Mitsufuji
Music timbre transfer is a challenging task that involves modifying the timbral characteristics of an audio signal while preserving its melodic structure. In this paper, we propose a novel method based on dual diffusion bridges, trained using the CocoChorales Dataset, which consists of unpaired monophonic single-instrument audio data. Each diffusion model is trained on a specific instrument with a Gaussian prior. During inference, a model is designated as the source model to map the input audio to its corresponding Gaussian prior, and another model is designated as the target model to reconstruct the target audio from this Gaussian prior, thereby facilitating timbre transfer. We compare our approach against existing unsupervised timbre transfer models such as VAEGAN and Gaussian Flow Bridges (GFB). Experimental results demonstrate that our method achieves both better Fr'echet Audio Distance (FAD) and melody preservation, as reflected by lower pitch distances (DPD) compared to VAEGAN and GFB. Additionally, we discover that the noise level from the Gaussian prior, $sigma$, can be adjusted to control the degree of melody preservation and amount of timbre transferred.
Read more9/16/2024

0
Schrodinger Bridge Flow for Unpaired Data Translation
Valentin De Bortoli, Iryna Korshunova, Andriy Mnih, Arnaud Doucet
Mass transport problems arise in many areas of machine learning whereby one wants to compute a map transporting one distribution to another. Generative modeling techniques like Generative Adversarial Networks (GANs) and Denoising Diffusion Models (DDMs) have been successfully adapted to solve such transport problems, resulting in CycleGAN and Bridge Matching respectively. However, these methods do not approximate Optimal Transport (OT) maps, which are known to have desirable properties. Existing techniques approximating OT maps for high-dimensional data-rich problems, such as DDM-based Rectified Flow and Schrodinger Bridge procedures, require fully training a DDM-type model at each iteration, or use mini-batch techniques which can introduce significant errors. We propose a novel algorithm to compute the Schrodinger Bridge, a dynamic entropy-regularised version of OT, that eliminates the need to train multiple DDM-like models. This algorithm corresponds to a discretisation of a flow of path measures, which we call the Schrodinger Bridge Flow, whose only stationary point is the Schrodinger Bridge. We demonstrate the performance of our algorithm on a variety of unpaired data translation tasks.
Read more9/17/2024
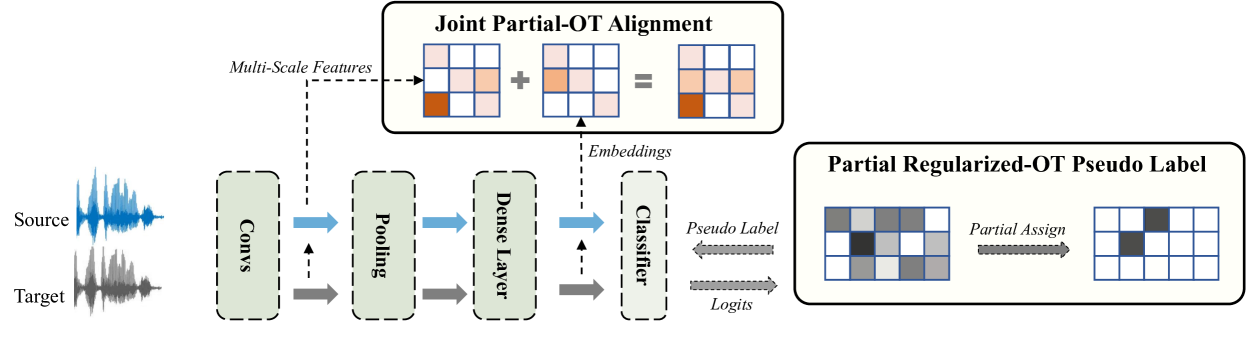
0
Channel Adaptation for Speaker Verification Using Optimal Transport with Pseudo Label
Wenhao Yang, Jianguo Wei, Wenhuan Lu, Lei Li, Xugang Lu
Domain gap often degrades the performance of speaker verification (SV) systems when the statistical distributions of training data and real-world test speech are mismatched. Channel variation, a primary factor causing this gap, is less addressed than other issues (e.g., noise). Although various domain adaptation algorithms could be applied to handle this domain gap problem, most algorithms could not take the complex distribution structure in domain alignment with discriminative learning. In this paper, we propose a novel unsupervised domain adaptation method, i.e., Joint Partial Optimal Transport with Pseudo Label (JPOT-PL), to alleviate the channel mismatch problem. Leveraging the geometric-aware distance metric of optimal transport in distribution alignment, we further design a pseudo label-based discriminative learning where the pseudo label can be regarded as a new type of soft speaker label derived from the optimal coupling. With the JPOT-PL, we carry out experiments on the SV channel adaptation task with VoxCeleb as the basis corpus. Experiments show our method reduces EER by over 10% compared with several state-of-the-art channel adaptation algorithms.
Read more9/17/2024