GenderCARE: A Comprehensive Framework for Assessing and Reducing Gender Bias in Large Language Models

0

Sign in to get full access
Overview
- Comprehensive framework called GenderCARE for assessing and reducing gender bias in large language models
- Aims to provide a standardized approach for evaluating and mitigating bias
- Includes methods for measuring different types of gender bias and techniques for reducing bias
Plain English Explanation
Large language models, which are AI systems trained on vast amounts of text data, have been shown to exhibit various forms of gender bias. This means they may use language in ways that unfairly disadvantage or stereotype people based on their gender.
The GenderCARE framework offers a comprehensive approach to address this issue. It provides a set of tools and techniques for:
- Measuring different kinds of gender bias in language models, such as stereotyping certain occupations as more suitable for one gender
- Identifying the sources and drivers of this bias
- Developing strategies to reduce the bias
The goal is to give researchers and developers a standardized way to evaluate and mitigate gender bias, helping to make large language models more fair and inclusive. This could have important implications for a wide range of applications where these models are used, from healthcare to hiring.
Technical Explanation
The GenderCARE framework consists of four main components:
-
Comprehensive Bias Measurement: This involves using a variety of bias evaluation metrics to assess different types of gender bias, such as occupational bias, stereotype bias, and toxicity bias. The framework provides guidelines and tools for applying these metrics to language models.
-
Algorithmic Refinement: This component focuses on developing techniques to reduce gender bias in the language models themselves. This could involve fine-tuning the models on less biased data, applying debiasing algorithms, or modifying the model architecture.
-
Responsible Deployment: GenderCARE outlines strategies for responsibly deploying language models, such as providing transparency about their limitations and potential biases, and monitoring their real-world performance and impact.
-
Empirical Evaluation: The framework includes processes for empirically evaluating the effectiveness of the bias measurement and reduction techniques, using both automated metrics and human evaluations.
The paper demonstrates the application of the GenderCARE framework through a case study on the GPT-3 language model. The researchers use the framework's bias measurement tools to identify various forms of gender bias in GPT-3, and then experiment with different debiasing techniques to mitigate these biases.
Critical Analysis
The GenderCARE framework is a valuable contribution to the field of AI safety and algorithmic fairness. By providing a comprehensive and standardized approach, it aims to make it easier for researchers and developers to assess and address gender bias in large language models.
However, the paper acknowledges that the framework is not a panacea. Reducing gender bias in language models is a challenging task, and the paper notes that the proposed techniques may not fully eliminate all forms of bias. There is also a need for further research to better understand the complex relationships between model architecture, training data, and different types of bias.
Additionally, the framework focuses primarily on gender bias, but language models may exhibit other forms of bias, such as racial or socioeconomic bias, that require separate consideration. Extending the GenderCARE framework to address a broader range of biases could be an area for future work.
Conclusion
The GenderCARE framework represents an important step towards building more equitable and inclusive large language models. By providing a standardized approach for measuring and mitigating gender bias, it has the potential to significantly improve the fairness and real-world impact of these powerful AI systems. As the use of language models continues to expand across various domains, tools like GenderCARE will become increasingly crucial for ensuring that the benefits of these technologies are shared equitably among all members of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenderCARE: A Comprehensive Framework for Assessing and Reducing Gender Bias in Large Language Models
Kunsheng Tang, Wenbo Zhou, Jie Zhang, Aishan Liu, Gelei Deng, Shuai Li, Peigui Qi, Weiming Zhang, Tianwei Zhang, Nenghai Yu
Large language models (LLMs) have exhibited remarkable capabilities in natural language generation, but they have also been observed to magnify societal biases, particularly those related to gender. In response to this issue, several benchmarks have been proposed to assess gender bias in LLMs. However, these benchmarks often lack practical flexibility or inadvertently introduce biases. To address these shortcomings, we introduce GenderCARE, a comprehensive framework that encompasses innovative Criteria, bias Assessment, Reduction techniques, and Evaluation metrics for quantifying and mitigating gender bias in LLMs. To begin, we establish pioneering criteria for gender equality benchmarks, spanning dimensions such as inclusivity, diversity, explainability, objectivity, robustness, and realisticity. Guided by these criteria, we construct GenderPair, a novel pair-based benchmark designed to assess gender bias in LLMs comprehensively. Our benchmark provides standardized and realistic evaluations, including previously overlooked gender groups such as transgender and non-binary individuals. Furthermore, we develop effective debiasing techniques that incorporate counterfactual data augmentation and specialized fine-tuning strategies to reduce gender bias in LLMs without compromising their overall performance. Extensive experiments demonstrate a significant reduction in various gender bias benchmarks, with reductions peaking at over 90% and averaging above 35% across 17 different LLMs. Importantly, these reductions come with minimal variability in mainstream language tasks, remaining below 2%. By offering a realistic assessment and tailored reduction of gender biases, we hope that our GenderCARE can represent a significant step towards achieving fairness and equity in LLMs. More details are available at https://github.com/kstanghere/GenderCARE-ccs24.
Read more8/23/2024

0
JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Ze Wang, Zekun Wu, Xin Guan, Michael Thaler, Adriano Koshiyama, Skylar Lu, Sachin Beepath, Ediz Ertekin Jr., Maria Perez-Ortiz
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.
Read more6/26/2024

0
Leveraging Large Language Models to Measure Gender Bias in Gendered Languages
Erik Derner, Sara Sansalvador de la Fuente, Yoan Guti'errez, Paloma Moreda, Nuria Oliver
Gender bias in text corpora used in various natural language processing (NLP) contexts, such as for training large language models (LLMs), can lead to the perpetuation and amplification of societal inequalities. This is particularly pronounced in gendered languages like Spanish or French, where grammatical structures inherently encode gender, making the bias analysis more challenging. Existing methods designed for English are inadequate for this task due to the intrinsic linguistic differences between English and gendered languages. This paper introduces a novel methodology that leverages the contextual understanding capabilities of LLMs to quantitatively analyze gender representation in Spanish corpora. By utilizing LLMs to identify and classify gendered nouns and pronouns in relation to their reference to human entities, our approach provides a nuanced analysis of gender biases. We empirically validate our method on four widely-used benchmark datasets, uncovering significant gender disparities with a male-to-female ratio ranging from 4:1 to 6:1. These findings demonstrate the value of our methodology for bias quantification in gendered languages and suggest its application in NLP, contributing to the development of more equitable language technologies.
Read more6/21/2024
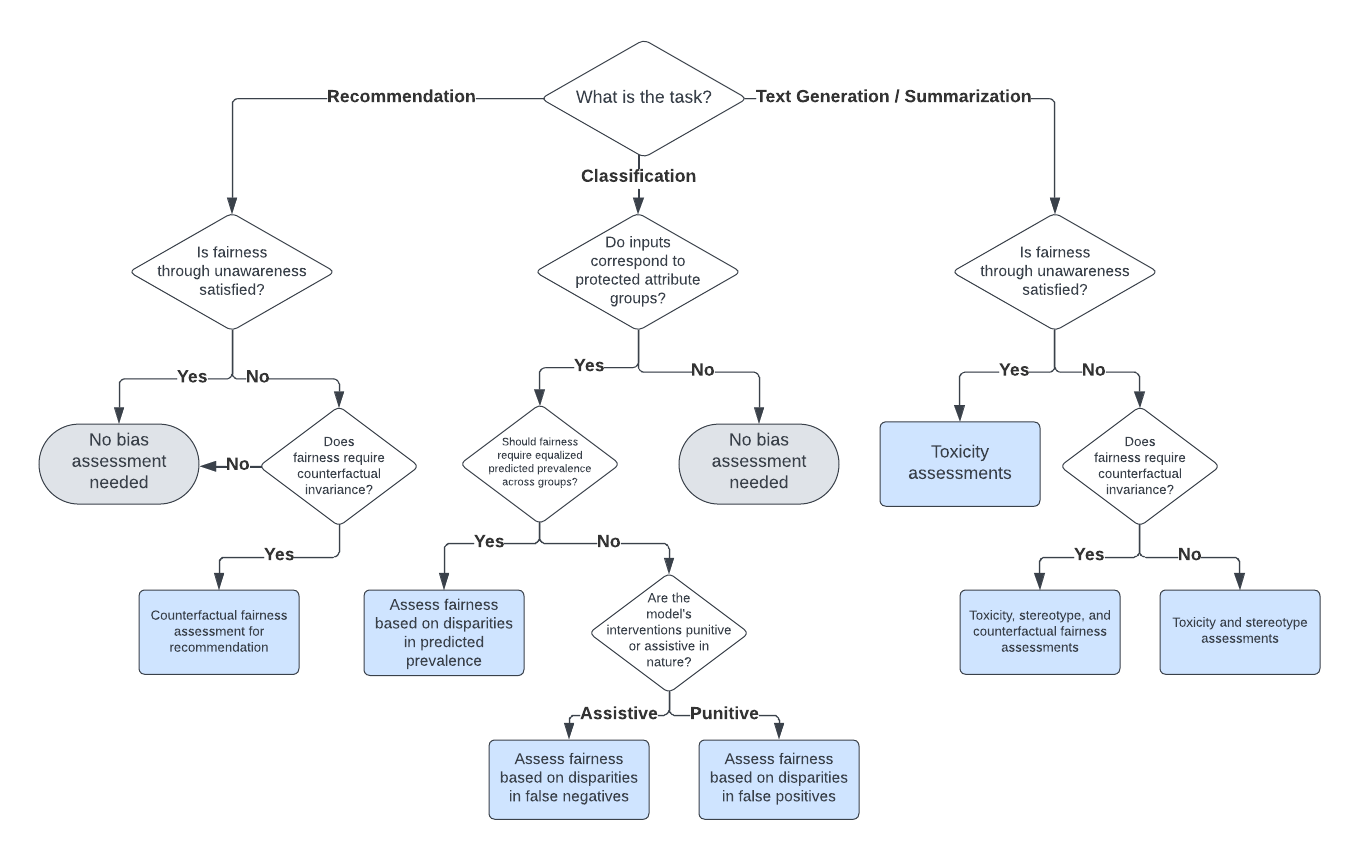
0
An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases
Dylan Bouchard
Large language models (LLMs) can exhibit bias in a variety of ways. Such biases can create or exacerbate unfair outcomes for certain groups within a protected attribute, including, but not limited to sex, race, sexual orientation, or age. This paper aims to provide a technical guide for practitioners to assess bias and fairness risks in LLM use cases. The main contribution of this work is a decision framework that allows practitioners to determine which metrics to use for a specific LLM use case. To achieve this, this study categorizes LLM bias and fairness risks, maps those risks to a taxonomy of LLM use cases, and then formally defines various metrics to assess each type of risk. As part of this work, several new bias and fairness metrics are introduced, including innovative counterfactual metrics as well as metrics based on stereotype classifiers. Instead of focusing solely on the model itself, the sensitivity of both prompt-risk and model-risk are taken into account by defining evaluations at the level of an LLM use case, characterized by a model and a population of prompts. Furthermore, because all of the evaluation metrics are calculated solely using the LLM output, the proposed framework is highly practical and easily actionable for practitioners.
Read more8/9/2024