Beyond Known Clusters: Probe New Prototypes for Efficient Generalized Class Discovery

0

Sign in to get full access
Overview
• This research paper explores a new approach for efficiently discovering previously unknown classes or categories in datasets, a task known as generalized class discovery. • The proposed method, called "Probe New Prototypes" (PNP), aims to go beyond relying solely on known class clusters and instead probes for new prototype representations that can capture emerging classes. • PNP leverages a combination of contrastive learning, prototype-based clustering, and a novel query-based sampling strategy to efficiently identify these new prototypes.
Plain English Explanation
• The paper tackles the problem of generalized class discovery, which is the ability to find new classes or categories in a dataset that were not part of the original training data. • Existing methods for this task often rely on identifying "clusters" of similar data points, but the authors argue that this approach has limitations and may miss important new classes. • Instead, the Probe New Prototypes (PNP) method proposed in this paper tries to directly find new prototype representations that can capture these emerging classes, rather than just grouping data into known clusters. • PNP uses a combination of contrastive learning (to learn meaningful feature representations), prototype-based clustering (to identify candidate prototypes), and a novel query-based sampling strategy (to efficiently explore the data space for new prototypes).
Technical Explanation
• The Probe New Prototypes (PNP) method consists of three main components:
- Contrastive Learning: PNP first learns a feature representation of the data using contrastive learning, which encourages the model to learn meaningful discriminative features.
- Prototype-based Clustering: PNP then performs prototype-based clustering on the learned feature representations to identify candidate prototypes that may represent new classes.
- Query-based Sampling: Finally, PNP uses a novel query-based sampling strategy to efficiently explore the data space and identify new prototype representations that can capture emerging classes.
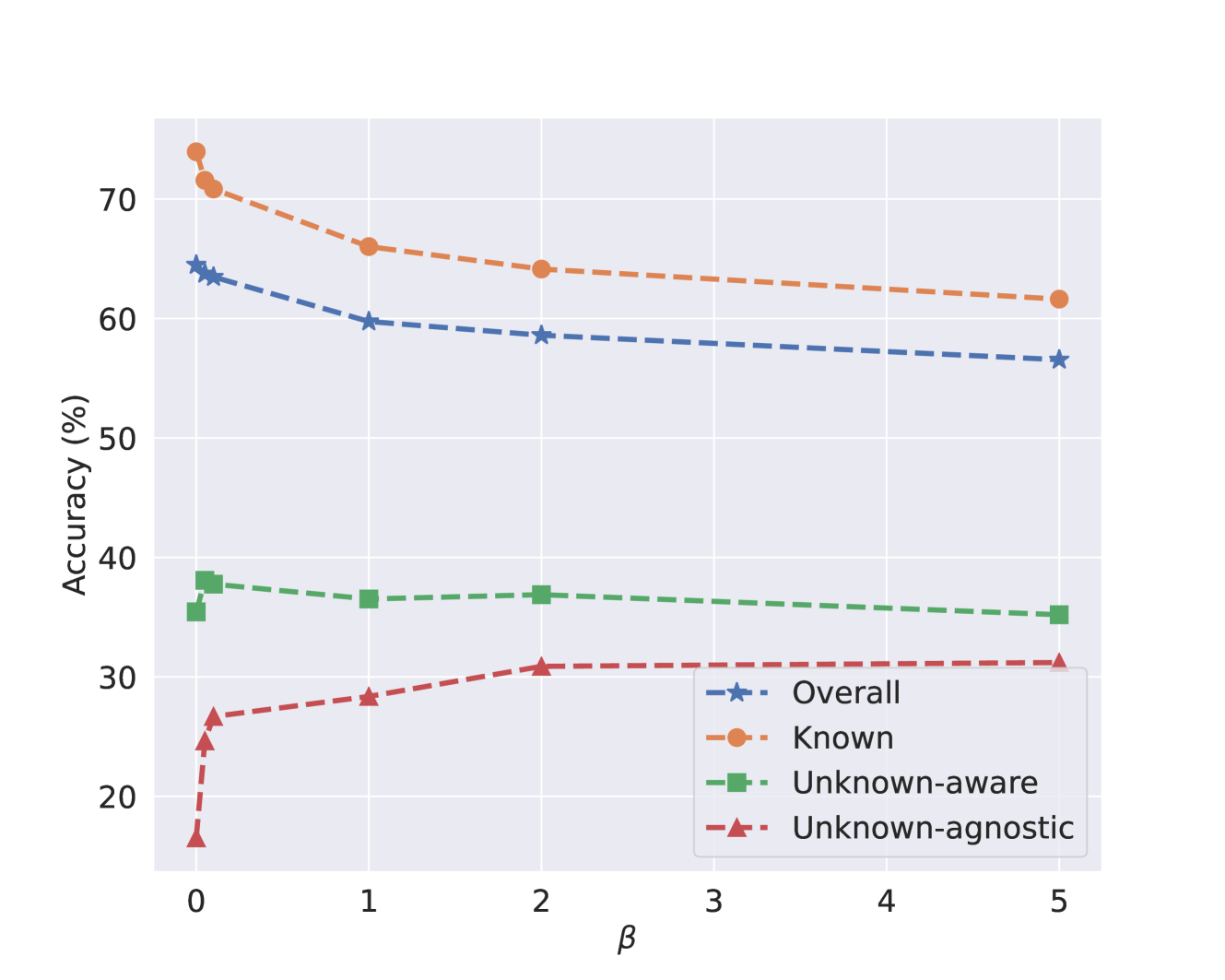
• The authors evaluate PNP on several generalized class discovery benchmarks and show that it outperforms existing state-of-the-art methods, demonstrating its ability to effectively discover new classes beyond known clusters.
Critical Analysis
• The paper provides a thoughtful critique of existing generalized class discovery methods that rely solely on clustering known class representations, acknowledging the limitations of this approach. • The proposed PNP method is well-designed and leverages a combination of powerful techniques, including contrastive learning, prototype-based clustering, and a novel query-based sampling strategy. • The experimental results demonstrate the effectiveness of PNP in discovering new classes, outperforming state-of-the-art methods like CDAD-Net and Contrastive Mean Shift. • However, the paper does not address potential limitations or caveats of the PNP method, such as its scalability, sensitivity to hyperparameters, or performance on datasets with a very large number of unknown classes.
Conclusion
• This research paper presents a novel approach called Probe New Prototypes (PNP) that aims to go beyond relying solely on known class clusters for generalized class discovery. • By leveraging contrastive learning, prototype-based clustering, and a novel query-based sampling strategy, PNP is able to efficiently identify new prototype representations that can capture emerging classes in the data. • The strong experimental results demonstrate the effectiveness of PNP and its potential to advance the field of generalized class discovery, which has important applications in areas like object recognition, anomaly detection, and open-ended learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Known Clusters: Probe New Prototypes for Efficient Generalized Class Discovery
Ye Wang, Yaxiong Wang, Yujiao Wu, Bingchen Zhao, Xueming Qian
Generalized Class Discovery (GCD) aims to dynamically assign labels to unlabelled data partially based on knowledge learned from labelled data, where the unlabelled data may come from known or novel classes. The prevailing approach generally involves clustering across all data and learning conceptions by prototypical contrastive learning. However, existing methods largely hinge on the performance of clustering algorithms and are thus subject to their inherent limitations. Firstly, the estimated cluster number is often smaller than the ground truth, making the existing methods suffer from the lack of prototypes for comprehensive conception learning. To address this issue, we propose an adaptive probing mechanism that introduces learnable potential prototypes to expand cluster prototypes (centers). As there is no ground truth for the potential prototype, we develop a self-supervised prototype learning framework to optimize the potential prototype in an end-to-end fashion. Secondly, clustering is computationally intensive, and the conventional strategy of clustering both labelled and unlabelled instances exacerbates this issue. To counteract this inefficiency, we opt to cluster only the unlabelled instances and subsequently expand the cluster prototypes with our introduced potential prototypes to fast explore novel classes. Despite the simplicity of our proposed method, extensive empirical analysis on a wide range of datasets confirms that our method consistently delivers state-of-the-art results. Specifically, our method surpasses the nearest competitor by a significant margin of 9.7% within the Stanford Cars dataset and 12x clustering efficiency within the Herbarium 19 dataset. We will make the code and checkpoints publicly available at https://github.com/xjtuYW/PNP.git.
Read more5/1/2024

0
Exploiting Fine-Grained Prototype Distribution for Boosting Unsupervised Class Incremental Learning
Jiaming Liu, Hongyuan Liu, Zhili Qin, Wei Han, Yulu Fan, Qinli Yang, Junming Shao
The dynamic nature of open-world scenarios has attracted more attention to class incremental learning (CIL). However, existing CIL methods typically presume the availability of complete ground-truth labels throughout the training process, an assumption rarely met in practical applications. Consequently, this paper explores a more challenging problem of unsupervised class incremental learning (UCIL). The essence of addressing this problem lies in effectively capturing comprehensive feature representations and discovering unknown novel classes. To achieve this, we first model the knowledge of class distribution by exploiting fine-grained prototypes. Subsequently, a granularity alignment technique is introduced to enhance the unsupervised class discovery. Additionally, we proposed a strategy to minimize overlap between novel and existing classes, thereby preserving historical knowledge and mitigating the phenomenon of catastrophic forgetting. Extensive experiments on the five datasets demonstrate that our approach significantly outperforms current state-of-the-art methods, indicating the effectiveness of the proposed method.
Read more8/20/2024
0
Generalized Categories Discovery for Long-tailed Recognition
Ziyun Li, Christoph Meinel, Haojin Yang
Generalized Class Discovery (GCD) plays a pivotal role in discerning both known and unknown categories from unlabeled datasets by harnessing the insights derived from a labeled set comprising recognized classes. A significant limitation in prevailing GCD methods is their presumption of an equitably distributed category occurrence in unlabeled data. Contrary to this assumption, visual classes in natural environments typically exhibit a long-tailed distribution, with known or prevalent categories surfacing more frequently than their rarer counterparts. Our research endeavors to bridge this disconnect by focusing on the long-tailed Generalized Category Discovery (Long-tailed GCD) paradigm, which echoes the innate imbalances of real-world unlabeled datasets. In response to the unique challenges posed by Long-tailed GCD, we present a robust methodology anchored in two strategic regularizations: (i) a reweighting mechanism that bolsters the prominence of less-represented, tail-end categories, and (ii) a class prior constraint that aligns with the anticipated class distribution. Comprehensive experiments reveal that our proposed method surpasses previous state-of-the-art GCD methods by achieving an improvement of approximately 6 - 9% on ImageNet100 and competitive performance on CIFAR100.
Read more8/27/2024
0
Generalized Category Discovery with Large Language Models in the Loop
Wenbin An, Wenkai Shi, Feng Tian, Haonan Lin, QianYing Wang, Yaqiang Wu, Mingxiang Cai, Luyan Wang, Yan Chen, Haiping Zhu, Ping Chen
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate the above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. Code and data are available at https://github.com/Lackel/LOOP.
Read more5/28/2024