Gaze-guided Hand-Object Interaction Synthesis: Dataset and Method

0

Sign in to get full access
Overview
- This paper presents a benchmark and method for gaze-guided hand-object interaction synthesis.
- It focuses on predicting and utilizing gaze information for perceiving and interacting with objects in a 3D environment.
- The authors introduce a new dataset and benchmark for evaluating gaze-guided hand-object interaction synthesis and propose a novel method to address this task.
Plain English Explanation
The paper explores the idea of using a person's gaze, or the direction they are looking, to guide how they interact with objects in a 3D virtual environment. The authors created a new dataset and benchmark to evaluate systems that can generate realistic hand-object interactions based on gaze information. They also developed a new method that can take gaze data as input and produce animations of a person's hands manipulating objects in a natural, human-like way.
The key insight is that a person's gaze often provides important cues about their intentions and the objects they are interested in. By incorporating this gaze information, the system can generate hand-object interactions that are more aligned with how people would naturally interact with things in the real world. This could have applications in areas like virtual reality, robotics, and human-computer interaction, where realistic hand-object coordination is important.
Technical Explanation
The paper first reviews prior work on predicting and utilizing gaze information for perception and interaction tasks. This includes research on gaze-based object detection, gaze-guided robot control, and generating gaze-aware animations.
The authors then introduce a new dataset and benchmark for evaluating gaze-guided hand-object interaction synthesis. The dataset contains RGB-D videos of people performing various object manipulation tasks while their gaze is tracked. This provides the ground truth data needed to train and evaluate models.
The paper then presents a novel method for generating gaze-guided hand-object interactions. The key components are:
- Gaze Prediction: A model that can predict where a person is looking based on visual inputs.
- Hand-Object Interaction: A generative model that can produce realistic hand movements for manipulating objects, conditioned on the predicted gaze information.
The authors evaluate their approach on the new benchmark dataset and show that it outperforms previous methods that do not use gaze information. The generated hand-object interactions are more natural and aligned with the person's gaze patterns.
Critical Analysis
The paper makes a compelling case for the importance of incorporating gaze information when synthesizing hand-object interactions. The new benchmark dataset and evaluation metrics provide a valuable resource for advancing research in this area.
However, the paper does not address some potential limitations of the approach. For example, the dataset may not fully capture the diversity of hand-object interactions that occur in the real world, as it is limited to specific task scenarios. Additionally, the gaze prediction model may struggle in more unconstrained environments with complex visual scenes.
Further research is needed to understand the robustness and generalizability of the proposed method. Exploring ways to make the system more adaptive and less reliant on the specific dataset used for training would be an important next step.
Conclusion
This paper presents a novel approach to gaze-guided hand-object interaction synthesis, supported by a new benchmark dataset and evaluation framework. By incorporating gaze information, the method can generate more natural and human-like hand movements when interacting with objects in a 3D environment.
The research has the potential to impact various applications, such as virtual reality, robotics, and human-computer interaction, where realistic hand-object coordination is crucial. While the current approach shows promise, further work is needed to address its limitations and enhance its robustness and generalizability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gaze-guided Hand-Object Interaction Synthesis: Dataset and Method
Jie Tian, Ran Ji, Lingxiao Yang, Yuexin Ma, Lan Xu, Jingyi Yu, Ye Shi, Jingya Wang
Gaze plays a crucial role in revealing human attention and intention, particularly in hand-object interaction scenarios, where it guides and synchronizes complex tasks that require precise coordination between the brain, hand, and object. Motivated by this, we introduce a novel task: Gaze-Guided Hand-Object Interaction Synthesis, with potential applications in augmented reality, virtual reality, and assistive technologies. To support this task, we present GazeHOI, the first dataset to capture simultaneous 3D modeling of gaze, hand, and object interactions. This task poses significant challenges due to the inherent sparsity and noise in gaze data, as well as the need for high consistency and physical plausibility in generating hand and object motions. To tackle these issues, we propose a stacked gaze-guided hand-object interaction diffusion model, named GHO-Diffusion. The stacked design effectively reduces the complexity of motion generation. We also introduce HOI-Manifold Guidance during the sampling stage of GHO-Diffusion, enabling fine-grained control over generated motions while maintaining the data manifold. Additionally, we propose a spatial-temporal gaze feature encoding for the diffusion condition and select diffusion results based on consistency scores between gaze-contact maps and gaze-interaction trajectories. Extensive experiments highlight the effectiveness of our method and the unique contributions of our dataset.
Read more8/23/2024
⛏️
0
New!ChildPlay-Hand: A Dataset of Hand Manipulations in the Wild
Arya Farkhondeh, Samy Tafasca, Jean-Marc Odobez
Hand-Object Interaction (HOI) is gaining significant attention, particularly with the creation of numerous egocentric datasets driven by AR/VR applications. However, third-person view HOI has received less attention, especially in terms of datasets. Most third-person view datasets are curated for action recognition tasks and feature pre-segmented clips of high-level daily activities, leaving a gap for in-the-wild datasets. To address this gap, we propose ChildPlay-Hand, a novel dataset that includes person and object bounding boxes, as well as manipulation actions. ChildPlay-Hand is unique in: (1) providing per-hand annotations; (2) featuring videos in uncontrolled settings with natural interactions, involving both adults and children; (3) including gaze labels from the ChildPlay-Gaze dataset for joint modeling of manipulations and gaze. The manipulation actions cover the main stages of an HOI cycle, such as grasping, holding or operating, and different types of releasing. To illustrate the interest of the dataset, we study two tasks: object in hand detection (OiH), i.e. if a person has an object in their hand, and manipulation stages (ManiS), which is more fine-grained and targets the main stages of manipulation. We benchmark various spatio-temporal and segmentation networks, exploring body vs. hand-region information and comparing pose and RGB modalities. Our findings suggest that ChildPlay-Hand is a challenging new benchmark for modeling HOI in the wild.
Read more9/17/2024
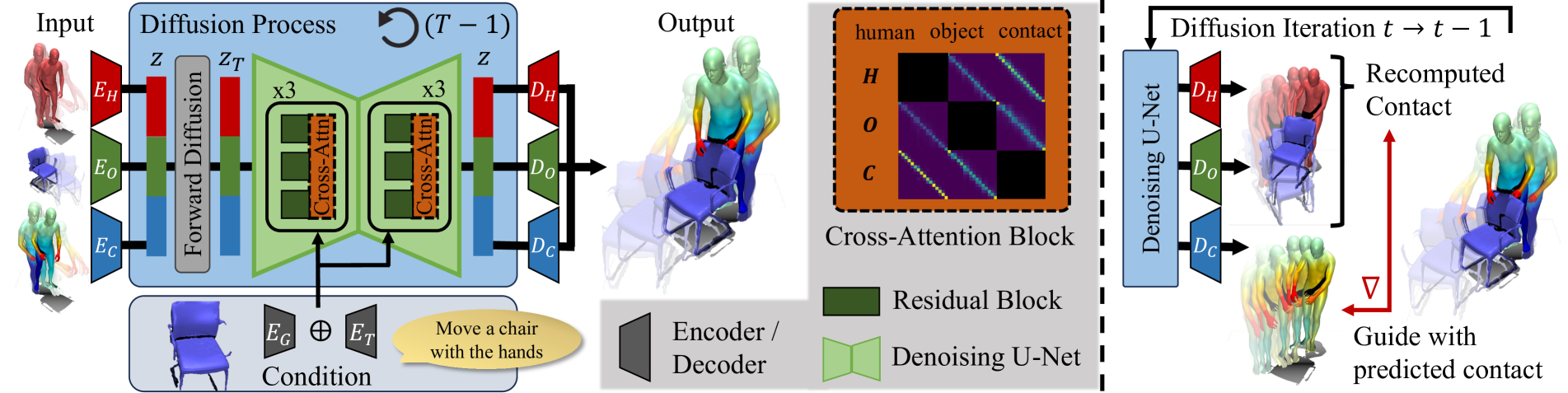
0
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Christian Diller, Angela Dai
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference to synthesize realistic and coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
Read more5/20/2024

0
HOI-Swap: Swapping Objects in Videos with Hand-Object Interaction Awareness
Zihui Xue, Mi Luo, Changan Chen, Kristen Grauman
We study the problem of precisely swapping objects in videos, with a focus on those interacted with by hands, given one user-provided reference object image. Despite the great advancements that diffusion models have made in video editing recently, these models often fall short in handling the intricacies of hand-object interactions (HOI), failing to produce realistic edits -- especially when object swapping results in object shape or functionality changes. To bridge this gap, we present HOI-Swap, a novel diffusion-based video editing framework trained in a self-supervised manner. Designed in two stages, the first stage focuses on object swapping in a single frame with HOI awareness; the model learns to adjust the interaction patterns, such as the hand grasp, based on changes in the object's properties. The second stage extends the single-frame edit across the entire sequence; we achieve controllable motion alignment with the original video by: (1) warping a new sequence from the stage-I edited frame based on sampled motion points and (2) conditioning video generation on the warped sequence. Comprehensive qualitative and quantitative evaluations demonstrate that HOI-Swap significantly outperforms existing methods, delivering high-quality video edits with realistic HOIs.
Read more6/13/2024